CPC Definition - Subclass G06F
This place covers:
Electrical arrangements or processing means for the performance of any automated operation using empirical data in electronic form for classifying, analyzing, monitoring, or carrying out calculations on the data to produce a result or event.
This place does not cover:
Computer systems based on specific computational models |
Attention is drawn to the following places, which may be of interest for search:
Programme-control systems | |
Digital computers in which all the computation is effected mechanically | |
Computers in which a part of the computation is effected hydraulically or pneumatically | |
Computers in which a part of the computation is effected optically | |
Self-contained input or output peripheral equipment | |
Computer displays | |
Impedance networks using digital techniques |
In this place, the following terms or expressions are used with the meaning indicated:
Handling | includes processing or transporting of data. |
Data processing equipment | An association of an electric digital data processor classifiable under group G06F 7/00, with one or more arrangements classifiable under groups G06F 1/00- G06F 5/00 and G06F 9/00- G06F 13/00. |
This place covers:
Details not covered by groups G06F 3/00-G06F 13/00 and G06F 21/00.
This place does not cover:
Architectures of general purpose stored program computers |
Attention is drawn to the following places, which may be of interest for search:
Evaluating functions by calculating only | |
Generating sawtooth or staircase waveforms |
Attention is drawn to the following places, which may be of interest for search:
Generation of pulse trains in general |
This place covers:
Generation and/or distribution of clock signal(s) within a computer system.
This place covers:
Distribution of clock signal(s) within a computer system, in a typical case the goal to be achieved is to minimize the skew.
This place covers:
Clock distribution wherein the clock signal(s) are distributed entirely optically or partially optically and partially electrically.
Used also for hoods protecting displays of portable computers.
Used also for accessories attached on displays of portable computers.
This place covers:
Portable computers in the sense of computers able to be used as standalone computers with their own integrated user interface and designed to be carried by hand (e.g. hand held computers or laptop computers) or worn on the user's body (wearable computers).
Docking stations and extensions associated with the portable computers which may be mechanically attached to them.
This place does not cover:
Cooling arrangements for portable computers | |
Constructional details or arrangements for pocket calculators, electronic agendas or books | |
Constructional details of portable telephone sets: with several bodies |
Attention is drawn to the following places, which may be of interest for search:
Anti-theft locking devices | |
Constructional details of cameras | |
Hand held scanners | |
Personal calling arrangements, i.e. paging systems or devices, i.e. pagers | |
Casing of remote controls | |
Telephone sets including user guidance or feature selection means facilitating their use | |
Cordless telephones | |
Cameras or camera modules comprising electronic image sensors |
In this field, main mechanical aspects of the housing (single housing, foldable or sliding housings) are classified in G06F 1/1615 - G06F 1/1626, while all the other constructional details (enclosure details, display, keyboard, integrated peripherals, etc) are classified in G06F 1/1633 in complement to this main aspect.
In patent documents, the following words/expressions are often used as synonyms:
- "laptop", "palmtop" and "PDA"
- " cell phone", "mobile phone" and "smart phone"
This place covers:
Portable computers having a plurality of enclosures which can't be classified in anyone of the subgroups, e.g. multiple enclosure with loose mechanical link (single wire, expandable or/and flexible link, rollable part), computer split in several housings with no mechanical connection and wirelessly connected, complex mechanical link with multiple degrees of freedom.
Illustrative examples:
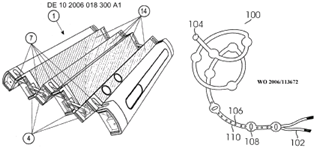
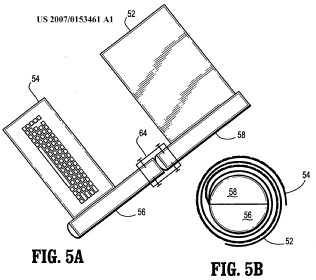
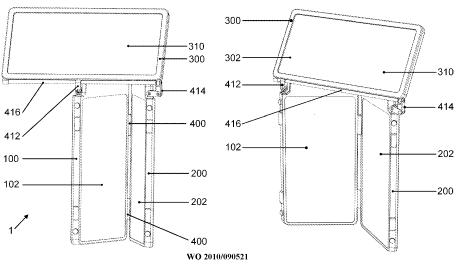
This place does not cover:
Constructional details of portable telephones comprising a plurality of mechanically joined movable body parts |
Attention is drawn to the following places, which may be of interest for search:
Foldable portable telephones |
This place covers:
Also when the hinging part is composed of two parallel rotation axes.
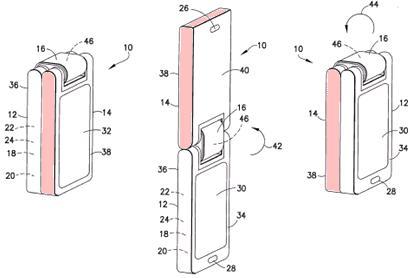
This place covers:
Reversing the orientation done either by rotating along the X or Y axis or by detaching the display and attaching it in the reverse orientation. Illustrative example:
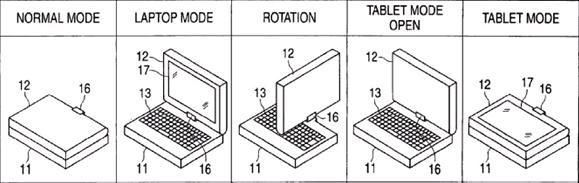
This place covers:
Illustrative examples of subject matter classified in this group:
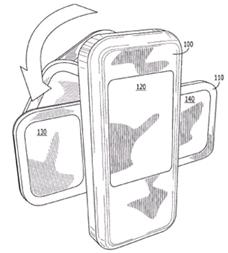
Additionally rotation around an axis common to the plane they define but perpendicular to their common side, e.g. reversing the relative orientation along an axis common to both planes but not along their sides (which would be then a folding axis).
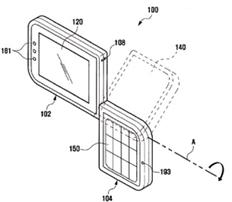
This place does not cover:
Reversing the face orientation of the screen of a folding flat display |
Attention is drawn to the following places, which may be of interest for search:
Rotatable portable telephones |
This place covers:
Portable computers linked by a mechanism allowing translation of one housing relatively to the other housing.
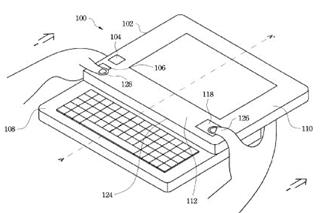
Attention is drawn to the following places, which may be of interest for search:
Slidable portable telephones |
This place covers:
Portable enclosures allowing the transport of the portable computer together with other peripherals.
Illustrative examples of subject matter classified in this place:
1.

2.

Figure 2 illustrates a portable system for carrying a monitor and a computing device in a case.
In the context of subclass A45C, storing is understood as to refer to putting or keeping something in a receptacle for future use.
Receptacles for storing portable audio devices, portable handheld communication devices or portable computing devices where the device must be removed for use are classified in A45C 11/001, A45C 11/002 and A45C 11/003, respectively.
Holders or carriers being worn by a user for portable audio devices, portable handheld communication devices and portable computing devices to facilitate transporting or carrying, where the device is not in use or being passively used, are classified in groups A45F 5/1508, A45F 5/1516 and A45F 5/1525, respectively.
Protective covers or auxiliary enclosures for mobile phones that are intended to hold the device during use without hampering the telephonic functions are classified in H04M 1/0203.
Constructional features, like venting or EMI shielding means, of electronic housings not characterised by the inner electronic arrangements are classified in H05K 5/00.
Attention is drawn to the following places, which may be of interest for search:
Protective covers or auxiliary enclosures for portable computers | |
Bags | |
Receptacles for storing portable computing devices, e.g. laptops, tablets or calculators | |
Holders or carriers for portable computing devices, e.g. laptops, tablets or calculators | |
Stands with or without wheels as supports for apparatus | |
Arrangements for carrying or protecting portable transceivers in general |
Enclosures for carrying portable computers with peripheral devices, like a printer or a charger, are classified in G06F 1/1628.
G06F 1/1629 relates to protective covers or auxiliary enclosures for portable computers that are intended to hold the device during use. Details related to functional adaptations of the enclosures, e.g. to provide protection against EMI, shock or water are identified by allocating further classification in G06F 1/1656 or subgroups.
This place covers:
Protective covers or auxiliary enclosures for portable computers that are intended to hold the device during use without hampering said use. The covers or enclosures for portable computers are in principle detachable but intended to remain on the computer during use.
Illustrative example of subject matter classified in this place:
1a.

1b.

1c.

Protective covers or auxiliary enclosures for portable computers that are intended to hold the device during use are classified in G06F 1/1629 while receptacles for storing portable audio devices, portable handheld communication devices or portable computing devices where the device must be removed for use are classified in A45C 11/001, A45C 11/002 and A45C 11/003, respectively.
In the context of subclass A45C, storing is understood as to refer to putting or keeping something in a receptacle for future use.
Holders or carriers being worn by a user for portable audio devices, portable handheld communication devices and portable computing devices to facilitate transporting or carrying, where the device is not in use or being passively used, are classified in groups A45F 5/1508, A45F 5/1516 and A45F 5/1525, respectively.
Protective covers or auxiliary enclosures for mobile phones that are intended to hold the device during use without hampering the telephonic functions are classified in H04M 1/0203.
Constructional features, like venting or EMI shielding means, of electronic housings not characterised by the inner electronic arrangements are classified in H05K 5/00.
Supports for positioning or steadying a device relative to a person with the intent of using the device are classified in F16M 13/04.
This place does not cover:
Enclosures for carrying portable computers with peripheral devices | |
Receptacles for storing portable computing devices, e.g. laptops, tablets or calculators |
Attention is drawn to the following places, which may be of interest for search:
Receptacles for storing portable audio devices like headphones or digital music players | |
Receptacles for storing portable handheld communication devices, e.g. pagers or smart phones | |
Holders or carriers for portable audio devices | |
Holders or carriers for portable handheld communication devices | |
Holders or carriers for portable computing devices | |
Supports for positioning or steadying a device relative to a person | |
Arrangements for carrying or protecting portable transceivers | |
Protective covers or auxiliary enclosures for portable telephones | |
Casings, cabinets or drawers for electric apparatus |
Enclosures for carrying portable computers with peripheral devices, like a printer or a charger, are classified in G06F 1/1628.
Details related to functional adaptations of the enclosures, e.g. to provide protection against EMI, shock or water are identified by allocating further classification in G06F 1/1656 or subgroups.
This place covers:
Portable computers, e.g. smart watches, whereby the portable computer itself is worn by a user.
Carrying devices like bands or straps worn on the user to which a computer is attached for facilitating transport or carrying when the computer is not in use or being passively used, e.g. belt clip with means for retaining a tablet, the tablet being removed from the belt clip for use, is classified in A45F 5/1525.
Attention is drawn to the following places, which may be of interest for search:
Garments adapted to accommodate electronic equipment | |
Fastening articles to garments | |
Holders or carriers for portable computing devices, e.g. laptops, tablets or calculators |
This place covers:
Expansions which are directly attached to portable computers, including supplementary battery packs external to the housing, port replicators and cradles for PDAs.
This place does not cover:
Standard wired or wireless peripherals such as keyboards, printers or displays which are not mechanically linked to a portable computer |
Attention is drawn to the following places, which may be of interest for search:
Mounting in a car | |
Locking against unauthorized removal | |
Battery charging cradles | |
PCMCIA cards |
In patent documents, the following words/expressions are often used as synonyms:
- "docking station", "cradle" and "port replicator"
Attention is drawn to the following places, which may be of interest for search:
Constructional details or arrangements of portable computers specific to the type of enclosures | |
Mounting of specific components of portable telephones |
Attention is drawn to the following places, which may be of interest for search:
Computer power supply in general | |
Details of mounting batteries in general | |
Portable telephones battery compartments |
Attention is drawn to the following places, which may be of interest for search:
Constructional details related to the housing of computer displays in general | |
Accessories mechanically attached to the display housing portion of portable computers | |
Portable telephones display |
This place does not cover:
Including at least an additional display |
Should be used when the displays are used in combination as a virtual single display area where the displayed image is split over the display screens.
This place does not cover:
Movement typologies |
Attention is drawn to the following places, which may be of interest for search:
Touchpads integrated in a laptop or similar computer | |
Secondary touch screen |
This place does not cover:
Constructional details or arrangements related to integrated I/O peripheral being a secondary touch screen used as control interface, e.g. virtual buttons or sliders |
This place covers:
Typically very small displays disposed on the back of the main display for indicating time, alerts or battery level or small status displays near the hinge above the keyboard. Illustrative examples:
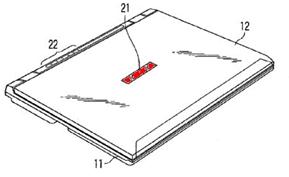
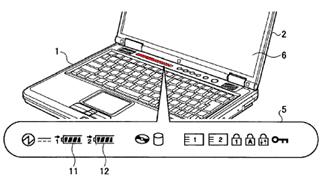
Attention is drawn to the following places, which may be of interest for search:
Portable telephones flexible display |
This place does not cover:
Arrangements to protect the display from incident light, e.g. hoods | |
Arrangements to support accessories mechanically attached to the display housing | |
Enclosure details of non-portable computers | |
Cooling arrangements for portable computers |
Attention is drawn to the following places, which may be of interest for search:
Protective covers or auxiliary enclosures for portable computers | |
Protective covers or auxiliary enclosures for portable telephones | |
Portable telephones with mechanically detachable modules |
This place does not cover:
Internal mounting structures of non portable computers |
Attention is drawn to the following places, which may be of interest for search:
Details of stand alone keyboards | |
Constructional details of keyboard switches | |
Portable telephones keypads |
Attention is drawn to the following places, which may be of interest for search:
Digitisers | |
Interaction with virtual keyboards displayed on a touch sensitive surface |
Attention is drawn to the following places, which may be of interest for search:
Movement typologies | |
Relative motion of the body parts to change the operational status of the portable telephone |
Attention is drawn to the following places, which may be of interest for search:
Portable telephones open/close detection |
This place does not cover:
Hinge details related to the transmission of signals or power |
Attention is drawn to the following places, which may be of interest for search:
Hinges for doors, windows or wings | |
Portable telephones hinge details |
This place covers:
Also optical transmission of data or inductive transmission of power between housings.
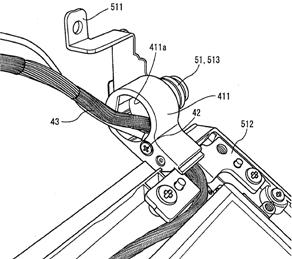
Attention is drawn to the following places, which may be of interest for search:
Camera details of portable telephones |
This place does not cover:
Touchscreens | |
Constructional details of pointing devices |
Attention is drawn to the following places, which may be of interest for search:
Joysticks in general | |
Constructional details of pointing devices in portable telephones |
This place covers:
Secondary touchscreens which are used only as input device (touchpad, virtual input devices), and not for information display.
Attention is drawn to the following places, which may be of interest for search:
Gestural input | |
Motion sensing in space for computer input |
This place covers:
Scanners for e.g. A4 sheets.
This place does not cover:
Barcode readers |
Attention is drawn to the following places, which may be of interest for search:
Scanners | |
Printers |
This place does not cover:
details of antennas disposed inside a computer | |
Interaction of portable devices with video on demand or television systems |
Attention is drawn to the following places, which may be of interest for search:
Aerials | |
Cordless telephones |
This place covers:
Cases and housing for computers and how computer components are "packed" , i.e. mounted within the housing . It also covers arrangements, e.g. cabling, to distribute the power generated by the power supply unit to the other computer components mounted within the casing.
This place covers:
Enclosures for computers, including constructional details of front or bezel.
This place does not cover:
Enclosures for portable computers |
Attention is drawn to the following places, which may be of interest for search:
Enclosures for electrical apparatuses in general |
This place covers:
Enclosures for non-standard computers, e.g. industrial computers, computers specifically adapted to special environments.
Attention is drawn to the following places, which may be of interest for search:
Shielding against electromagnetic interference in general |
This place covers:
Mounting structures for securing and/or interconnecting among them internal components within the enclosure of a computer system.
This place does not cover:
Internal connecting means for buses |
Attention is drawn to the following places, which may be of interest for search:
Mounting structures for printed circuits in general |
Attention is drawn to the following places, which may be of interest for search:
Housings for circuits carrying a CPU and adapted to receive expansion cards |
Attention is drawn to the following places, which may be of interest for search:
Mounting of expansion boards in general |
Used for the securing of expansion cards completely within the enclosure, and not to the connection to openings in the enclosure.
Attention is drawn to the following places, which may be of interest for search:
Securing of expansion boards in general |
Used for to the connection of expansion boards to openings in the enclosure so that at least a portion, or connector, of the expansion board is accessible from outside the enclosure.
Attention is drawn to the following places, which may be of interest for search:
Constructional details of disk drives housings in general |
Used for both optical drives and hard disk drives.
Attention is drawn to the following places, which may be of interest for search:
Power supply for computers |
This groups refers also to documents wherein the thermal management is achieved by lowering power consumption in order to reduce heat generation..
Documents also disclosing costructional details about the managed cooling arrangement should be also classified in G06F 1/20 if describing the cooling of a desktop computer or G06F 1/203 if describing the cooling of a portable computer.
Attention is drawn to the following places, which may be of interest for search:
Microprogramme loading | |
Restoration from data faults |
This place covers:
Power supplies for computers including:
- Power regulation;
- Power monitoring including means for acting in the event of power supply fluctuations or interruption;
- Power save.
This place does not cover:
Power supplies for memories |
Attention is drawn to the following places, which may be of interest for search:
Systems for regulating electric or magnetic variables |
This place covers:
Arrangements with switchable, multiple power supplies (typical example is AC and battery, but may also include multiple batteries, fuel cells or solar panels).
This place does not cover:
Means for acting in the event of power-supply failure or interruption, e.g. power-supply fluctuations |
This place covers:
Arrangements to supply power to external peripherals, either directly from the computer or under computer control (typical cases are the supply of power through a USB interface and the power strips).
This place covers:
Arrangements to monitor, and only monitoring, power supply parameters (e.g. voltage and/or current).
This place does not cover:
Means for acting in the event of power-supply failure or interruption, e.g. power-supply fluctuations |
This place does not cover:
For resetting only |
Attention is drawn to the following places, which may be of interest for search:
Involving the processing of data-words |
This place covers:
Means to save power in computers, including devices, methods and combinations of devices and method features.
This place covers:
Power saving obtained by switching, in relation to events of any type, between computing device operating modalities implying different power consumption levels. As opposed to power saving arrangements and/or methods of a permanent or continuous nature.
This place covers:
Power saving triggered by a certain event and/or condition detected by monitoring or supervision of e.g. hardware, communication, processing tasks.
Used when the peripheral monitored does not belong to any of the subgroups: G06F 1/3218, G06F 1/3221 or G06F 1/3225.
This place covers:
Power saving initiated when a task completion is detected (typical cases are the completion of processing tasks, e.g. programs, applications, routines).
This place covers:
Power saving initiated when the user absence/presence is detected, e.g. through a camera and/or sensors.
This group is not to be used when the user absence/presence is inferred by a user inactivity period, e.g. absence of keyboard input. Subgroups referring to monitoring of peripheral devices to be used in such cases, i.e. G06F 1/3215 and subgroups.
This place covers:
Power saving obtained by selectively reducing power consumption of all or individual components of a computing system. Such reduction can be achieved in different ways, e.g. by lowering the clock frequency, by stopping the supply of the clock signal, by lowering the voltage, by stopping the supply of power, by task scheduling.
This place covers:
Power saving by stopping clock generation or distribution to a computer or a component.
This place covers:
Power saving taking place in the processing unit of the computer, intended as central processing unit (CPU), microcontroller unit (MCU), microprocessor.
This place covers:
Power saving in optical (or magneto-optical) disk drives, e.g. CD, DVD, Blue-Ray, etc.
This place does not cover:
Power saving in storage systems (e.g. not in disk drives within a computer system) |
This place covers:
Power saving by selectively reducing power consumption of individual components of a computer system. Such reduction can be achieved in different ways, e.g. by lowering the clock frequency or stopping the clock, by lowering the voltage, by stopping the power supply (power gating).
Attention is drawn to the following places, which may be of interest for search:
This place covers:
Includes inter alia arrangements in which a barcode reader is used to input data to a computer and in particular drivers for barcode or QR code readers.
Recognition of data; presentation of data; record carriers; handling record carriers: G06K.
This place does not cover:
Specific input/output arrangements | |
Other optical apparatus |
Attention is drawn to the following places, which may be of interest for search:
Viewers photographic printing | |
Electrography, magnetography | |
Constructional details of barcode readers | |
Reading of RFID record carriers | |
Constructional details of RFID record carriers | |
Use of barcode readers or RFIDs in data processing systems for business applications | |
Wireless phone using NFC or a two-way short-range wireless interface | |
Facsimile per se |
In this place, the following terms or expressions are used with the meaning indicated:
TUI | a user interface in which a person interacts with digital information through a physical environment, i.e. by manipulating physical objects (e.g. in the same way as moving pieces of a game on a tablet), often using RFID or NFC. |
In patent documents, the following abbreviations are often used:
TUI | Tangible User Interface |
RFID | Radio-Frequency Identification |
NFC | Near Field Communication |
This place covers:
Specific arrangements for input through a video camera, not covered by G06F 3/01 - G06F 3/16, e.g. details of the interface linking the camera to the computer.
This group was originally meant for devices adapting analog video cameras to computer entry.
Attention is drawn to the following places, which may be of interest for search:
Tracking user body for computer input | |
Pointing device integrating a camera for tracking its own position with respect to an imaged reference surface or the surroundings | |
Tracking a projected light spot generated by a light pen or a "laser pointer" indicating a position on a display surface | |
Digitisers using a camera for tracking the position of objects with respect to an imaged reference surface | |
Recognising movements or behaviour, e.g. recognition of gestures, dynamic facial expressions; Lip-reading | |
Television cameras |
Attention is drawn to the following places, which may be of interest for search:
Digital input from, or digital output to, record carriers | |
Digital stores in which the information is moved stepwise using magnetic elements and thin films in plane structure | |
Digital stores in which the information is moved stepwise using semiconductor elements | |
Organisation of a multiplicity of shift registers |
Old technology, not used anymore.
This place covers:
Input arrangements, or combined input and output arrangements, for interaction between user and computer.
Particularly, said input arrangements include those based on the interaction with the human body, e.g.
- gloves for hand or finger tracking;
- eye or head trackers;
- devices using bioelectric signals, e.g. detecting nervous activity;
- arrangements for providing computer generated force feedback in input devices.
This place does not cover:
Sound input, sound output including multimode user input, i.e. combining audio input (e.g. voice input) with other user input |
Attention is drawn to the following places, which may be of interest for search:
Interaction techniques based on graphical user interfaces [GUI] |
Diagnosis; surgery; identification: A61B
Recognition of data; presentation of data; record carriers; handling record carriers: G06K
This place does not cover:
Blind teaching |
Attention is drawn to the following places, which may be of interest for search:
Measuring of parameters or motion of the human body or parts thereof for diagnostic purposes | |
For handicapped people in general | |
Games using an electronically generated display and player-operated input means | |
Robot control | |
Stereoscopic optical systems | |
Recognising human body or animal bodies | |
Acquiring or recognising human faces, facial parts, facial sketches, facial expressions | |
Tactile signalling | |
Virtual reality arrangements for interacting with music, including those with tactile feedback | |
For electrophonic musical instruments | |
Electronic switches characterised by the way in which the control signals are generated |
This place covers:
For the scope of this group, Head-tracking is interpreted as covering face detection and tracking.
Attention is drawn to the following places, which may be of interest for search:
Head-tracking for image generation in head-mounted display | |
Use of head-tracking for image generation | |
3D image generation in augmented reality | |
Using viewer tracking |
In patent documents, the following abbreviations are often used:
HMD | Head-Mounted Display |
This place does not cover:
Input arrangements based on nervous system activity detection |
Attention is drawn to the following places, which may be of interest for search:
Apparatus for testing the eyes and instruments for examining the eyes | |
Instruments for determining or recording eye movement | |
Acquiring or recognising eyes |
In patent documents, the following words/expressions are often used as synonyms:
- "eye tracking" and "gaze tracking"
This place covers:
Also covers hand-worn keyboards
Manipulators; chambers provided with manipulation devices: B25J
Attention is drawn to the following places, which may be of interest for search:
Finger worn arrangements for converting the position or the displacement of a member into a coded form |
In this place, the following terms or expressions are used with the meaning indicated:
Data glove (sometimes called a "wired glove" or "cyberglove") | an input device for human–computer interaction worn like a glove |
Attention is drawn to the following places, which may be of interest for search:
Detecting bioelectric signals for diagnostic purpose | |
Bioelectrical control, e.g. myoelectric |
This place covers:
Dynamic force or tactile feedback arrangements. Also passive feedback arrangements but only if they are dynamically reconfigurable under computer control, e.g. buttons raised from a touchpad surface using electronic muscle or similar.
- Manipulators; chambers provided with manipulation devices: B25J
- Conjoint control of vehicle sub-units of different type or different function; control systems specially adapted for hybrid vehicles; road vehicle drive control systems for purposes not related to the control of a particular sub-unit: B60W
- Systems acting by means of fluids; fluid-pressure actuators, e.g. servo-motors: F15B
- Control or regulating systems in general: G05B
- Mechanical control devices: G05G
Attention is drawn to the following places, which may be of interest for search:
Passive (and non reconfigurable) feedback arrangements on a touchscreen, e.g. overlays with reliefs for indicating keys of a virtual keyboard | |
Hand grip control means for manipulators | |
Tactile feedback for vehicle driver | |
Servo-motor systems giving the operating person a "feeling" of the response of the actuated device | |
Means for enhancing the operator's awareness of arrival of the controlling member (knob, handle) at a command or datum position; Providing feel, e.g. means for creating a counterforce | |
Tactile presentation of information, e.g. Braille display | |
Keyboards characterised by tactile feedback features | |
Piezoelectric actuators |
This place covers:
Gesture interaction as a sequence and/ or a combination of user movements captured using various sensing techniques such as (among others) cameras monitoring the user, arrangements for interaction with the human body, input by means of a device moved freely in 3D space or opto-electronic detection arrangements.
This place does not cover:
Gestures made on the surface of a digitiser and/or in close proximity to this surface for digitisers capable of touchless position sensing and/or measuring also the distance in the Z direction |
Attention is drawn to the following places, which may be of interest for search:
Arrangements for interaction with the human body | |
Detection arrangements using opto-electronic means | |
Input by means of (pointing) device or object moved freely in 3D space | |
Acquiring or recognising (static) human faces, facial parts, facial sketches, facial expressions | |
Recognising movements or behaviour, e.g. recognition of gestures, dynamic facial expressions; Lip-reading | |
Lip-reading assisted speech recognition |
Handling natural language data: G06F 40/00
Attention is drawn to the following places, which may be of interest for search:
Inputting characters | |
Handling non-Latin characters, e.g. kana-to-kanji conversion | |
Processing of non-Latin text |
This place covers:
Input arrangements using manually operated switches, e.g. using keyboards or dials, insofar as they are stand-alone devices or integrated in a fixed computer system. Includes wired or wireless keyboards which are not mechanically linked to a portable computer.
Attention is drawn to the following places, which may be of interest for search:
Details related to integrated keyboard of portable computers | |
Keyboard switches per se | |
Electronic switches characterised by the way in which the control signals are generated |
Attention is drawn to the following places, which may be of interest for search:
Special layout of keys | |
Palm(wrist)-rests not integrated in the keyboard | |
Wrist worn wrist rests | |
Document holders for typewriters | |
Input/Output devices for watches | |
Details of keys/push buttons | |
Switches having rectilinearly-movable operating part or parts | |
Constructional details of keyboards having such switches | |
Electronic switching or gating i.e. not by contact-making or -braking | |
Proximity switches | |
Touch switches with electronic switching | |
Capacitive touch switches | |
Force resistance transducer | |
Optical touch switches | |
Piezoelectric touch switches | |
Resistive touch switches | |
Keyboard, i.e. having a plurality of control members, with electronic switching | |
With optoelectronic devices | |
With magnetic movable elements | |
With capacitive movable elements |
In patent documents, the following abbreviations are often used:
RSI | Repetitive Stress Injuries |
Attention is drawn to the following places, which may be of interest for search:
Integration of a mini joystick in a portable computer | |
Integration of a mini joystick in a keyboard | |
Details of the interface with a computer | |
Joysticks with a pivotable rigid stick |
This place does not cover:
Adjusting the tilt angle of the integrated keyboard in a mobile computer |
Attention is drawn to the following places, which may be of interest for search:
Constructional details of barcode readers |
This place does not cover:
Integration of a mini joystick in a portable computer | |
Constructional details of pointing devices | |
Joysticks with a pivotable rigid stick |
This place does not cover:
For keyboards integrated in a laptop computer |
This place covers:
Any keyboard designed or modified to control a specific software application or specific hardware, e.g. by integrating dedicated keys. Key layouts in alternative to the QWERTY standard are also classified in this group.
Attention is drawn to the following places, which may be of interest for search:
Devices for teaching typing |
This place does not cover:
Arrangements for reducing the size of the integrated keyboard in a portable computer | |
Arrangements for ergonomically adjusting the disposition of keys of a keyboard |
Attention is drawn to the following places, which may be of interest for search:
Document holders for typewriters |
This place covers:
Input arrangements using manually operated switches, e.g. using keyboards or dials, further comprising cooperation and interconnection of the input arrangement with other functional units of a computer.
This place does not cover:
Arrangements for converting discrete items of information into a coded form. Arrangements for converting the position or the displacement of a member into a coded form |
Attention is drawn to the following places, which may be of interest for search:
Keyboards integrating additional peripherals | |
Arrangements for converting the position or the displacement of a member into a coded form |
This place covers:
Keyboard interfaces and drivers; peripherals emulating a keyboard (e.g. producing "keystroke input" signals); devices providing additional buttons or foot operated switches and connected between keyboard and PC.
Also comprises KVM switches.
Attention is drawn to the following places, which may be of interest for search:
Virtual keyboards displayed on a touchscreen | |
Coding in connection with keyboards, i.e. coding of the position of operated keys |
In this place, the following terms or expressions are used with the meaning indicated:
KVM | a KVM switch allows a user to control one or multiple computer(s) from one or multiple KVM device(s) |
In patent documents, the following abbreviations are often used:
KVM | Keyboard, Video, Mouse |
This place covers:
Constructional details related to the wireless link, e.g. position of the IR transmitter/receiver as well as protocol details for the wireless transmission of keyboard codes.
Attention is drawn to the following places, which may be of interest for search:
Means for saving power, monitoring of peripheral devices | |
Information transfer between I/O devices and CPU, e.g. on bus |
In this place, the following terms or expressions are used with the meaning indicated:
Cordless keyboards | wireless keyboards; they are also often called according to the technology used: infrared keyboard, radio keyboard, WLAN keyboard, Bluetooth® keyboard |
This place covers:
Character input using a reduced number of keys, e.g. with respect to the alphabet, i.e. multivalued keys. Covers character input methods wherein a character is entered by tracing it on a matrix of switches (keys). Covers character input methods where a character is entered as a sequence of strokes on different keys or on a same key.
Attention is drawn to the following places, which may be of interest for search:
Interaction with virtual keyboards displayed on a touchscreen |
This place covers:
Keyboards or keypads having keys that can be operated not only vertically but also laterally to actuated separate switches associated to different key codes.
Attention is drawn to the following places, which may be of interest for search:
Character input using (e.g. 2 or 4 or 8) directional cursor keys for selecting characters in cooperation with displayed information |
This place covers:
Chord keyboards even if they are split in two or more parts, i.e. the predominant feature is the fact that chording is required to enter a character.
This place does not cover:
Character input using switches operable in different directions |
In this place, the following terms or expressions are used with the meaning indicated:
Chord | only an almost simultaneous depression of several keys |
Attention is drawn to the following places, which may be of interest for search:
Selecting from displayed items by using keys for other purposes than character input |
This place covers:
Character input using retrieval techniques from a database or dictionary based on previously inputted characters, e.g. for predicting and proposing word completion alternatives.
Covers inter alia T9, iTap and similar techniques.
Attention is drawn to the following places, which may be of interest for search:
Converting codes to words or guess-ahead of partial word inputs |
In this place, the following terms or expressions are used with the meaning indicated:
T9 (stands for Text on 9 keys) | a predictive text input technology for mobile phones, developed by Tegic Communications |
iTap | a predictive text technology for mobile phones, developed by Motorola |
This place covers:
Any keyboard in which the function assigned to all or some of the keys can be reprogrammed, e.g. changing alphabetical keys according to language, programming dedicated function keys.
This place does not cover:
Key guide holders |
Attention is drawn to the following places, which may be of interest for search:
Virtual keyboards on a touchscreen | |
Scrambling keyboard with display keys in electronically operated locks | |
Scrambling keyboard in electronically banking systems (POS,ATM) | |
Display on the key tops of musical instruments: | |
Switches with programmable display | |
Display on the key tops in general | |
Telephone set with programmable function keys |
Attention is drawn to the following places, which may be of interest for search:
Display of decimal point | |
Complete desk- top or hand- held calculators |
This place covers:
This group is used only for "exotic" input devices corresponding to the wording of the definition and not fitting in any of the subgroups, for example arrangements detecting the position or the displacement of tangible user interfaces comprising RFIDs tags or bar codes interacting with a surface (such as chessboard-like surface) where the position detection technique is not covered by any of the subgroups of G06F 3/03.
Example:
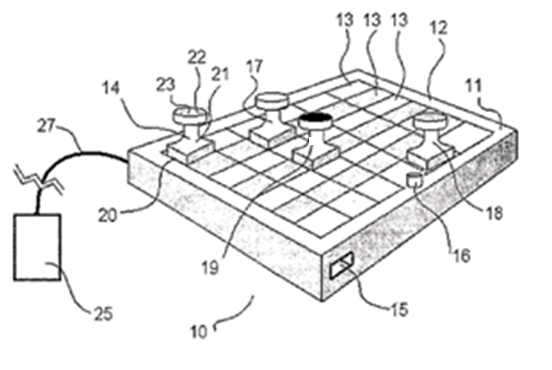
Attention is drawn to the following places, which may be of interest for search:
Interaction with a tangible user interface other than detecting its location or displacement | |
Electronic game devices per se | |
Coordinate identification of nuclear particle tracks | |
Telemetry of coordinates |
In this place, the following terms or expressions are used with the meaning indicated:
A Tangible User Interface (TUI) | a user interface in which a person interacts with digital information through a physical environment, i.e. by manipulating physical objects (e.g. in the same way as moving pieces of a game on a tablet), often using RFID or NFC |
In patent documents, the following abbreviations are often used:
TUI | Tangible User Interface |
RFID | Radio-Frequency IDentification |
NFC | Near Field Communication |
If the moving part is the sensor then the subject-matter belongs to G06F 3/0304, if the observed target (e.g. finger) is moving then the subject-matter belongs to G06F 3/042.
This place does not cover:
Constructional details of pointing devices not related to the detection arrangement using opto-electronic means | |
Digitisers using opto-electronic means |
Attention is drawn to the following places, which may be of interest for search:
Systems where the position detection is based on the raster scan of a cathode-ray tube (CRT) with a light pen | |
Measuring arrangements characterised by the use of optical means | |
Optical encoders | |
Position fixing using optical waves | |
Prospecting or detecting by optical means | |
Static switches using electro-optical elements in general | |
Optical switches | |
Optical touch switches |
Attention is drawn to the following places, which may be of interest for search:
Thumb wheel switches |
This place covers:
Tracking relative movement in co-operation with a regularly or irregularly patterned surface, e.g. arrangements for detecting relative movement of an optical mouse with respect to a generic surface optically detected as irregularly patterned (table, desk top, ordinary mouse pad) or with respect to a surface (e.g. mouse pad) encoded with an optically detectable regular pattern.
Arrangements for detecting absolute position of a member with respect to a regularly patterned surface, e.g. pen optically detecting position-indicative tags printed on a paper sheet.
This place does not cover:
Digitisers characterised by the transducing means |
Attention is drawn to the following places, which may be of interest for search:
Details of optical sensing in input devices | |
Arrangement for interfacing a joystick to a computer | |
Constructional details of joysticks |
For finger worn pointing devices covered by this group and its subgroups add the Indexing Code G06F 2203/0331.
In patent documents, the following abbreviations are often used:
RSI | Repetitive Stress Injury |
Attention is drawn to the following places, which may be of interest for search:
Integration of a mini joystick in a portable computer | |
Integration of a mini joystick in a keyboard | |
Sliders, in which the moving part moves in a plane | |
Details of the interface with a computer | |
Joysticks with a pivotable rigid stick | |
Switches with generally flat operating part depressible at different locations |
This place covers:
Devices sensing their own position or orientation in a three dimensional space, allowing thereby the user to input up to 6 coordinates (position + orientation) by moving the device. Covers inter alia 3D mice.
Remote control based on movements G08C.
Attention is drawn to the following places, which may be of interest for search:
3D input gestures | |
Input devices using opto-electronic sensing |
This place covers:
Pens detecting the presence of light on one point (such as a CRT scanning beam).
Light emitting pens positioned in contact or proximity of the pointed position.
Attention is drawn to the following places, which may be of interest for search:
Pens comprising an optical sensor for 1 or 2 dimensional position detection | |
Light emitting pointers per se used for marking with a light spot the pointed position from a distance |
This place does not cover:
Mouse/trackball convertible-type devices, in which the same ball is used to track the 2-dimensional relative movement |
Specific Indexing Codes G06F 2203/0332 - G06F 2203/0337 are associated to this group for some constructional details.
This place covers:
Pens other than optically sensing pens or light pens (e.g. for use in combination with a digitiser). Constructional details of pens in general irrespectively of the interaction technology.
Pens used for handwriting recognition:G06V 30/1423, G06V 10/12.
This place does not cover:
Details of optically sensing pens | |
Light pens |
This place covers:
Touch surface for sensing the relative motion of a finger over the surface.
Attention is drawn to the following places, which may be of interest for search:
Digitisers |
Specific Indexing Codes G06F 2203/0338 and G06F 2203/0339 are associated to this group for some constructional details.
This place does not cover:
Mouse/trackball convertible-type devices, in which the same ball is used to track the 2-dimensional relative movement |
Attention is drawn to the following places, which may be of interest for search:
Input arrangements for vehicle instruments | |
Incremental encoders | |
Sliding switches | |
Rotary encoding wheels -"thumb-wheel switches" |
Attention is drawn to the following places, which may be of interest for search:
Control circuits or drivers for touchscreens or digitisers | |
Graphical user interfaces (GUI) in general | |
Pointing device drivers modified to control cursor appearance or behaviour taking into account the presence of displayed objects |
This place covers:
Tracking a projected light spot generated by a light pen or a "laser pointer" indicating a position on a display surface, drivers for light pen systems.
Attention is drawn to the following places, which may be of interest for search:
Light emitting pointers per se used for marking with a light spot the pointed position from a distance | |
Light emitting pens positioned in contact or proximity of the pointed position | |
Light pen using the raster scan of a CRT |
Attention is drawn to the following places, which may be of interest for search:
Furniture aspects | |
Platforms for supporting wrists as table extension |
This place covers:
For example:
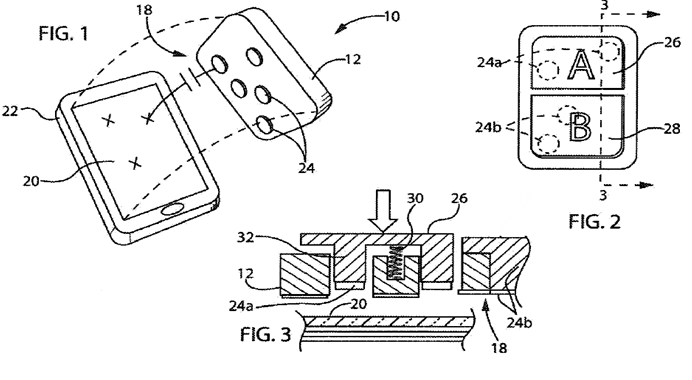
This place covers:
Position sensing of movable objects such as fingers or pens in contact with a surface or within a relative small distance to this surface (hovering).
Attention is drawn to the following places, which may be of interest for search:
Touchscreens integrated in a portable computer | |
Integration of touchpad in a portable computer (laptop, PDA) | |
3D input gestures | |
Integration of touchpad in a keyboard | |
True 3D computer input devices with a freely movable member | |
Pens for interaction between user and computer | |
Constructional details of touchpads | |
Accessories for pointing devices | |
Touch interaction within a graphical user interface [GUI] |
In this area, Indexing Codes G06F 2203/04101 - G06F 2203/04114 dealing with details which may be related to different sensing technologies are used in parallel to the classification scheme.
Subgroups G06F 3/0412 and G06F 3/0416 -G06F 3/04186 are not explicit to a specific sensing technology but describe details about the integration within a display or the driving/interface of the digitiser.
For documents belonging to these subgroups, if further relevant details related to the sensing technology are disclosed, the corresponding subgroup of G06F 3/041 that is best related to the sensing technology employed should be doubly allocated as invention information.
If the sensing technology is indicated only with minor details, the sensing technology (if any) should be indicated as additional information.
In this place, the following terms or expressions are used with the meaning indicated:
Surface | either as a physical surface or as a virtual one, such as a virtual interaction plane floating in the air |
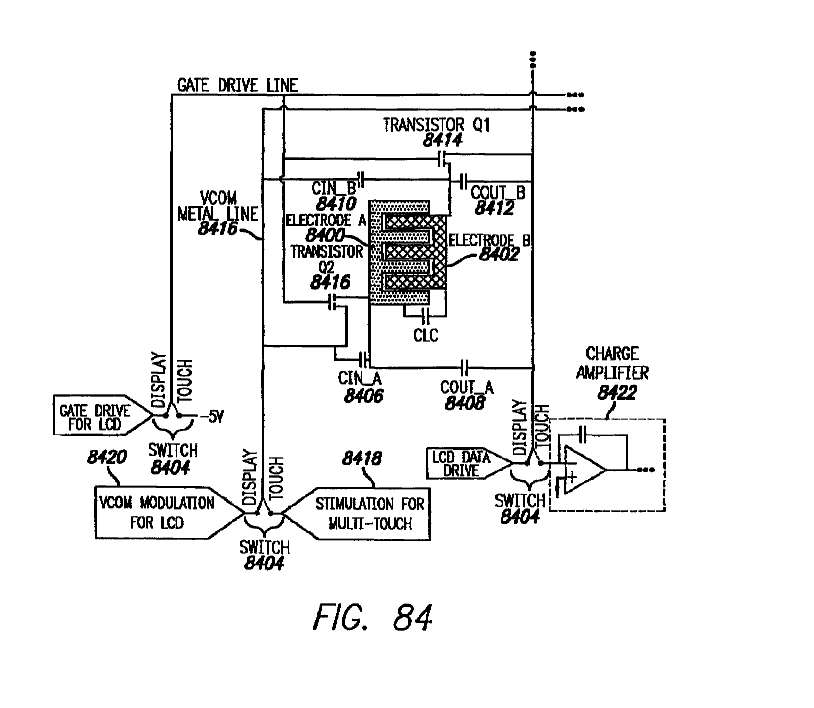
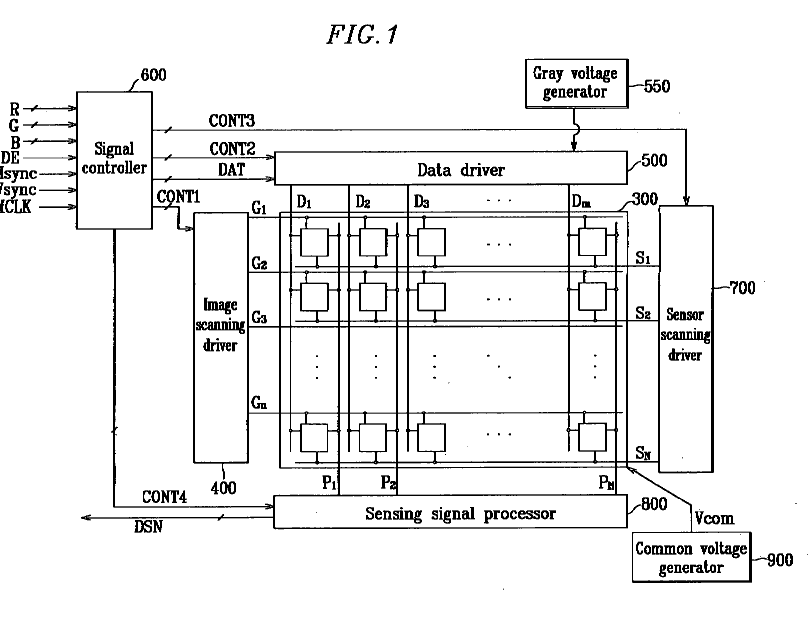
This place covers:
Structural details and methods of driving a combination of displays with digitisers that share at least one constitutive part of both the touch sensing technology as well as the display technology (e.g. a common electrode for LCD control and a touch electrode (i.e. driving or sensing) for capacitive touch sensing, a common electrode being used as a guard/shield electrode in touch sensing, or a common electrode that is specifically floated during a touch driving/sensing period).
Examples:
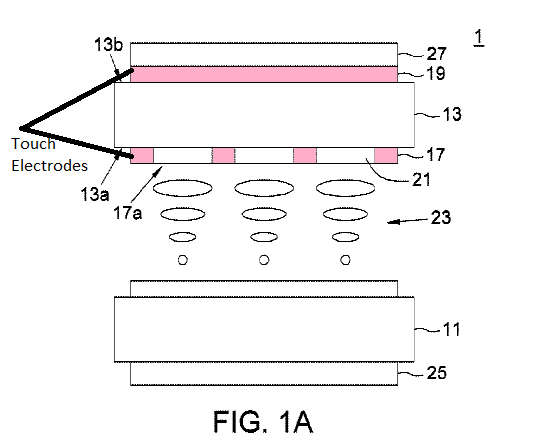
Structural details and methods of driving a display and a digitizer in which the digitizer is either wholly or in part within the structural confines that make up the display panel of the display device (e.g., a sensor pixel that is adjacent to the display pixel) or the sensor is arranged to utilize at least one structural component of the display panel (e.g. such as the top substrate of the display pane).
Examples:
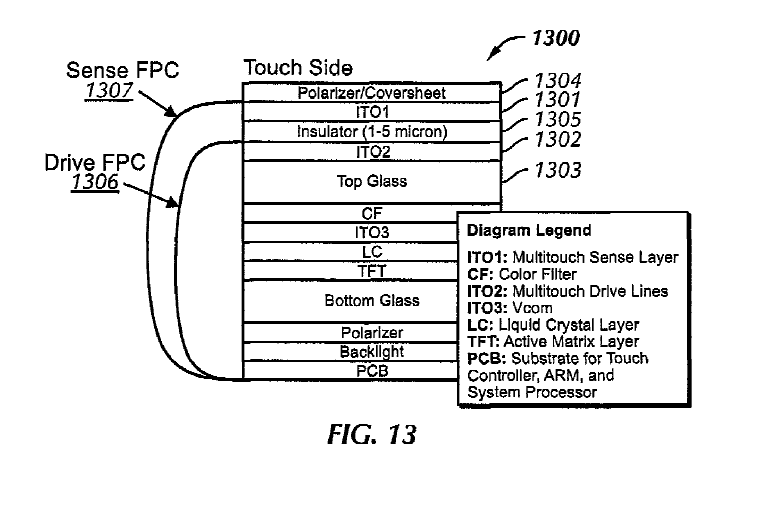
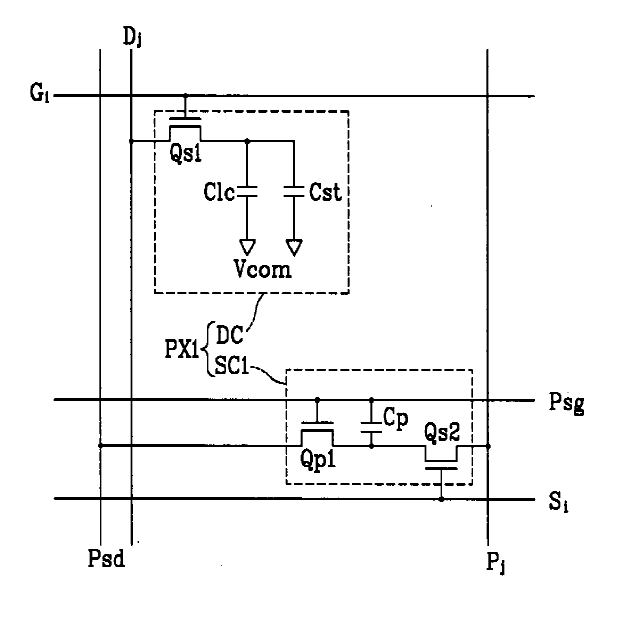
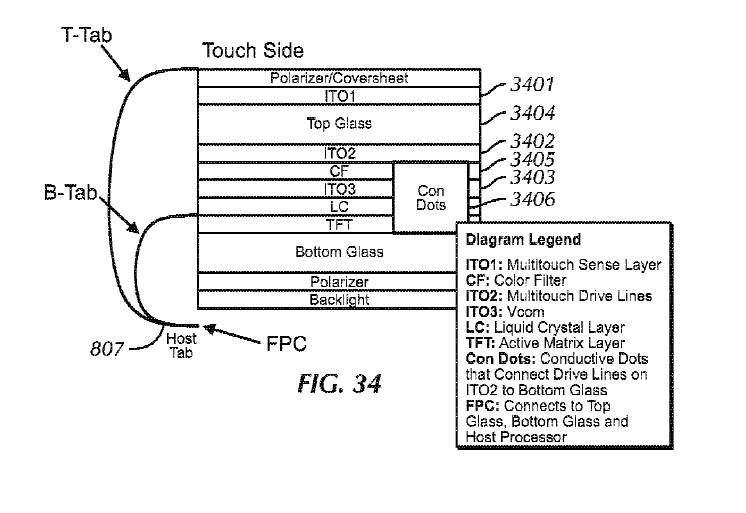
Attention is drawn to the following places, which may be of interest for search:
Constructional details of LCDs | |
Driving details of LED/OLED | |
Driving details of LCDs | |
Construction details of OLED displays |
Documents disclosing both a specific display panel (LCD, OLED etc.) and touch sensing are doubly classified in the relevant areas (for example: G02F for LCD, H01L for OLEDs, and G09G for methods of driving displays), pertaining to the respective types of display panels as well as in G06F 3/0412.
Devices in which a component is shared between touch detection circuitry and display driving circuitry, for example, a shared electrode for touch detection and display driving wherein the details of both the touch detection and the display driving are disclosed should be classified in the relevant areas either G09G (depending upon the type of display device) as well as in G06F 3/0412.
Devices in which construction details of both LCD panel and touch components are disclosed, but touch detection is only nominally disclosed should be classified only in G02F 1/13338 and only classified in G06F 3/0412 as an Additional.
Construction details of OLED display components integrated with touch detection components wherein the disclosure primarily concerns the OLED and minimally recites touch circuitry is classified in H10K 59/40 and only classified in G06F 3/0412 as an Additional.
This place covers:
Touch position determined by the analysis of the signals provided by pressure/force sensors.
Measuring force or stress in general: G01L 1/00.
Attention is drawn to the following places, which may be of interest for search:
Pressure sensors for measuring the pressure or force exerted on the touch surface without providing the touch position | |
Tactile force sensors | |
Force resistance touch switches | |
Piezoelectric touch switches |
This place covers:
Touch position determined by the analysis of the signals provided by a plurality (reduced number) of discrete pressure/force sensors disposed at several points of (e.g. under) the touch sensing surface, e.g. at the corners or the side of a touch sensing plate.
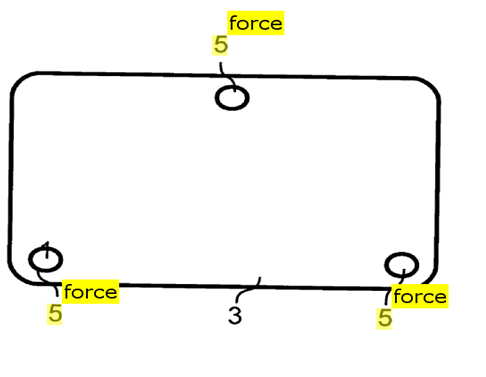
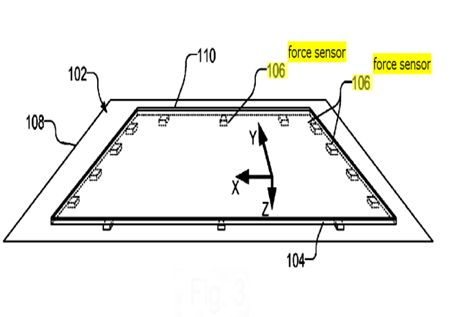
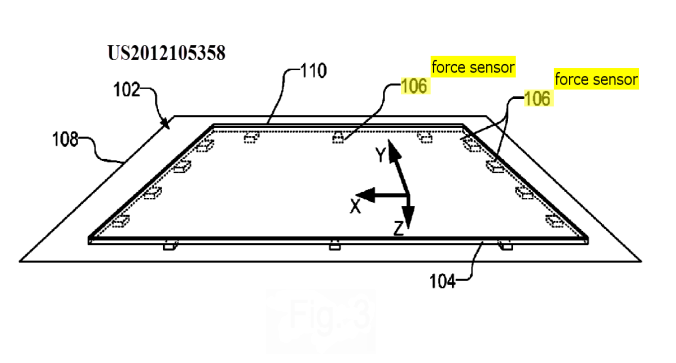
This place covers:
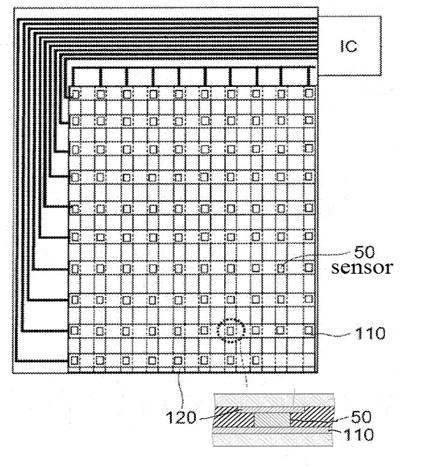
Touch position determined by the analysis of the signals provided by either virtual pressure sensors generated by intersection nodes of a grid of sensing lines interacting with a pressure sensitive medium or an array of discrete pressure/force sensors delivering a variable (not a single Boolean 0/1) signal, the array extending over the whole area of the touch sensing surface, e.g. a grid of sensors disposed under the touch sensing surface.
This place does not cover:
Position sensing using the local deformation of sensor cells |
This place covers:
Digitisers having a grid of crossing wires brought into virtual contact when pressure is exerted on the interaction surface, the virtual contact is established through a pressure sensitive layer disposed between the wire layers and made of a material that resistance diminishes under an applied pressure used to provide a "binary" output. The touch position is determined only by the contacting wires (scanning line and column) and not by the analog value of the sensed signal.
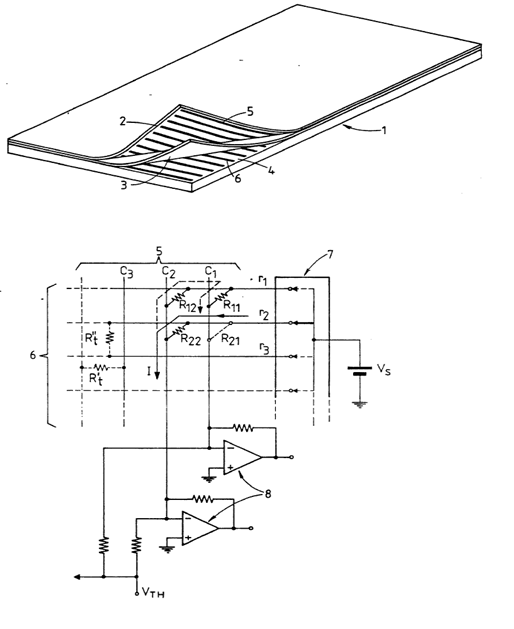
Attention is drawn to the following places, which may be of interest for search:
Tactile force sensors | |
Force resistance touch switches | |
Piezoelectric touch switches |
Attention is drawn to the following places, which may be of interest for search:
Touch interaction with a GUI |
This place covers:
Digitiser control allowing exchange of data with external devices via the digitiser sensing hardware (touch sensing electrodes, touch sensing coils, etc...), including exchange of information with smart pens as long as it concerns data transmission via the touch detection hardware.
Not for transmission of data between devices using only transmission paths other than the touch sensing hardware (e.g. wired or wireless network).
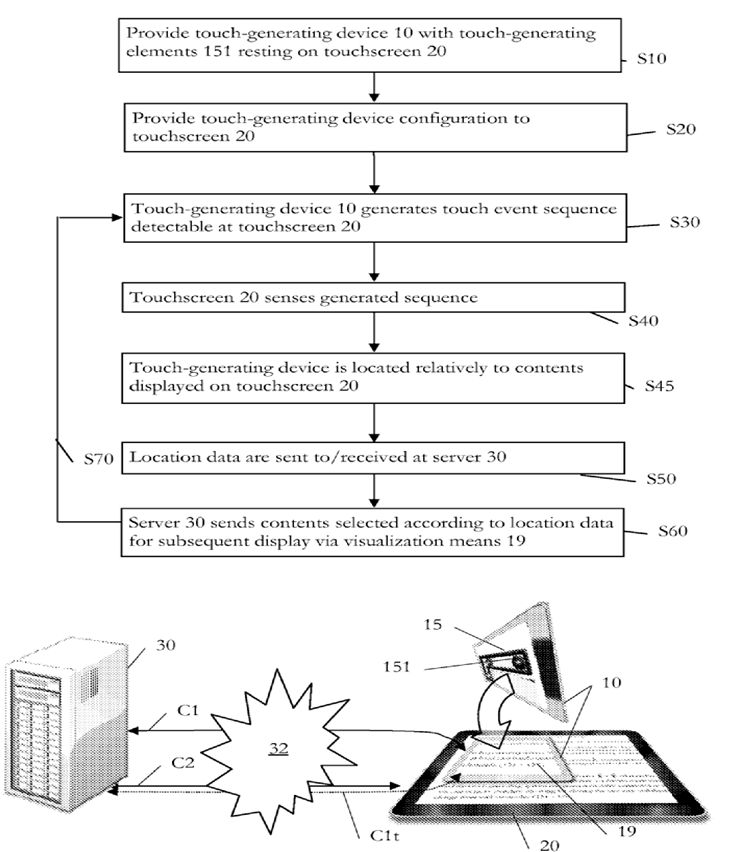
Attention is drawn to the following places, which may be of interest for search:
Remote control transmission over wireless link | |
Near-field transmission systems | |
Data switching networks | |
Mobile phones interface using two way short range wireless interface |
This place covers:
Routing between sensing electrodes and controller or connector, details on wiring and connectors.
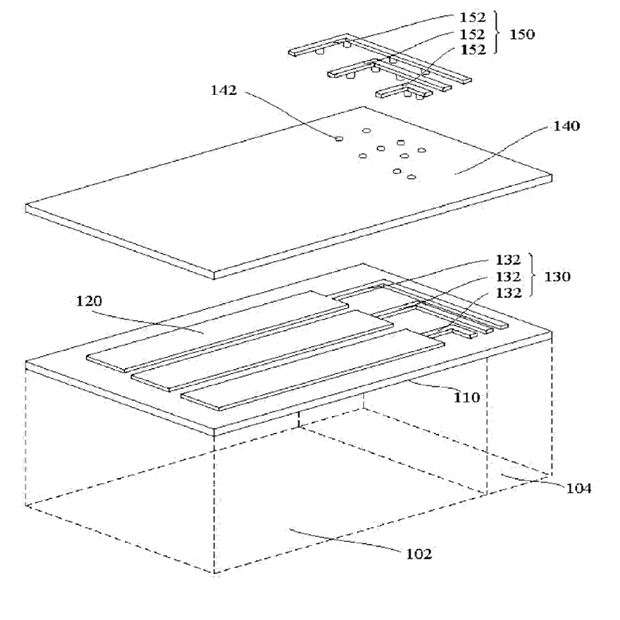
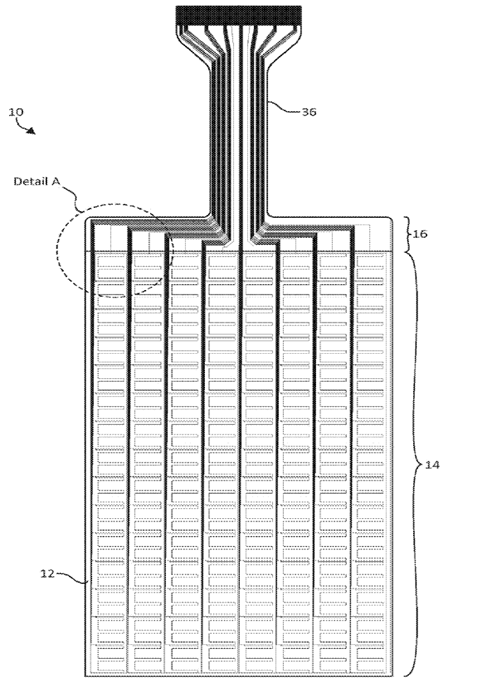
This place covers:
For example grouping electrodes for changing the detection speed, resolution or sensitivity (including proximity distance), detection of multiple touches, detection of both pen and finger or, combination of multiple touch technologies.
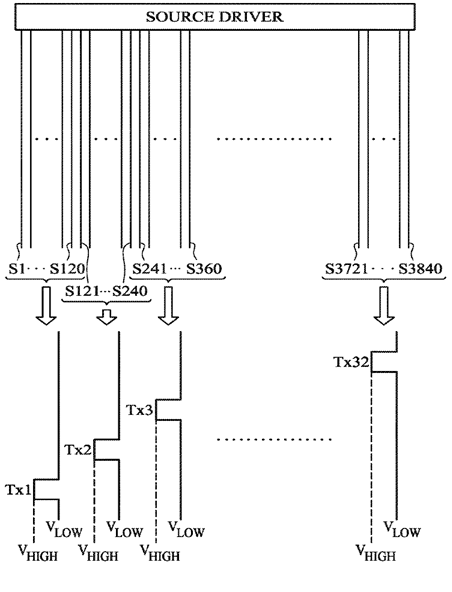
This place does not cover:
Synchronisation with the driving of the display or the backlighting unit to avoid interferences generated internally |
This place covers:
Synchronisation of the touch detection signals with the display (or backlight) driving signals whenever the digitiser is integrated in the display or not.
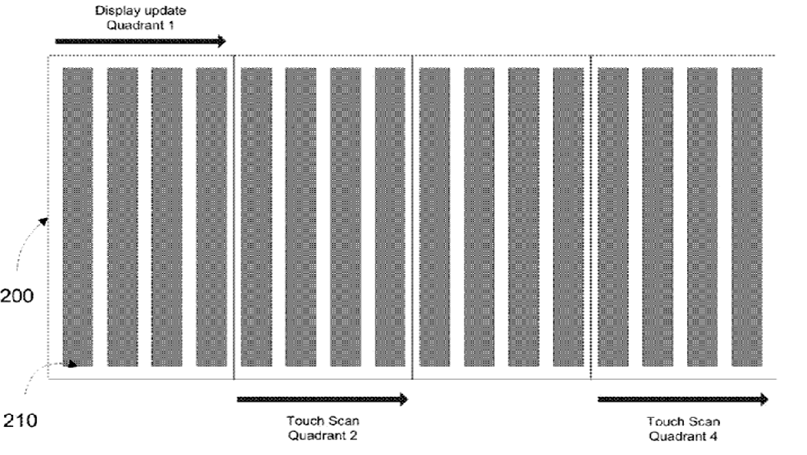
This place covers:
Correcting or resolving an ambiguous detected touch, resulting from either
- an ambiguous touch location measured by the digitiser (e.g. correcting a detected large single touch into more than one smaller and adjacent touches, a partial touch at an edge of a digitiser into a full touch, a detected touch with an unwanted detected event like hover/palm rejection, cracks, water droplets, impurities, ghost touches, or gravity center due to tilt/angle of the input device) or
- an ambiguous interaction with a GUI on a touch screen, wherein the touch location as measured by the digitiser is unambiguous (e.g. correcting a detected touch to a user intended touch position)
Documents disclosing disambiguation of an interaction with a GUI on a touch screen, wherein the touch location as measured by the digitiser is unambiguous, should be doubly classified in G06F 3/0488 and below.
Optical scanners: G06K 7/10544.
Attention is drawn to the following places, which may be of interest for search:
Pens detecting optically their absolute position with respect to a coded surface | |
Systems where the position detection is based on the screen scanning with a light pen | |
Measuring arrangements characterised by the use of optical means | |
Optical encoders | |
Position fixing using optical waves | |
Prospecting or detecting by optical means | |
Static switches using electro-optical elements in general | |
Optical switches | |
Optical touch switches |
When there is a doubt whether the subject matter belongs to G06F 3/0304 and below or to G06F 3/042 and below, the rule of thumb is: if the moving part is the sensor then it belongs to G06F 3/0304 and below, if the observed target (e.g. finger) is moving then it belongs to G06F 3/042 and below. In any case, the subclasses G06F 3/042 and below are used only in the context of interaction with a surface as defined in G06F 3/041 or in close proximity of this surface; they are not used in the context of a true 3D interactive environment.
In patent documents, the following abbreviations are often used:
FTIR | Frustrated Total Internal Reflection |
In this place, the following terms or expressions are used with the meaning indicated:
Beam | a narrow beam emitted in a given direction, not as a bright band of light or as an omnidirectional lightening; in the context of beams propagating from one side towards receivers on the opposite side in a grid like arrangement, the beam may have a triangular (or conical) shape with a slightly broader opening angle in order to be sensed by several receivers on the opposite side but not covering the whole array of receivers. |
Attention is drawn to the following places, which may be of interest for search:
Details of moving scanning beam in optical scanners |
This place covers:
Also documents where the acoustic wave is produced by knocking or rubbing the movable member (finger or pen) on the touch surface without any other vibration generator.
Attention is drawn to the following places, which may be of interest for search:
In patent documents, the following abbreviations are often used:
SAW | Surface Acoustic Waves |
This place covers:
Position detection using pens able either to emit acoustic waves using a dedicated wave generator (e.g. piezoelectric or mechanical vibrators, ultrasound generators or sparks) or to sense the propagating waves arriving through the surface.
Attention is drawn to the following places, which may be of interest for search:
Documents where the movable member (finger or pen) generates the waves but has no acoustic source | |
Piezoelectric vibrators |
This place covers:
Passive movable member (finger or pen) disturbing the propagating waves within the substrate.
Attention is drawn to the following places, which may be of interest for search:
Means for converting the output of a sensing member to another variable by varying capacitance | |
Capacitive proximity switches | |
Capacitive touch switches |
This place covers:
Digitisers using the capacitive coupling between the edge of a pointing pen or a similar sensing device and touch sensing conductors (electrodes) of the position sensing surface wherein the pen detects changes in electric potential of the conductors generated by the tablet (e.g. tablet driving signals); corresponding to JP FI: G06F 3/044.
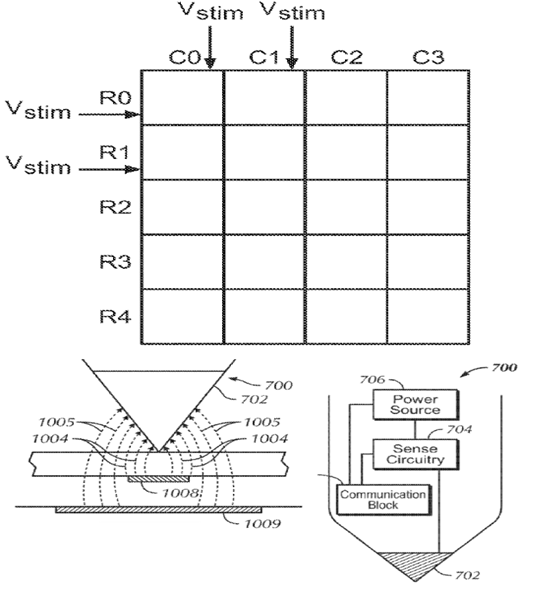
Attention is drawn to the following places, which may be of interest for search:
Transmission of data between devices using the touch sensing hardware as transmission path |
This place covers:
Digitisers using the capacitive coupling between the edge of a pointing pen or a similar input device and touch sensing conductors (electrodes) of the position sensing surface wherein active pens generate changes in electric potential of tablets, corresponding to JP FI: G06F 3/044.
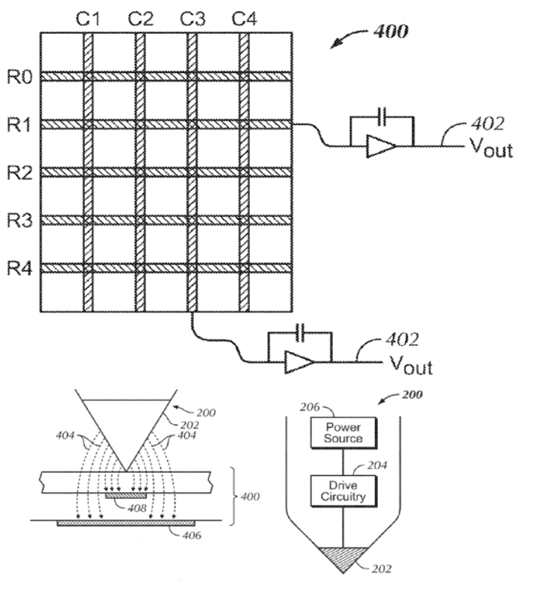
Attention is drawn to the following places, which may be of interest for search:
Transmission of data between devices using the touch sensing hardware as transmission path |
This place covers:
Digitisers using a single layer of sensing electrodes, i.e. sense and/or drive electrodes. The electrodes may be interconnected by bridges at crossings. The connecting bridge may be in another layer but all the sensing electrodes are in the same one.
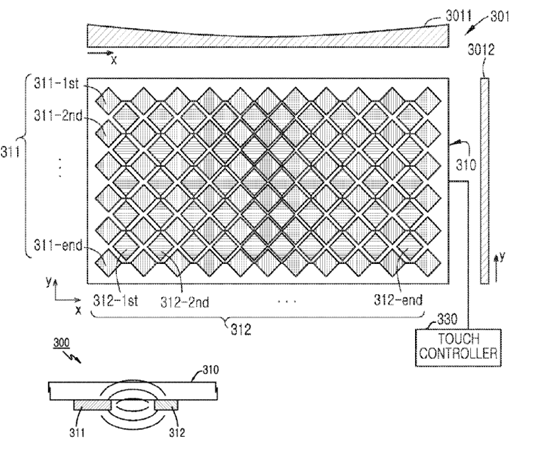
This place covers:
Digitisers using a single layer of sensing electrode which is made of a single piece of conducting material extending on the detection area and covered by a dielectric material.
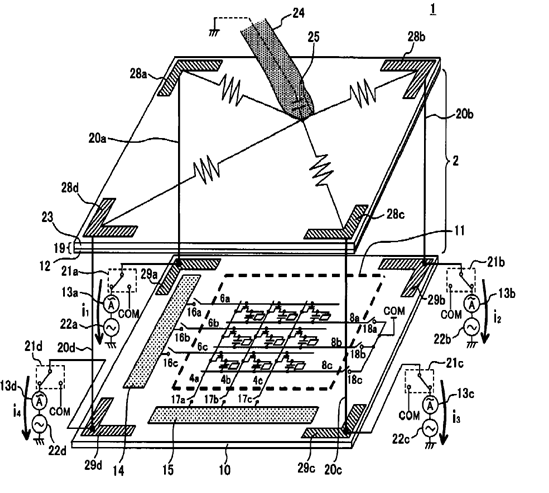
This place covers:
Digitisers using at least two layers of sensing electrodes, i.e. sense and/or drive electrodes, separated either by a solid dielectric layer or by a gap which could be filled by a dielectric material.
This place covers:
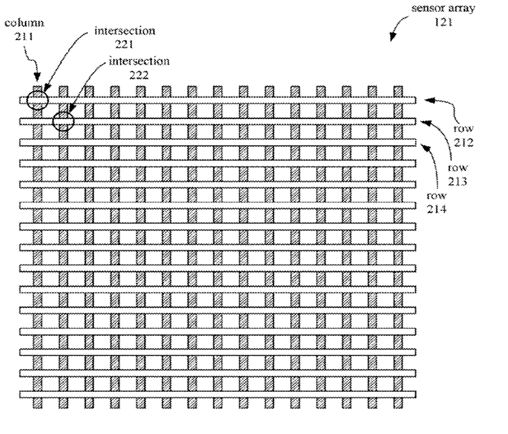
Digitisers comprising a plurality of sets of parallel sensing and/or driving electrodes extending in at least two crossing directions; each "row" or "column" electrode may be either a single piece electrode or a plurality of interconnected electrodes (e.g. via bridges over the electrodes in the crossing direction) making a virtual electrode extending along the given direction.
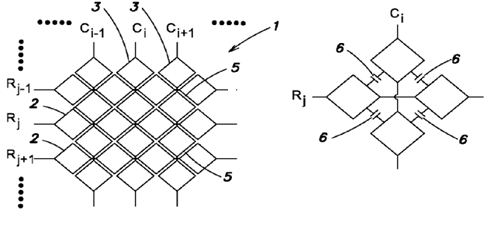
This place covers:
Digitisers comprising an array of cells, e.g. made by the crossing of "row" and "column" electrodes, which are deformed under the pressure of a touching object, inducing a change in their capacitance.
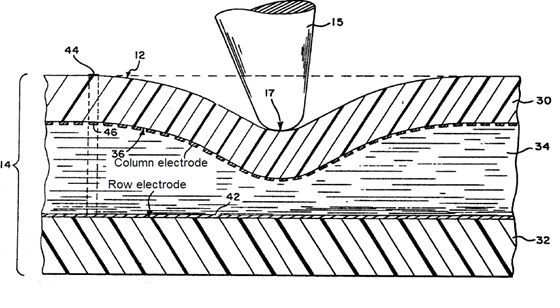
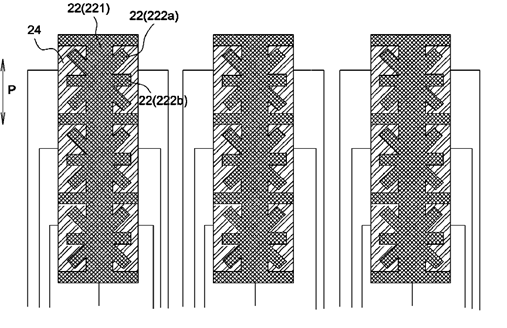
This place covers:
The electrodes have shapes optimised to obtain a specific effect, e.g. increasing fringe field, better resolution or avoiding moiré effect.
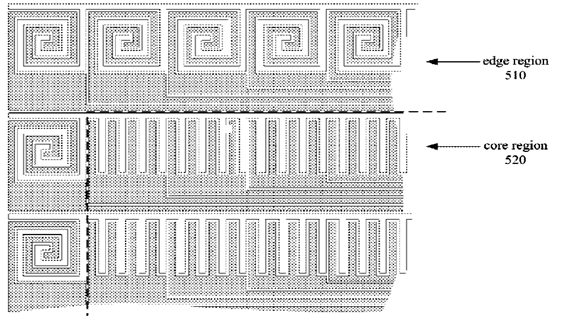
If the electrode design or pattern exhibits an irregular or non-conventional shape without mentioning any specific effect then this symbol should be allocated as additional information.
Attention is drawn to the following places, which may be of interest for search:
Touch switches |
Attention is drawn to the following places, which may be of interest for search:
Resistive potentiometers | |
Resistive touch switches |
Attention is drawn to the following places, which may be of interest for search:
Means for converting the output of a sensing member to another variable by varying inductance | |
Electromagnetic proximity switches using a magnetic detector |
This place covers:
Digitisers having a grid of crossing wires brought into contact when pressure is exerted on the interaction surface. The contact may be a direct contact or through a pressure sensitive switch making a connection between the wires. It includes arrays of switches integrated in a display where a galvanic contact is established between rows and columns when the user presses the display surface.
When wires or switches are integrated in a display, G06F 3/0412 should also be used.
This place covers:
Subject matter where the focus is on the way the user can interact with the displayed data, usually by means of pointing devices, irrespective of the type of data treated by the software application or the type of device embedding data processing capability.
As to the design of an interaction technique, this is most commonly determined by one or more of three factors, also in combination:
- the specific behaviour or appearance, of the graphical element or virtual environment;
- the kind of input events that can be generated by a specific input device used to interact with the displayed elements of the GUI;
- the type of operation or function to be performed with relation to these elements.
GUIs are widely used to interact with any type of software application, (e.g. operating system, word-processing or information retrieval applications, spreadsheets, etc.), executed on a general-purpose computer or on a specific device (e.g. car navigation system, telephone, photocopy machine).
Documents mentioning or implying the presence of a standard GUI in the context of the disclosure of a specific software application or a specific device capable of processing data related to its specific function, should be in general classified in the appropriate subclasses related to those software applications or specific devices.
Attention is drawn to the following places, which may be of interest for search:
Hardware interface between computer and display | |
User interface programs, e.g. command shells, help systems, UIMS | |
Input/output arrangements of navigation systems | |
Program-control in industrial systems | |
Drawing of charts or graphs | |
Editing figures and text | |
Control arrangements or circuits for visual displays | |
Display of multiple viewports | |
Interaction with a remote controller on a TV display | |
End user interface for interactive television or video on demand |
In patent documents, the following abbreviations are often used:
GUI | Graphical User Interface |
In this place, the following terms or expressions are used with the meaning indicated:
Cursor (also called (mouse) pointer) | an indicator used to show the position on a computer display that will respond to input from a text input or pointing device |
Attention is drawn to the following places, which may be of interest for search:
Interaction techniques based on cursor behaviour involving tactile or force feedback | |
Interaction techniques for the selection of a displayed object |
Attention is drawn to the following places, which may be of interest for search:
Video games | |
Navigational instruments, e.g. visual route guidance using 3D or perspective road maps (including 3D objects and buildings) | |
3D image rendering in general | |
Perspective computation in 3D image rendering | |
Navigation within 3D models or images (Walk- or flight-through a virtual museum, a virtual building, a virtual landscape etc.) |
This place covers:
Documents describing icons having a specific ( or unconventional ) design or specific properties.
This place does not cover:
Graphical programming languages using iconic symbols |
Attention is drawn to the following places, which may be of interest for search:
User interfaces specially adapted for operating a cordless or mobile telephone by selecting functions from two or more displayed items, e.g. menus or icons | |
Menu-type displays in TV receivers |
This place covers:
Documents which relate to tabs.
Interaction techniques of e-books when they are heavily book-inspired.
Attention is drawn to the following places, which may be of interest for search:
Electronic books, also known as e-books |
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
Edit or processing of text |
This place covers:
GUI interaction techniques specifically designed for selecting a displayed object, e.g. a window or an icon.
Selection by a pointing device (in the sense of G06F 3/03) such as a mouse, a joystick, a digitiser, etc.
This place does not cover:
Interaction with lists of selectable items, e.g. menus |
There are some older documents relating to selection by keyboard classified here. However, all new documents related to the latter are now classified in G06F 3/0489.
Every time a set of displayed of objects can be consider as structured as a "list of selectable items", the interaction technique for selecting an item should be classified in G06F 3/0482.
This place covers:
Image manipulation, e.g. dragging or rotation of the whole image, resizing of objects, changing their colour etc.
Attention is drawn to the following places, which may be of interest for search:
Image data processing or generation, in general | |
Editing figures and text; Combining figures or text |
This place covers:
Documents dealing with panning control.
In this place, the following terms or expressions are used with the meaning indicated:
Scrolling | "Dragging" in some applications, i.e. depicting a user gesture which is not causing a motion of a previously selected object, but rather a motion of a reference within a given context. |
This place covers:
Drag and drop operations comprise moving by the user a previously selected object, and finally releasing said object.
Attention is drawn to the following places, which may be of interest for search:
Interaction techniques to control scrolling |
In this place, the following terms or expressions are used with the meaning indicated:
Dragging | "Scrolling", i.e. depicting a user gesture which is not causing a motion of a previously selected object, but rather a motion of a reference within a given context. |
Attention is drawn to the following places, which may be of interest for search:
Constructional details of digitisers | |
Details of input/output arrangements of navigation systems including use of a touch screen and gestures |
Attention is drawn to the following places, which may be of interest for search:
3D input gestures | |
Handwriting per se | |
Digital ink recognition | |
Signature recognition |
This place covers:
Virtual keyboards displayed on a touchscreen or as a template on a tablet.
Attention is drawn to the following places, which may be of interest for search:
Arrangements for projecting a virtual keyboard in a portable computers | |
Character input methods like chording, prediction or disambiguation used on a keyboard | |
Programmable (hardware) keyboards | |
Entering handwritten data, e.g. gesture or text | |
Converting codes to words or guess-ahead of partial word inputs |
This place covers:
The use of keyboard keys dedicated to specific functions, e.g. <Scroll Lock>, <Home>, <PgUp> keys, as well as the use of specific combinations of keyboard keys, e.g. <Ctrl>+<A>, <Ctrl>+<C>, whereby the "+" means that the two keys have to be pressed together.
Attention is drawn to the following places, which may be of interest for search:
Selecting from displayed items by using keys for character input | |
Automatic teller machines (ATM) | |
Adjusting display parameters |
This place does not cover:
Arrangements for controlling cursor position based on coordinate signals |
Attention is drawn to the following places, which may be of interest for search:
Sample-and-hold arrangements | |
Sampling per se |
Attention is drawn to the following places, which may be of interest for search:
Error detection, error correction, monitoring per se regarding storage systems | |
Accessing or addressing within memory systems or architectures | |
Information retrieval | |
Recording or reproducing devices per se |
This place covers:
Physical and/or logical interfaces between a host or a plurality of hosts and a storage device or a plurality of storage devices or storage system related to data/command path and data placement techniques.
Storage devices include devices with rotating magnetic and optical storage media as well as solid state devices, or non-volatile electronic storage elements.
Interfaces to an emulated rotating storage device in (flash) memory.
Attention is drawn to the following places, which may be of interest for search:
Error detection, error correction, monitoring per se | |
Accessing, addressing or allocation within memory systems | |
Interconnection of, or transfer of information between memories, I/O devices, CPUs | |
File systems; file servers | |
Recording or reproducing devices per se | |
Cryptographic protocols | |
Network security protocols | |
Protocols for real-time services in data packet switching networks | |
Network protocols for data switching network services |
Each document should receive regarding "invention information":
- at least one classification in the range G06F 3/0602 - G06F 3/0626 for the technical effect achieved and
- at least one classification in the range G06F 3/0628 - G06F 3/0667 for the technique used and
- at least one classification in the range G06F 3/0668 - G06F 3/0689 for the infrastructure involved.
The classification of "additional information" is optional. CPC symbols in the range G06F 2206/1004 - G06F 2206/1014 should be used for classifying "additional information".
In this place, the following terms or expressions are used with the meaning indicated:
Storage system | An integrated collection of (a.) storage controllers and/or host bus adapters, (b.) storage devices such as disks, CD-ROMs, tapes, media loaders and robots, and (c.) any required control software, that provides storage services to one or more computers |
In patent documents, the following words/expressions are often used as synonyms:
- host
- computer
- PC
- PDA
- smartphone
- (micro)processor
- CPU
- terminal
- client
This place covers:
Facilitating administration like automating recurrent tasks, selecting and presenting management information to the system user or administrator.
This place covers:
Facilitating administration in relation to modification of existing systems, improving compatibility and scalability.
This place covers:
Effects leading to the reduction of the volume of data stored and the storage space requirements e.g. storage efficiency: the ratio of storage system's effective capacity to its raw capacity.
This group is often combined with the technique G06F 3/0641: data de-duplication.
This place covers:
Reducing I/O operation latency time, i.e. the time between the making of an I/O request and the completion of the request's execution.
This place covers:
Increasing I/O operation throughput, i.e. the number of I/O requests satisfied in a given time e.g. expressed in I/O requests/second (IOPS).
This place covers:
Only reliability effects with a technique specific for G06F 3/06 should be classified in this subgroup range.
Attention is drawn to the following places, which may be of interest for search:
Error detection or correction by redundancy in operation | |
Redundancy in hardware using active fault-masking |
This place covers:
Increasing the life expectancy measured in e.g. Mean Time Between Failures (MTBF)
Attention is drawn to the following places, which may be of interest for search:
User address space allocation in block erasable memory: | |
Auxiliary circuits for EPROMs: |
The subject covered by this group is often described in relation to non-volatile semiconductor memory (arrays), which are, as peculiar storage infrastructure, also classified in G06F 3/0679 or G06F 3/0688
This place covers:
Increasing availability, i.e. the amount of time the system is available during those time periods it is expected to be available, measured in e.g. hours of downtime in a year.
Attention is drawn to the following places, which may be of interest for search:
Redundancy in operation: | |
Redundancy in hardware using active fault-masking: |
This place covers:
Avoiding data to be altered or lost in operation or by accident.
Attention is drawn to the following places, which may be of interest for search:
Adding special bits or symbols to the coded information in memories: | |
Backing up (Point in time copy), restoring or mirroring files or drives: | |
Redundancy in hardware by mirroring: | |
Error detection or correction in digital recording or reproducing: |
Attention is drawn to the following places, which may be of interest for search:
Protecting data against unauthorised access or modification | |
Protecting computer components used for data storage | |
Arrangements for network security |
This place covers:
Securing storage systems by preventing unauthorised access to the storage system, e.g. with a password.
This place covers:
Securing storage systems by protecting the data content, e.g. by scrambing the content.
This place covers:
Reducing the power consumption of a storage system, i.e. power efficiency.
Power saving in storage systems with a plurality of storage devices external to the computer.
Attention is drawn to the following places, which may be of interest for search:
Power saving in a single storage device inside a computer | |
Driving, starting, stopping record carriers |
This group is usually combined with the technique G06F 3/0634 (configuration or reconfiguration of storage systems by changing the state or mode of one or more devices).
This group is usually combined with the infrastructure G06F 3/0689 (disk arrays) or G06F 3/067 (distributed storage).
This place covers:
Reducing the physical size, simplifying the physical integration of storage systems
This group is often combined with G06F 3/0658 (controller construction) in order to characterise the technique for the "invention information", e.g. System On Chip (SOC) controller.
This place covers:
This group is the hierarchical head group for the range G06F 3/0629 - G06F 3/0667 related to particular storage techniques and is not used for classification.
This place covers:
Configuration or reconfiguration aspects.
The general management of storage system features and behaviours through the control of changes made to hardware, software, firmware and related resources throughout the life cycle of the storage system.
This place covers:
Allocating physical and/or logical storage resources, including storage elements, storage devices, appliances, virtual devices, disk volume and file resources.
Virtualisation techniques for the allocation of storage areas such as thin-provisioning are classified in G06F 3/0665.
Attention is drawn to the following places, which may be of interest for search:
Management of already existing partitions | |
Allocation of resources in multiprogramming arrangements | |
Addressing or allocation |
This place covers:
- The startup and initial configuration of a storage device, system, piece of software or network.
- The process of installing or removing hardware or software components required for a system or subsystem to function.
- Assignment of the operating parameters of a system, subsystem or device, such as designating a disk array's member disks or extents and parameters such as stripe depth, RAID model, cache allowance, etc.
- The collection of a system's hardware and software components and operating parameters.
Attention is drawn to the following places, which may be of interest for search:
Program loading or initiating |
In this place, the following terms or expressions are used with the meaning indicated:
Discovery of storage device array configuration | Assignment of the disks and operating parameters for a disk array by setting parameters such as stripe depth, RAID model, cache allowance, spare disk assignments, etc. The arrangement of disks and operating parameters that results from such an assignment. |
This place covers:
Changing the operating state or mode or parameters of one or more storage devices e.g. changing the rotational speed (measured in RPM) or powering on/off or spinning up/down one or more storage devices.
This group is often assigned when there is a power saving effect mentioned see G06F 3/0625
In this place, the following terms or expressions are used with the meaning indicated:
Massive Array of Idle Disks (MAID) | A storage system comprising an array of disk drives that are powered down individually or in groups when not required. MAID storage systems reduce the power consumed by a storage array, at the cost of increased Mean Time To Data. |
In patent documents, the following abbreviations are often used:
MAID | Massive Array of Idle Disks |
This place covers:
Changing the configuration of a storage system by changing the interconnections in between storage system components or changing the routes over which the data flows from the host to the storage device and vice versa e.g. storage switches, storage ports, routing aspects in storage systems.
Attention is drawn to the following places, which may be of interest for search:
Distributed storage of data in networks, e.g. transport arrangements for network file system [NFS], storage area networks [SAN] or network attached storage [NAS] |
This group is usually combined with G06F 3/0607: improving administration by facilitating the process of upgrading existing storage systems.
In this place, the following terms or expressions are used with the meaning indicated:
Access path | The combination of adapters, addresses and routes through a switching fabric used by a computer to communicate with a storage device. |
This place covers:
Techniques related to the right of a user or host or group of users or group of hosts to access specific parts of a storage system, e.g. zoning, locking , shared access
Attention is drawn to the following places, which may be of interest for search:
Protecting computer components used for data storage | |
Access control in arrangements for network security e.g. Access Control Lists (ACL) |
This group is usually combined with the effect G06F 3/0622: securing storage system in relation to access
This place covers:
Data organising, formatting or addressing, e.g. compression of data in general in a storage interface.
Mapping aspects: conversion between two address spaces, such as the conversion between physical disk block addresses and logical disk block addresses of virtual disks presented to operating environments by control software, i.e. by using mapping tables which contain the correspondence between the two address spaces being mapped to each other.
Partitioning of storage systems, i.e. the creation of partitions.
- Creation of partitions in a formatted disk is classified in G06F 3/0638.
- Allocation of existing partitions is classified in G06F 3/0631.
Attention is drawn to the following places, which may be of interest for search:
Translation of protocol format and protocol data in a data movement | |
Image compression | |
Audio compression | |
Time compression or expansion in a recording device | |
Compression in general | |
Data compression in computer networks | |
Video compression |
In this place, the following terms or expressions are used with the meaning indicated:
Partitioning | Presentation of the usable storage capacity of a disk or array to an operating environment in the form of several virtual disks whose aggregate capacity approximates that of the underlying physical or virtual disk. Partitioning is common in MS-DOS, Windows, and UNIX environments. Partitioning is useful with hosts that cannot support the full capacity of a large disk or array as one device. It can also be useful administratively, for example, to create hard subdivisions of a large virtual disk. |
This place covers:
Techniques related to the management of blocks in storage systems
In this place, the following terms or expressions are used with the meaning indicated:
Block | The unit in which data is stored and retrieved on disk and tape devices; the atomic unit of data recognition (through a preamble and block header) and protection (through a CRC or ECC). |
Block addressing | An algorithm for uniquely identifying blocks of data stored on disk or tape media by number, and then translating these numbers into physical locations on the media. |
This place covers:
Techniques related to data de-duplication, i.e. the replacement of multiple copies of data - at variable levels of granularity - with references to a shared copy in order to save storage space and/or bandwidth.
Attention is drawn to the following places, which may be of interest for search:
Using de-duplication of the data stored as backup | |
File systems; File servers | |
Compression in general |
This group is usually combined with G06F 3/0608: saving storage space
This place covers:
Techniques related to the management of files in storage systems, e.g. low level file system aspects like File Allocation Tables (FAT)
Attention is drawn to the following places, which may be of interest for search:
User address space allocation | |
File systems; file servers | |
Processing unordered random access data using directory or table look-up | |
Table of contents on record carriers (VTOC) |
This place covers:
Techniques related to the management of space entities in storage systems, e.g. management of partitions, extents, pools
Attention is drawn to the following places, which may be of interest for search:
Creation of space entities (allocating resources to storage systems) | |
User address space allocation | |
File systems; File servers | |
Table of contents on record carriers (VTOC) | |
Distributed storage of data in networks, e.g. transport arrangements for network file system [NFS], storage area networks [SAN] or network attached storage [NAS] |
This place covers:
Aspects of horizontal moving of data between storage devices or systems.
This place covers:
Movement of data or information between information systems, formats, or media. Migration is performed for reasons such as possible decay of storage media, obsolete hardware or software (including obsolete data formats), changing performance requirements (see tiered storage), the need for cost efficiencies etc.
HSM and Tiered storage aspect are usually combined with G06F 3/0685 (hierarchical storage) in order to characterise the infrastructure.
In this place, the following terms or expressions are used with the meaning indicated:
Tiered storage | Storage that is physically partitioned into multiple distinct classes based on price, performance or other attributes. Data may be dynamically moved among classes in a tiered storage implementation based on access activity or other considerations. |
Hierarchical Storage Management (HSM) | The automated migration of data objects among storage devices, usually based on inactivity. Hierarchical storage management is based on the concept of a cost-performance storage hierarchy. By accepting lower access performance (higher access times), one can store objects less expensively. |
This place covers:
Data Lifecycle Management (DLM) comprising the policies, processes, practices, services and tools used to align the business value of data with the most appropriate and cost-effective storage infrastructure from the point in time when data is created through its final disposition. Data is aligned with business requirements through management policies and service levels associated with performance, availability, recoverability, cost, etc. DLM is a subset of Information Lifecycle Management (ILM).
By automatically moving less frequently accessed objects to lower levels in the hierarchy, higher cost storage is freed for more active objects, and a better overall cost to performance ratio is achieved
Attention is drawn to the following places, which may be of interest for search:
File systems; File servers | |
Details of archiving in file system administration | |
Details of hierarchical storage management (HSM) systems |
In patent documents, the following words/expressions are often used as synonyms:
- Retention policy
- Retention time
This place covers:
Replication is the technique of sharing information so as to ensure consistency between redundant resources, such as software or hardware components, to improve reliability, fault-tolerance, or accessibility.
Attention is drawn to the following places, which may be of interest for search:
Backing up (Point in time copy), restoring or mirroring files or drives | |
Redundancy in hardware by mirroring |
This group is usually combined with G06F 3/0614 (improving the reliability of storage systems) and subgroups in order to characterise the effect achieved by the replication mechanism.
In patent documents, the following words/expressions are often used as synonyms:
- Remote copy
- Mirroring
- Snapshot
This place covers:
Erasing of data in storage systems including secure erasure.
Attention is drawn to the following places, which may be of interest for search:
File systems; File servers | |
Delete operations in file systems | |
Cleaning, erase control related to flash memory management | |
Clearing memory, e.g. to prevent the data from being stolen |
This group is often combined with G06F 3/0623 (securing storage systems in relation to content) in order to characterise the effect achieved by the invention
In this place, the following terms or expressions are used with the meaning indicated:
Data shredding | The technique of deleting data that is intended to make the data unrecoverable. One such process consists of repeated overwrites of data on disk. Data shredding is not generally held to make data completely unrecoverable in the face of modern forensic techniques—that requires shredding of the disks themselves. |
This place covers:
Monitoring aspects related to storage interfaces, i.e. extra functionality for observing properties of a running storage device or storage system in its normal operating conditions without inputting test data.
Attention is drawn to the following places, which may be of interest for search:
Thermal management in cooling means | |
Power management | |
Monitoring for error detection | |
Verification or detection of system hardware configuration: | |
Monitoring per se of computing systems | |
Intrusion detection | |
Monitoring of control systems | |
Monitoring, i.e. supervising the progress of recording or reproducing | |
Network monitoring | |
Network monitoring to detect or protect against malicious traffic | |
Monitoring testing in wireless networks |
This place covers:
Arrangements using one or more buffers whereby a buffer is a memory device or programming construct, used to hold data momentarily as it moves along an I/O path or between software components.
Typically, a solid state memory device is used as a buffer. However, any storage device with faster access properties in relation to the storage device it is buffering can be used, e.g. a disk drive can act as a buffer for a tape device.
Attention is drawn to the following places, which may be of interest for search:
Changing the speed of data flow, e.g. FIFO buffers per se | |
Partitioned buffers | |
Caches for peripheral storage systems, e.g. disk caches | |
Detection or prevention of read or write errors by using a data buffer |
In this place, the following terms or expressions are used with the meaning indicated:
Buffer | A region of a physical memory storage used to temporarily hold data while it is being moved from one place to another. It often adjusts timing by implementing a queue algorithm in memory, simultaneously writing data into the queue at one rate and reading it at another rate. |
In patent documents, the following words/expressions are often used as synonyms:
- FIFO
- queue
This place covers:
Constructional details of the storage interface not elsewhere provided for.
Physical connecting arrangements not elsewhere provided for.
Hardware arrangements of storage interface components like processors, bridges, offload engines, state machines
Attention is drawn to the following places, which may be of interest for search:
Information transfer on a bus, bus structures | |
Disposition of constructional parts in recording /reproducing devices | |
Electrical connectors |
This place covers:
Techniques related to command decoding and execution and command transformation and routing including command buffering, command queuing, command scheduling
Attention is drawn to the following places, which may be of interest for search:
Data buffering |
In this place, the following terms or expressions are used with the meaning indicated:
I/O scheduling | Term used to describe the method computer operating systems decide the order in which block I/O operations will be submitted to storage volumes. |
In patent documents, the following words/expressions are often used as synonyms:
- I/O scheduling
- disk scheduling
This place covers:
Techniques related to the conversion of recording formats, e.g. conversion from Count Key Data (CKD) format from a mainframe to Fixed Block Architecture (FBA) format of an open systems computer.
Techniques related to the conversion of storage protocols; bridging hardware e.g. conversion from Small Computer System Interface (SCSI) protocol to an Advanced Technology Attachment (ATA) protocol.
Attention is drawn to the following places, which may be of interest for search:
Information transfer using universal interface adapter: | |
Coupling between buses in general using bus bridges |
This place covers:
Storage virtualisation refers to:
- The act of abstracting, hiding, or isolating the internal functions of a storage (sub)system or service from applications, host computers, or general network resources, for the purpose of enabling application and network-independent management of storage or data.
- The application of virtualisation to storage services or devices for the purpose of aggregating functions or devices, hiding complexity, or adding new capabilities to lower level storage resources.
This place covers:
Devices presented to an operating environment by control software or by a volume manager. From an application standpoint, a virtual device is equivalent to a physical one. In some implementations, virtual devices may differ from physical ones at the operating system level, e.g., booting from a host based disk array may not be possible.
Storage device emulation, e.g. disk emulation.
Storage (sub)system emulation, e. g. Virtual Tape System.
Port virtualisation on a storage network switch, storage interface virtualisation.
Attention is drawn to the following places, which may be of interest for search:
Program control for peripheral devices where the program performs an input/output emulation function |
In this place, the following terms or expressions are used with the meaning indicated:
Virtual disk | A set of disk blocks presented to an operating environment as a range of consecutively numbered logical blocks with disk-like storage and I/O semantics. |
Virtual tape | A virtual device with the characteristics of a tape. |
Virtual tape: a virtual device with the characteristics of a tape.
This place covers:
Storage area virtualisation, i.e. the act of applying virtualisation to one or more area based (storage) services for the purpose of providing a new aggregated, higher level—e.g., richer, simpler, more secure—storage area service to clients.
Thin provisioning.
Dynamic allocation of logical volumes.
In this place, the following terms or expressions are used with the meaning indicated:
Thin provisioning (also, dynamic provisioning) | A technology that allocates the physical capacity of a volume or file system as applications write data, rather than preallocating all the physical capacity at the time of provisioning. |
This place covers:
Object virtualisation:
- The use of virtualisation to present several underlying objects as one single composite object.
- The use of virtualisation to present an integrated object interface when object data and metadata are managed separately in the storage system.
Attention is drawn to the following places, which may be of interest for search:
File systems; File servers |
In this subrange, the physical storage infrastructure should be classified and not the virtualised infrastructure if present. If the virtualised storage infrastructure is important, this should be classified in G06F 3/0664.
This place covers:
Architectures comprising multiple storage systems interconnected by a network allowing access from multiple hosts with emphasis on storage related aspects.
Depicted below, an exemplary connection of storage device to a host through a network.
Attention is drawn to the following places, which may be of interest for search:
Distributed file systems implemented using NAS architecture | |
Distributed storage of data in networks, e.g. transport arrangements for network file system [NFS], storage area networks [SAN] or network attached storage [NAS] |
This place covers:
Architectures with a direct host to storage system connection attachment.
Depicted below, an exemplary connection of storage device(s) to a host through a direct connection.
This place covers:
Storage systems comprising a single controller controlling one or more storage media, e.g. drums.
Depicted below, an exemplary architecture for a single storage device. 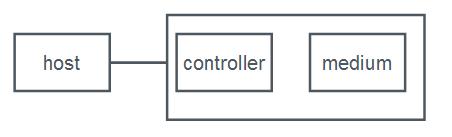
This place covers:
Storage devices being a spinning disk drive, i.e. a non-volatile, randomly addressable, data storage device.
This place covers:
Storage devices being a magnetic disk drive, e.g. HDD, DASD.
This place covers:
Optical disk drives, e.g. CDROM, DVD, WORM optical disk.
This place covers:
Semiconductor storage devices, e.g. SSD (solid state drive), flash memory, one time programmable memory (OTP).
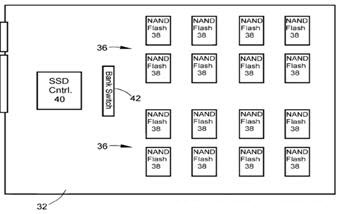
Attention is drawn to the following places, which may be of interest for search:
Low level flash management such as logical to physical address mapping, erase management and wear levelling | |
Auxiliary circuits for EPROMs |
This place covers:
Storage devices comprising a controller and multiple storage medium types, e.g. magnetic and semiconductor mediums sharing the same controller. 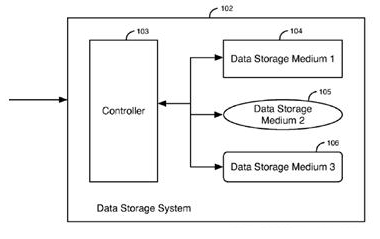
This place covers:
Storage devices being spinning tape devices, i.e. a non-volatile, serial addressable data storage device.
Attention is drawn to the following places, which may be of interest for search:
Digital recording/reproducing, formatting on tapes |
This place covers:
Storage systems comprising multiple controllers and a plurality of storage devices. 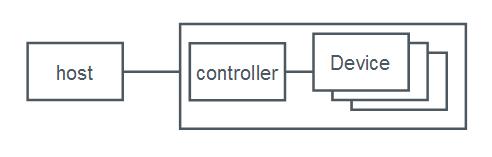
This place covers:
Storage systems comprising multiple controllers and multiple storage medium types, e.g. SSD, HDD and tapes combined; FC-HDD, SATA-HDD, SCSI-HDD combined. 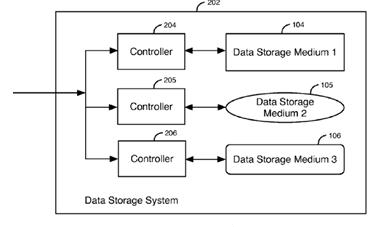
Attention is drawn to the following places, which may be of interest for search:
User address space allocation in block erasable memory | |
Auxiliary circuits for EPROMs |
This place covers:
Storage systems providing automatic access to multiple media cartridges typically via an automatic loading robot, e.g. tape library, media changer, juke box.
Attention is drawn to the following places, which may be of interest for search:
Control of automated cassette changing arrangements | |
Control systems for magazines of disc records |
This place covers:
Storage systems comprising multiple controllers and multiple semiconductor storage devices. 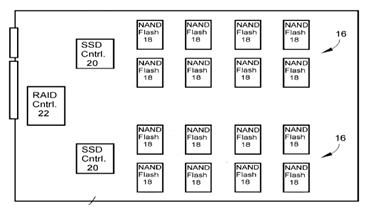
This place covers:
Storage systems comprising multiple controllers and multiple spinning disk drives, e.g. RAID, JBOD.
Attention is drawn to the following places, which may be of interest for search:
Error Correction Coding (ECC) for RAID |
In this place, the following terms or expressions are used with the meaning indicated:
RAID | Redundant Array of Independent Disks (originally: of Inexpensive disks) |
JBOD | Just a Bunch Of Drives |
This place covers:
Interfaces between a host or a plurality of hosts and a memory card reader or a plurality of memory card readers in relation to the data/command path and data placement techniques.
Attention is drawn to the following places, which may be of interest for search:
Information transfer using universal interface adapter | |
Methods or arrangements for sensing record carriers | |
Memory card, integrated circuit (IC) card, smart card, record carriers for use with machines and with at least a part designed to carry digital markings | |
Record carriers with integrated circuit chips | |
Coded identity card or credit card with a coded signal | |
Active credit-cards provided with means to personalise their use |
In patent documents, the following words/expressions are often used as synonyms:
- Memory card
- Integrated Circuit (IC) card
- Smart card
- Intelligent card
- Active card
This place covers:
Old technology related to interfaces with typewriters.
Not used for classification of new documents.
Attention is drawn to the following places, which may be of interest for search:
Digital output to typewriter | |
Arrangements for producing a permanent visual presentation of the output data using printers |
This place covers:
Interfaces between a host or a plurality of hosts and a printer device or a plurality of printer devices. Techniques for preparing the print job, sending it to a printer and printing it.
This place does not cover:
Digital output to typewriter | |
Controlling a printer in view of its graphical performance | |
Printing of alphanumeric characters | |
Special arrangements for scanning and reproduction of pictures, e.g. photographs, facsimile |
This group contains older documents (published before the year 2000) from which the majority are not reorganised in the G06F 3/1201 and its subgroups. No new/recent documents should be classified in G06F 3/1201.
Each new document should receive regarding "invention information":
- at least one class in the sub-groups of G06F 3/1202 for the technical effect achieved;
- at least one class in the sub-groups of G06F 3/1223 for the technique used and
- optionally one class in the sub-groups of G06F 3/1278 for the infrastructure involved.
Class in G06F 3/1278 is added only if the infrastructure plays a major role in the "invention information".
The classification of "additional information" is optional.
Indexing Code symbols in the sub-groups of G06F 3/1202 and/or G06F 3/1223 and/or G06F 3/1278 and/or G06F 2206/15 should be used for classifying "additional information".
The older documents should be retrieved using Indexing Codes:
- G06F 3/1293 Printer information exchange with computer;
- G06F 3/1294 Status or feedback related to information exchange;
- G06F 3/1295 Buffering means;
- G06F 3/1296 Printer job scheduling or printer resource handling;
- G06F 3/1297 Printer code translation, conversion, emulation, compression; Configuration of printer parameters;
- G06F 3/1298 Printer language recognition, e.g. program control language, page description language.
The "additional information" can be found by combining the above Indexing Code(s) with the Indexing Code G06F 3/1201.
In patent documents, the following words/expressions are often used as synonyms:
- "image forming device/apparatus", "image processing device/apparatus", "image printing device/apparatus", "image output device/apparatus", "image control device/apparatus" and "information processing device/apparatus" and "MFP Multi-Function Printer"
This group is not used for classifying documents in it, but to introduce one of the three classification criteria mentioned in the "Special rules for classification" section of G06F 3/1201.
This place covers:
All general aspects of printing management which do not fit in the sub-groups.
This place covers:
Preventing the user or operator from / avoiding the need for doing complicated and burdensome actions related to the printing of a document.
This place covers:
Assisting or helping the user during print job configuration, e.g. increasing granularity in job configuration, achieving more customised settings, proposing suitable settings, preventing selection of incompatible or undesirable print options.
This group is usually combined with G06F 3/1253 and its sub-groups in order to characterise the technique for the "invention information".
This place covers:
Assisting or helping the user to send a print job regardless of the format or type of data that should be printed. Facilitating usage of old print systems with new print systems, more specifically when compatibility between old data formats and new data formats should be achieved.
This place covers:
All aspects that make the user aware of what happened with the print job after it being sent.
This group is usually combined with G06F 3/1259 and its sub-groups in order to characterise the technique for the "invention information".
This place covers:
Assisting the user to increase the quality of print output (e.g. matching print output to what was intended by the user, increasing the appeal of the print output), e.g. by using preview screens, test printing. Actions or processing directed to higher fidelity.
This group is usually combined with G06F 3/1253 and its sub-groups in order to characterise the technique for the "invention information".
This place covers:
Facilitating usage of old print systems with new print systems, more specifically when compatibility between protocols should be achieved. Modifying/enhancing legacy communication protocols to extend their use into (additional) printing environments or print-related functionality (e.g. modifying Bluetooth to adapt to printing --> Basic Printing Profile (BPP)).
This place covers:
Assisting or helping the user to predict or deal with faults, e.g. device faults, lack of consumables, communication errors. Recovering from faults.
Attention is drawn to the following places, which may be of interest for search:
Error or fault reporting or storing |
This place covers:
All aspects of making the job to be printed faster that do not fit in the sub-groups.
This place covers:
Decreasing the time between sending a print job (e.g. pressing "print" button) and actual start of the same job at the print device.
This place covers:
Achieving decreasing the time at the node where the job is either temporarily stored (e.g. computer, server, printer) or actually printed (the printer).
This place covers:
Achieving decreasing the time at the node where the job is initiated from (e.g. computer, server, printer).
This place covers:
Decreasing the time actually spent to print the job, once printing has commenced, at the print device.
This place does not cover:
Reducing the time between arriving of the job at the printer till actual print process starts. |
This place covers:
Decreasing the time during which the printer is doing nothing.
This place covers:
Saving resources of the printer used for printing a job.
This place covers:
Preventing waste of used consumables (see for example US2011051164).
This place covers:
Optimal usage of system's hardware resources.
This place does not cover:
Reducing the number of required printer devices |
This place covers:
Power saving; reducing energy consumption.
This group is usually combined with G06F 3/1229 and its sub-groups in order to characterise the technique for the "invention information".
This place covers:
Adding secure aspects to a print job. Preventing unauthorised printing of a job, limiting the printing based on user credentials.
This group is usually combined with G06F 3/1238, G06F 3/1239 or G06F 3/1234 in order to characterise the technique for the "invention information".
This group is not used for classifying documents in it, but to introduce one of the three classification criteria mentioned in the "Special rules for classification" section of G06F 3/1201.
This place covers:
All aspects that deal with the software or hardware resources of the client or server which do not fit in the sub-groups (see e.g. US2011013223, US2009007151).
This place covers:
Updating or installing printer drivers on the client or server. Adding additional functionality to existing printer drivers (e.g. installing plug-ins, downloading printer definition files). Support for newly installed printers by replacing/updating existing drivers.
This place covers:
The client or the server sends requests to find suitable printers for printing based on certain requirements, e.g. colour, double side printing, finishing options, status, location, supported encryption, etc.
Attention is drawn to the following places, which may be of interest for search:
Device discovery specifically adapted for a queued job and aiming at e.g. load balancing or optimised printing | |
Network management | |
For service discovery | |
Network services | |
Network applications for service discovery |
This place covers:
Printer properties and commands to invoke/execute the printing properties are described in a separate file and can be used by an application program to convert a print job according to certain printer properties without a printer driver. The file can be used by the printer driver as well, e.g. for supporting different printers (see e.g. "Service Item File" in US6897974).
This place does not cover:
Driverless printing |
This place covers:
Specific printer drivers are not used but also printer definition files are not used. Usually a thin client with limited resources is involved. Generic drivers normally are designed to support plurality of different types/models of printers and/or different operating systems.
This place covers:
Device status when checked only in relation to printing of a job - power-level (e.g. on, off, power saving mode), operating or not, reasons for the malfunctions. Logging of device status. All aspects for managing the device which do not fit in the sub-groups.
Attention is drawn to the following places, which may be of interest for search:
Print job status | |
Network management | |
for service discovery | |
Network services | |
Network applications for service discovery |
This place covers:
Downloading or updating of printer's firmware. Installing new software for supporting newly added hardware or additional functions (e.g. image processing functions, resident fonts, support for new data formats).
This place covers:
Update or initialisation of the printer specific properties - IP address, Device name (see e.g. EP1372059, US2005151988).
This place does not cover:
Printer device capabilities |
This place covers:
Transmitting to the requestor printing device capabilities, e.g. double side printing, finishing options, dpi, colour or b/w, ppm (see e.g. EP1435565, EP1178393).
This place does not cover:
Printer device properties/settings, not related to printing capabilities, i.e. IP address. This aspect is covered in |
This place covers:
How to handle received jobs or the job currently being printed in case of error, e.g. reprint only the portion that was not printed, reprint the full job, delete the job and ask the host to send it again.
This place does not cover:
Alternate printer taking over the job from the failed device. |
Attention is drawn to the following places, which may be of interest for search:
Error or fault reporting or storing |
This place covers:
Specific aspects for recovering from errors caused by end of consumables - paper, ink, toner.
This place covers:
All aspects relating to connection between devices - client<->printer, server<->printer, printer<->printer. (see e.g. US2011019231 or US2011019231).
This place covers:
General aspects of job management that do no fit in the sub-groups.
This place does not cover:
Print device management |
This place covers:
Based on user/content credentials allowing/disabling usage of the printer as a whole.
This place does not cover:
Virus detection and handling. |
This place covers:
Limiting the use of printing as such (e.g. credit limit) or limiting the use of printers (e.g. time the printer can be used, e.g. only 1 hour a day, only after 17:00). Restricting configuration options, e.g. to plain paper, to black ink only, double-sided or n-up printing, lower resolution, limited image effects.
This group is usually combined with G06F 3/1219 or G06F 3/122 in order to characterise the effect achieved by the "invention information".
This place covers:
Printing or ripping several portions of a job at the same time.
This group is usually combined with G06F 3/1215 in order to characterise the effect achieved by the "invention information".
This place covers:
Print job is divided and different parts are sent to different devices having different properties.
This place does not cover:
Dividing for parallel printing |
This place covers:
Composing or overlaying content from different sources, e.g. different documents, onto a page.
Attention is drawn to the following places, which may be of interest for search:
2D [Two Dimensional] image generation | |
Image acquisition |
This place covers:
Print data for a page is generated by combining two sets of content (such as text, graphics and images), one set being constant from page to page (fixed content) and the other set being different (variable content) for every page. The combining of fixed and variable data may take place at any step in a print workflow.
Attention is drawn to the following places, which may be of interest for search:
Document retrieval systems | |
Editing, e.g. inserting or deleting |
This place covers:
All aspects of transforming the print job in order to be printed which do not fit in the sub-groups, e.g. parsing in order to eliminate repetitive data, colour transformation, font transformation.
This place covers:
Conversion or translation of the initial document or print job to a format which is not yet ready to be handled by a target printer but is useful for certain manipulation, e.g. faster to transmit, more efficient to store, easy to secure. Conversion or translation to a format which, although it could be suitable to certain printers, may not be suitable for the target printer (e.g. converting to a print format before target printer is known).
This place covers:
Parsing of print jobs written in one of the mark-up languages.
This place covers:
Conversion or translation of the initial print job (or the job in an intermediate format) to a format which is ready to be handled by the target printer.
This place covers:
Parsing of the job in order to find a certain mark (or keyword) that identify the language of the job.
This place covers:
Arrangement of the product's pages (e.g. document pages) on the output medium (e.g. paper sheets or media roll).
Attention is drawn to the following places, which may be of interest for search:
Pagination |
This place covers:
Specifically adapted to when media to be fed by the printer is of long length, e.g. web media, rolls.
This place covers:
Specifically adapted to when media to be fed by the printer is of short length, e.g. sheets (regardless of whether said media is to be folded or cut after printing. See e.g.US2010039670).
This place covers:
All aspects of configuring how the job should be printed which do not fit in the sub-groups.
This place covers:
Automatic allocation of (some) print settings by software, e.g. print driver, (on the client or server) when a print job is to be printed.
Double classification possible if G06F 3/1239 also apply.
This place covers:
Limiting the possibilities given to the user at the time of configuring print job, e.g. in b/w printer hide the option for colour printing, hide the option for double side printing if the printer does not support it or if "transparencies" is selected as media (see e.g. WO2010016234).
Comparing how the job should be printed and what the printer can offer when the job is sent from the client. Automatic adjusting of some of job's settings in order to fit the printer's settings or asking the user to solve the conflict settings manually (see e.g. EP1986410).
This group is usually combined with G06F 3/1204 or G06F 3/1208 in order to characterise the effect achieved by the "invention information".
This place covers:
Techniques for checking how the job will look like when printed either by using a preview on a display, by checks performed by software (pre-flight, pre-press) or by real print of part of the job.
This group is usually combined with G06F 3/1208 in order to characterise the effect achieved by the "invention information"
This place covers:
Previously defined settings are stored (e.g. as a template) and, when configuring a new print job, the stored settings are used instead of selecting a value for each print option.
This place does not cover:
Document templates, i.e. fixed content.. |
This group is usually combined with G06F 3/1204 in order to characterise the effect achieved by the "invention information".
This place covers:
Changing/updating of settings of a received or currently being created print job using UI of the printer.
This place covers:
Supervising of a print job after being sent for printing, e.g. printed, failed, queued. Job status can be requested (by the sending node) or received automatically after job sending.
This place does not cover:
Printer device status |
This group is usually combined with G06F 3/1207 in order to characterise the effect achieved by the "invention information".
This place covers:
Techniques relating to where and/or when the job should be printed which do not fit in the sub-groups. Queuing the jobs before printing, e.g. waiting a long job to finish. Finding a printer based on the job requirements.
This place does not cover:
Determining appropriate device aiming at providing the user with more print destinations or at installing required software for discovered devices |
This place covers:
Determining different (alternative) device for printing a job if the designated device can not print the job, e.g. due to failure, lacking of resources or excessive delay expected (see e.g. US7027169).
This place does not cover:
The same job printed by the same print device after recovered from a failure (i.e. reprinted) |
This place covers:
Combining several print jobs in one job (group job), printing print jobs in batches (e.g. jobs requiring same media or same post-processing, jobs submitted by the same user or intended for the same recipient) (see e.g.WO2008039689).
This place covers:
Changing the order of print jobs according certain priorities - either user-defined or automatically determined.
This place covers:
Determining resources to perform actions/functions on printed output (i.e. after printing) as specified by the job settings (e.g. folding, cutting, trimming, binding).
This place covers:
The print job as submitted does not comprise the document or print data that should be printed but only a reference to it or to its location (e.g. a URL, a file path). The document is later (e.g. when queuing the job or shortly before printing should commence) obtained from its location.
This place covers:
Storing a print job for a certain time before it being printed (e.g. a job to be printed at or after a certain time) or in case it should be re-printed subsequently. Storing the job until certain condition is fulfilled, e.g. user authorisation, recovering from an error state...
This place does not cover:
Normal queuing, e.g. waiting a previous job to finish.. |
This place covers:
Sending a request to print a job. The real job data will be sent or requested later. All aspects of sending a print request (e.g. submitting a document for printing, submitting a print job or a print order) which do not fit in the sub-groups.
This place does not cover:
Printing by reference |
Specific ways to send a request to print a job, e.g. scanning a page with a barcode and receiving printed pages with information identified by the barcode from a remote source.
This place covers:
Server storing user's desires about receiving printed materials, e.g. subscription, and sending personalized print jobs to all users (or users' printers) accordingly.
This place covers:
Folders with associated printing instructions (e.g. print settings or print-related tasks, such as automatic notifications). When a document or job is sent to a folder it will be processed according to the printing instructions associated with the folder.
Attention is drawn to the following places, which may be of interest for search:
Print workflow management |
This place covers:
Using the UI of the printer to configure a new job. The data for the job could be stored on the printer or at a different location, e.g. server.
This place does not cover:
Releasing a stored job according to the user identification |
Attention is drawn to the following places, which may be of interest for search:
Printing by reference |
This place covers:
Configuring and submitting a job using online based resources, e.g. accessing remote print service providers, choosing from web based content.
This place covers:
Creating, managing and using of print job history (see e.g. EP1860546).
This place covers:
Specifically instructing or managing job deletion based on certain criteria, e.g. memory usage, privacy, avoiding mixing of received jobs (see e.g. US2005275864).
This place covers:
Designing or modifying the steps to be performed to a print request from choosing document(s) to be printed to finalising the printed job (e.g. post-processing actions). Adding conditional steps, e.g. what should happen in case of certain events (see e.g.US2008170254).
This place covers:
Print workflow management is done by the driver, regardless where it resides - client or server.
This place covers:
No driver is involved in the filter pipeline. Workflow formed by pieces of software, called "filters" (see e.g. US2002135800).
This place does not cover:
Filters within a printer driver. |
This group is not used for classifying documents in it, but to introduce one of the three classification criteria mentioned in the "Special rules for classification" section of G06F 3/1201.
This place covers:
All aspects of hardware structure of the interface controller of the printer device if the "invention information" mainly focuses on them.
This place covers:
Printing from an USB stick or digital camera directly connected to the printer device.
This place covers:
Printer device having plurality of print engines in order to increase printing speed.
Attention is drawn to the following places, which may be of interest for search:
Parallel printing or parallel ripping |
This place covers:
Network configuration where the information from the server to the printer device always goes via the client.
This place covers:
Network configuration where the client accesses the server via the printer.
Attention is drawn to the following places, which may be of interest for search:
Arrangements for producing a permanent visual presentation of the output data using plotters |
This place covers:
- Interfaces between processor and display system (with or without a standard bus).
- Multiple busses connecting processor, display system and/or other subsystems: e.g. video zoom busses, multimedia busses besides the standard bus.
- Data being furnished to the display system being generated by a multiplicity of sources.
- Data of different types being furnished to the system that displays the data (it can be a display system or a complete computer).
- Interfaces between the host and the display system, especially for system that have a structure different from the structure outlined above (older or special systems).
- Plurality of symbol or graphics generators cooperating with one display unit.
- Aspects of the operating system that have impact on the display system and are not related to a particular aspect of the physical construction of the display.
- Transferring data from an Internet host to the display system.
- kvm-switches, if they (also) switch between a plurality of data sources (i.e. computers).
Data handling that is pertinent neither to the kind of visualisation unit that is used nor to the frame buffer access is to be classified in G09G 5/39.
Attention is drawn to the following places, which may be of interest for search:
Arrangements for producing a permanent visual presentation of the output data | |
Control of display in general | |
Kvm-switches, only linked to one computer as data source | |
Audio-visual communications |
When a standard bus is present, documents will be classified only if they contain details of the standard interface that are peculiar for the display system; "Non-standard" bus interfaces include all bus interfaces (SPI, LVDS, MIPI).
Attention is drawn to the following places, which may be of interest for search:
Digital output to display device involving copying of the display data of a local workstation or window to a remote workstation or window so that an actual copy of the data is displayed simultaneously on two or more displays |
This place covers:
Display devices in which more than one display unit is connected to the display system, irrespective of the type of display.
In cases where one display (device) controller controls two displays, group G09G 2360/04 should be considered for classification.
Controlling a plurality of local displays, with or without display controller: When more than one display terminal is controlled by a local host and some details of the display controller are present, this should be classified in group G06F 3/1423. The controlling of "plurality of displays" takes precedence over the "display controller" in group G09G 5/363.
Conflict between "plurality of local displays" and "conversion of CRT signals for a flat panel":
Group G09G 5/366 covers display systems with more than one display, namely the CRT and the LCD. In these cases, classification should be given in G06F 3/1423 or G06F 3/1431 or G06F 3/1438 and G09G 5/366: if the subject matter is mainly the interface, then classification in groups G06F 3/1423 or G06F 3/1431 or G06F 3/1438 is preferred; if it is the graphic controller, then symbol G09G 5/366 should be given. For search see also G09G 2360/04.
Attention is drawn to the following places, which may be of interest for search:
Using a single graphics controller | |
Using more than one graphics controller |
This place covers:
One single graphics controller (VGA, SVGA or other systems) controls two or more display units. Often one graphics controller card has interface circuitry for interfacing to CRT and to flat panel.
Documents are classified in G06F 3/1431 or G06F 3/1438 if there is a "graphics controller" present in the system, i.e. an interface between the standard bus and the display terminal that contains a graphics processor and a frame bufer. If the plurality of displays are connected to the host processor in a different, non standard, way, or if it is not possible to determine if a graphics controller is present (like for example in the old fashoned "terminals"), the documents will be classified in G06F 3/1423.
This place covers:
Illustrative example of subject matter classified in this group:
See also G09G 2300/026
This place covers:
Also screen sharing where the framebuffer is sent to remote displays, as is commonly done in application sharing (well known as Virtual Network Computing (VNC)).
Examples:
- Remote display on X-windows terminals: the rendering is done centrally, and only the modified sections of the frame buffers are sent to the remote stations. This is a case of remote local display. There is no teledisplay in this case because the remote display stations are acting as terminals of the host.
- Teledisplay: A collaborative work support system that is performed on plural computers each of which is assigned for an operator, and supports collaborative work in which the plural computers display common data and each operator operates the displayed common data through his own computer.
- Sharing of display panel information between several screens in classrooms with a white board.
Attention is drawn to the following places, which may be of interest for search:
Interaction techniques specific for application sharing, as now several users may want to interact with the same display | |
Multiprogramming arrangements; (implementation details of the sharing technique if not framebuffer based, i.e. really the inner workings, exchanged data structures | |
Office automation, groupware | |
Electronic classroom, remote teaching | |
Network arrangements for conferencing, chatrooms, etc | |
Real-time session protocols | |
Network arrangements or protocols for supporting network services or applications | |
Protocols for games, networked simulations or virtual reality | |
Telephonic multimedia conference systems | |
Videophones |
In patent documents, the following abbreviations are often used:
CSCW | Computer Supported Collaborative Work |
In patent documents, the following words/expressions are often used as synonyms:
- "Application sharing" and "Shared application"
- "Groupware" and "Computer Supported Collaborative Work"
Attention is drawn to the following places, which may be of interest for search:
Digital output to display device with means for detecting differences between the image stored in the host and the images displayed on the displays |
This place covers:
Display panels: LEDs, PDP, LCD, etc. Interconnection of POS (point of sales) terminals.
Attention is drawn to the following places, which may be of interest for search:
Data processing in buying/selling transactions, e.g. when dealing with POS terminals | |
Arrangements of circuits for control of indicating devices using static means to present variable information | |
Services or facilities specially adapted for wireless communication networks | |
Services making use of the location of users or terminals |
Attention is drawn to the following places, which may be of interest for search:
with conversion of CRT control signals to flat panel control signals |
This place covers:
General computer sound interfaces for interaction with computer programs or users
This place does not cover:
Speech processing |
Attention is drawn to the following places, which may be of interest for search:
Handling natural language data | |
Coding of audio signals in musical instruments | |
Devices for the storage of speech signals | |
Amplifiers | |
Gain or frequency control | |
Broadcasting | |
Encoding of compressed speech signals for transmission or storage | |
Spatial sound recording | |
Spatial sound reproduction |
This place covers:
Dedicated hardware or software components for interfacing to an audio device i.e. translating the audio stream from a host into a format accepted by the audio device and vice-versa. Providing hardware emulation for an audio source. Intermediation with OS when receiving audio to preserve sound quality. Connecting a host to a mobile phone to aid processing audio to enhance quality Adapting drivers to different audio source formats
Attention is drawn to the following places, which may be of interest for search:
Interfacing to a peripheral in general | |
CODECs per se |
In this place, the following terms or expressions are used with the meaning indicated:
CODEC | coding/decoding, compression/decompression of an audio signal |
This place covers:
Management from a host of the audio device by means of the interface control for modifying the operation of the audio device. Only for control of the audio device/system from the host. Controlling the audio settings such as volume, mute or filters. Controlling the audio stream path (switch output destination). Switch on or off of computer audio devices. Controlling the audio play, pause or replay.
Dedicated to TV appliances: H04N 7/00
Network security protocols H04L 9/40
Control of speech to text/text to speech conversion: G10L 13/00 and G10L 15/00
This place covers:
Interface to a computer user by means of an audio device to send commands to the computer or receive feed-back on an action. Limited to the navigation in a menu and sending control commands. Moving a mouse pointer on a screen using audio. Scrolling through a menu using audio. User interface of an audio card. Audio indicators to focus attention.
User interaction and feedback in general: G06F 3/01
User interaction in a menu in general: G06F 3/048
Speech recognition per se: G10L 15/26, G10L 15/22
This place covers:
Data format conversions; Conversion between packed and unpacked BCD.
This place covers:
Shifting which modifies the value being shifted, e.g. in arithmetic or for implementing shift instructions in processors; in particular the shifting functionality provided and the logic implementing it.
This place does not cover:
Exception handling | |
Rounding | |
Sign extension | |
Electrical details of cells | |
Digital stores in which the information is moved stepwise, e.g. shift-registers | |
Digital stores in which the information circulates |
Use of Indexing Codes:
Indexing Codes G06F 7/49905, G06F 7/49942, G06F 7/49994 are use for secondary aspects (non-invention information).
This place covers:
Details of the shifting arrangement.
This place does not cover:
Denomination or exception handling |
This place covers:
For example, barrel shifter with multiple shifting stages.
This place does not cover:
Methods or arrangements for data conversion without changing the order or content of the data handled for shifting in floating-point computations |
This place covers:
Shift registers with certain functionality and logic implementing it.
Buffer systems in general.
FIFO [First In, First Out] using linked lists.
Fifos of the types "shift-in, individual-out" or "individual -in, shift-out".
Effectuating transfer of data between different clock domains
This place does not cover:
Arrangements for changing the order of data flow |
Attention is drawn to the following places, which may be of interest for search:
Reordering based on contents of data in general | |
FIFO with priority-controlled output |
This place covers:
E.g. physical shifting of data.
This place does not cover:
FIFOs of the types "shift-in, individual-out" or "individual-in, shift-out" | |
Partitioned buffers, e.g. allowing multiple independent queues, bidirectional FIFO's | |
Shift registers per se |
This place does not cover:
Partitioned buffers, e.g. allowing multiple independent queues, bidirectional FIFO's |
Attention is drawn to the following places, which may be of interest for search:
Addressing methods of the memory |
This place covers:
E.g. signal generated / action taken before buffer runs full/empty.
This place covers:
Signal generated / action taken when buffer is already full/empty.
This place covers:
Alternating address by address, i.e. Odd-even.
Attention is drawn to the following places, which may be of interest for search:
Addressing methods of the memory |
This place covers:
The methods and arrangements in this main group are one level above logic circuits.
Examples of such methods and arrangements are: arithmetic circuits implemented using basic logic gates, implementation of complex logic gates, and implementation at transistor level, specially designed for arithmetic operations.
Other examples are:
Logical operations on words per se;
Finite state machines;
Grey System Theory (method of handling uncertainty),
- Asynchronous digital pipeline = clock-less operation of logical operations.
This place does not cover:
Logic circuits, i.e. Implementation of basic logical circuits (AND, NAND, OR, NOR, EXOR, EXNOR), at transistor level |
Attention is drawn to the following places, which may be of interest for search:
Logical operations on words in combination with arithmetic operations | |
Arrays of processors with common control | |
Information retrieval, or database structures therefor | |
Conversion between different representations of Boolean functions, e.g. Boolean formula synthesis from Karnaugh maps, generation of Reed-Muller expansions | |
Complex mathematical operations |
Documents classified in G06F 7/00 should also be further classified in the appropriate indexing codes G06F 2207/00 - G06F 2207/7295.
In this place, the following terms or expressions are used with the meaning indicated:
Individual record carriers | Designates physically distinct carriers carrying digital information, e.g. sheets, cards. |
This place covers:
For example, bit string matching, character string matching.
This place does not cover:
Arrangements for sorting, selecting, merging or comparing data on individual record carriers | |
Arrangements for sorting or merging computer data on continuous record carriers, e.g. tape, drum, disc | |
Methods or arrangements for performing computations using exclusively denominational number representation, e.g. using binary, ternary, decimal representation |
Attention is drawn to the following places, which may be of interest for search:
Information retrieval | |
Comparing pulses |
This place covers:
Magnitude comparison generating less-than, greater-than, equal-to signals.
Attention is drawn to the following places, which may be of interest for search:
Min or max functions producing one of the two input values |
In this place, the following terms or expressions are used with the meaning indicated:
Window comparator | determines in which window defined by multiple values a certain value falls |
Attention is drawn to the following places, which may be of interest for search:
Sorting of postal letters | |
Conveying record carriers from one station to another |
This place covers:
Classification of digital data.
Maximum, minimum or median value of a set of data.
Attention is drawn to the following places, which may be of interest for search:
Minimum or maximum of two values | |
Pattern recognition |
In patent documents, the following words/expressions are often used as synonyms:
- "Batcher sorter" , "bitonic sorter" and "odd-even merge"
This place covers:
E.g. documents on number representations without dealing with the technical circuit implementation.
This place does not cover:
Using signed-digit representation |
Attention is drawn to the following places, which may be of interest for search:
With a look-up table | |
Complex mathematical operations |
This place covers:
Generation or transformation of stochastic functions; generation of output with certain random characteristics; post processing, e.g. pattern elimination, whitening, reducing auto-correlation or bias; breakdown detection.
Attention is drawn to the following places, which may be of interest for search:
Transformation of stochastic functions by table look-up | |
Lottery apparatus | |
Random pulse generators, random bit generators | |
Secret telegraphic communication |
Random bit generators: In case of a bit sequence, which could be seen as a random number sequence, classification is done both in the appropriate (sub)group in G06F 7/58 and in H03K 3/84.
Methods both valid for random and pseudo-random number generators should be classified in the head group (G06F 7/58) and not in a sub-group, even if a specific PRNG/RNG is discussed.
Double classification head group / main group only
- on basis of other aspects, e.g. possibly non-trivial PRNG or RNG also disclosed
- in case it is not sure that the method is valid for both RNG and PRNG
Use of keywords
Pseudo-random number generators i.e. only deterministic PRNGs;mixed RNGs in G06F 7/588 if more than one type of pseudo-random number generator is discussed:- in case these PRNGs are clearly trivial: classify in head group ( G06F 7/582 ) - in case a PRNG might be non-trivial: classify in relevant sub-group(s) | |
Using finite field arithmetic, e.g. using a linear feedback shift registergenerators including the 2**n state with all zeroes in G06F 7/582 | |
Random number generators, i.e. based on natural stochastic processes also mixed PRNG/RNGs Considered as random (G06F 7/588 ) are methods based on - radioactivity, zener, race, chaos- uncertain moment of pressing a key | |
Using non-contact-making devices, e.g. tube, solid state device; using unspecified devicese.g. 2's complementing | |
Using coordinate rotation digital computer (CORDIC)i.e. CORDIC in non-complex environment: G06F 7/5446 | |
Using signed-digit representationBinary multipliers and dividers often use signed-digit representation internally for one operand or the result; see therefor "recoded" or "Booth" multipliers in G06F 7/523 - G06F 7/5338 and "recoded" or "SRT" dividers in G06F 7/535 - G06F 7/5375. | |
Computations with numbers represented by a non-linear combination of denominational numbers, e.g. rational number, logarithmic number system, floating-point numbers (conversion to or from floating-point codes H03M 7/24) ( G06F 7/4806, G06F 7/4824, G06F 7/49, G06F 7/491, G06F 7/544 take precedence)e.g. fused multiply add (FMA) also here, but add G06F 7/5443 | |
Logarithmic number system mainly for non-trivial operations such as addition.multiplication of binary operands via the log-domain is in G06F 7/5235 | |
Adding; Subtracting (G06F 7/4833 takes precedence)e.g. floating-point addition | |
Dividingi.e. floating-point division | |
Multiplying i.e. floating-point multiplication If in fact only the mantissa-multiplication is treated, classification should be made in another group, unless special features for switching between fixed and floating point operands are described. | |
Computations with a radix, other than binary, 8, 16 or decimal, e.g. ternary, negative or imaginary radices, mixed radix (non-linear PCM, G06F 7/4824 takes precedence) N-ary logic | |
Multiplying; Dividing MULTIPLICATION ONLY division goes into G06F 7/4915, whether it uses 8421 code or not | |
Mantissa overflow or underflow in handling floating-point numberse.g. exponent adjustment | |
Normalisation mentioned as feature only 'i.e use of normalisationImplementation of floating-point normalisers: G06F 5/012 | |
Significance controli.e. number of significant bits | |
Implementation of IEEE-754 StandardNote: The standard uses sign magnitude representation | |
Rounding to nearest (G06F 7/49957 takes precedence)Note: The IEEE-754 way is "rounding to nearest even", which is rounds to nearest, and only when exactly in the middle to nearest even. Though rounding to nearest odd may in fact round to an even number, it normally doesn't. | |
Rounding towards zero (G06F 7/49957 takes precedence)e.g. as in IEEE-754 | |
Rounding away from zeroway of rounding not provided for in IEEE-754 | |
Interval arithmetici.e. computations with intervals as values | |
Adding; Subtracting (G06F 7/4806, G06F 7/4824, G06F 7/483 - G06F 7/491, G06F 7/544 take precedence) only binary, radix 8, radix 16.. | |
using carry switching, i.e. the incoming carry is connected directly to the carry output under control of a carry propagate signal Full adders having in general the form1-bit adder stages (ripple carry) | |
with simultaneous carry generation for or propagation over two or more stages e.g. using group carry signals, e.g. carry skip; all smart carry schemes except carry look-ahead and carry select/ conditional sum are in G06F 7/506 | |
using selection between two conditionally calculated carry or sum values e.g. carry select, conditional sum | |
for multiple operands, e.g. digital integrators i.e. operand-parallel addition of 3 or more operands (this is mainly "3" or "a lot");multipliers in G06F 7/52 | |
word-serial, i.e. with an accumulator-registeri.e. OPERAND serial! | |
Multiplying; Dividing (G06F 7/4806, G06F 7/4824, G06F 7/483 - G06F 7/491, G06F 7/544 take precedence) very rare cases only; normally documents are classified in one of the subgroups (or both) This subgroup does not cover G06F 7/5443: multiplier-accumulators (f = ∑ ai xi ), including simple cases f = ax + b, f = ax+ by G06F15/347: vector multipliers, matrix multipliers G06F 7/68: binary rate multipliers/dividers G06F 7/724: finite field multipliers | |
In serial-parallel fashion, i.e. one operand being entered serially and the other in parallel (G06F 7/533 takes precedence) In old documents these multipliers are often called "parallel", in newer documents they are often called "serial"! | |
with row-wise addition of partial products i.e. adding two rows each cycleIn majority: "add to accumulator and shift" | |
In parallel-parallel fashion, i.e. both operands being entered in parallel (G06F 7/533 takes precedence) e.g. single cells for cellular array multiplierse.g. arrays of undetermined type | |
Using indirect methods, e.g. quarter-square method, via logarithmic domainif operands stay in the log-domain then G06F 7/4833 ;quarter-square see XP013079891 | |
in serial-serial fashion, i.e. both operands are entered serially (G06F 7/533 takes precedence) e.g. Lyon multipliers (see XP007901470) | |
with row-wise addition of partial productsi.e. adding two rows each cycle | |
with column-wise addition of partial productse.g. adding one column each cycle with a parallel counter | |
In parallel-parallel fashion, i.e. both operands being entered in parallel (G06F 7/533 takes precedence) e.g. single cells for cellular array multipliers;e.g. arrays of undetermined type | |
With row-wise addition of partial products (G06F 7/5324 takes precedence) cellular array multipliers with ripple carry (=within rows) also skewed arrays of the type "McCanny & McWhirter"e.g. linear chain of cascaded adders | |
With column-wise addition of partial products, e.g. using Wallace tree, Dadda counters (G06F 7/5324 takes precedence)e.g. adder trees | |
Partitioned, i.e. using repetitively a smaller parallel-parallel multiplier or using an array of such smaller multipliers each smaller multiplier larger than 1 bit; multiprecision; also array multipliers A) n × m bit multiplier consisting of an array of k × l multipliers, k being a submultiple of n and l being a submultiple of m respectively, followed by an array or tree of adders, e.g. of Wallace type. B) n × m bit multiplication realised by a single k × l multiplier, k and l as above, used repetitively and followed by an accumulator.The k × l bit multipliers may be single ROM's for example.Not to be confused with multi-bit-scanning, where a selection among precalculated multiples of the multiplicand is made; if the k × l bit multipliers itself are of the latter type, double classification may be appropriate. | |
Reduction of the number of iteration steps or stages, e.g. using the Booth algorithm, log-sum, odd-even for Booth, use the subgroups!Note: the term "Booth" is often incorrectly used when intending to say "modified Booth". A Booth recoder module inputs some, e.g. two, consecutive bits and sends a 'Booth carry' to a more significant module. A modified Booth recoder module inputs some, at least three, consecutive bits, the most significant of which is also input to the next higher recoder module. In modified Booth the recoder modules are not connected to each other via a carry. | |
By skipping over strings of zeroes or ones, e.g. using the Booth Algorithme.g. using operand processing, e.g. simple (radix-2, 1st order) Booth, also canonical recoding to NAF form (sequential recoding with carry) | |
By using multiple-bit-scanning, i.e. by decoding groups of successive multiplier bits in order to select an appropriate pre-calculated multiple of the multiplicand as a partial product i.e. processing multiple bits per iteration (radix > 2) without overlap, e.g. using positive precalculated multiples only groups of MR-bits are decoded for selecting multiples of MD e.g. 2-bit groups: 3-bit groups: 00 0 × MD 000 0 × MD 01 1 × MD 001 1 × MD 10 2 × MD 010 2 × MD 11 3 × MD 011 3 × MD 100 4 × MD 101 5 × MD 110 6 × MD 111 7 × MDMultiples,that are not a power of 2(3x,7x, etc)have to be precalcultated or looked up in a table. | |
Each bitgroup having two new bits, e.g. 2nd order MBAi.e. radix-4 modified Booth, i.e. 2nd order modified Booth | |
Reduction of the number of iteration steps or stages, e.g. using the Sweeny-Robertson-Tocher (SRT) algorithm (not used, see G06F 7/535 or G06F 7/5375 )NOT USED, non-restoring in general gets the KW non-restoring,SRT in particular goes in G06F 7/5375 | |
Non restoring calculation, where each digit is either negative, zero or positive, e.g. SRT; (WARNING Not complete. Provisionally see G06F 7/535 + G06F 7/5375) almost empty - everything is in Indexing Code G06F 7/5375 | |
For evaluating functions by calculation (with a look-up table G06F 17/10; complex mathematical operations G06F 17/10; G06F 7/4806, G06F 7/4824 take precedence) e.g. min, max of two operands, absolute value, (sum of) absolute differencefinding a maximum value of a set (e.g. during sorting) is in G06F 7/22; direct table lookup of function values is in G06F 1/03 ;table lookup of coefficients during computation goes here, put "table lookup" in the TXT field; | |
Sum of products (for applications thereof, see the relevant places, e.g. G06F 17/10, H03H 17/00) e.g. MACs; fused multiply add (FMA) for floating point are in G06F 7/483 with G06F 7/5443 | |
using crossaddition algorithms, e.g. CORDIC e.g. sin, cos, tan, sinh, cosh, tanh;CORDIC on complex numbers: G06F 7/4818 | |
Powers or roots, e.g. Pythagorean sumse.g. powers by multiplying the operand by itself (which is not possible with non-integer powers) | |
Arithmetic logic units (ALU), i.e. arrangements or devices for performing two or more of the operations covered by groups G06F 7/483- G06F 7/556 or for performing logical operations (instruction execution G06F 9/30; G06F 7/49, G06F 7/491 take precedence; logic gate circuits H03K 19/00)e.g. arrangements for performing more than one operation using the same circuitry | |
Basic arithmetic logic units, i.e. devices selectable to perform either addition, subtraction or one of several logical operations, using, at least partially, the same circuitry: Note: multiplication is not seen as "basic" |
This place covers:
For example, documents concerning
- "permutograph";
- a "Negationsnetz";
Fibonacci code representation.Further details of subgroups
using difunction pulse trains (STEELE computers); phase computers (GAINES). e.g. Delta-Sigma sequences.
number-of-ones counters, i.e. devices for counting the number of input lines set to ONE among a plurality of input lines, also called bit counters or parallel counters (for applications thereof, see the relevant places, e.g. G06F 7/49, G06F 7/5013, G06F 7/509, H03M 1/00, H03M 7/20)
e.g. number of ones counters (parallel counters), compressors, carry save adders 4-2, 7-3, etc, e.g. used in multipliers.
Digital differential analysers, i.e. computing devices for differentiation, integration or solving differential or integral equations, using pulses representing increments; Other incremental computing devices for solving difference equations (G06F 7/70 takes precedence; differential analysers using hybrid computing techniques G06J 1/02) DDA application in numerical control G05B 19/18.Integration per se: G06F 17/10.
Using pulse rate multipliers or dividers pulse rate multipliers or dividers per se (G06F 7/70 takes precedence) (frequency division in electronic watches G04G 3/02; frequency multiplication or division in oscillators H03B 19/00; frequency dividing counters per se H03K 23/00 - H03K 29/00)
e.g. phased locked loop (PLL) with digital divider (thus achieving pulse rate multiplication); PLLs in general are in H03L 7/06;
pulse rate doubling by adding delayed pulses and correcting the duty cycle are in H03K 5/1565; H03K 23/00 - H03K 29/00 mostly relate to analogue aspects.
This place covers:
A mod N, modulo addition, modulo subtraction
Further details of groups
Covers for e.g. modular division; both with composite moduli and in prime number fields.
This subgroup covers RSA [Rivest–Shamir–Adleman ] cryptosystem in general.
Covers mainly (binary) extension fields; prime number fields using modular arithmetic are covered in G06F 7/72 - G06F 7/723, G06F 7/727 and G06F 7/728.
For this type of arithmetic the term "Galois field" and symbols of the type GF(pn) are characteristic, e.g. GF(24).
Elliptic curve cryptography [ECC] is classified in this subgroup only if specific adaptations for elliptic curves are present.
This subgroup covers rational functions p(x)/q(x) for example and inversion in extension fields is covered in G06F 7/726.
Montgomery reduction involves adding of multiples of the modulo, followed by right shifting.
This subgroup covers the Chinese Remainder Theorem for non-RSA for example.
A residue number system (RNS) is a system in which a number is represented by a series of digits, each of which is the remainder of that number with respect to a different modulus mi:
e.g.: moduli -> 5 3 2
2610 = 1 2 0
The maximum number representable is M = (∏i mi) - 1
e.g.: (2 × 3 × 5) - 1 = 29 in the above case.
Attention is drawn to the following places, which may be of interest for search:
Error detection/correction in computers | |
Optical residue arithmetic devices | |
Error detection/correction for coding in general | |
Error detection/correction in transmission | |
Secret communication |
This place covers:
E.g. leading zero anticipation LZA, priority encoders.
With shifting (during/for detection) details: also in G06F 5/01.
This place does not cover:
with shifting |
This place covers:
For example, masking, shuffling
G06F 7/766 covers i.e. serial or parallel generation of all permutations.
G06F 7/768 covers e.g. endian conversion.
Boolean masking in block or stream ciphers is covered by H04L 2209/04.
Endian conversion by memory addressing is covered by G06F 12/04.
Bus coupling with endian conversion and endian conversion instruction are covered by G06F 13/4013.
This place covers:
LIFO [Last In, First Out], also called stack or pushdown store:
- Reversal of a train of data words.
- Reversal of a train of data bits.
Devices called FIFO [First In, First Out], but having possibilities to extract also other data items than the first one.
Matrix transportation devices.
Other devices with an output sequence different from the input sequence, but independent of the contents of the data.
Attention is drawn to the following places, which may be of interest for search:
FIFO-devices | |
Reordering based on contents of data, e.g. sort key | |
Cache-memories | |
FIFO with priority-controlled output |
This place covers:
The engineering discipline of creating software and the assistance of computer tools (CASE tools) in exercising the task of software engineering.
The phases, covered by G06F 8/00, range from the initial requirements collection up to and including the delivery of software to the end user, its maintenance and management but exclude the phase of testing and debugging.
Aspects of the particular application of the software being designed, e.g. commercial or financial software, are classified in the appropriate place.
This place does not cover:
Testing or debugging | |
Administrative, planning or organisation aspects of software project management |
Attention is drawn to the following places, which may be of interest for search:
Execution of a stored program | |
Hardware/software co-design |
In patent documents, the following abbreviations are often used:
CASE | Computer-Aided Software Engineering |
This place covers:
Capturing and formalising user requirements:
- Graph notations;
- Diagramming techniques, e.g. Dataflow diagrams;
- Requirements specifications;
- Use of modelling languages such as uml;
- Petri nets.
Attention is drawn to the following places, which may be of interest for search:
Circuit design | |
Specification of network protocols |
In patent documents, the following abbreviations are often used:
UML | Unified Modeling Language |
This place covers:
Software design, including the determination of the main structure, the modules that will be created and the relationships between them.
The use of design patterns for object-oriented development.
Attention is drawn to the following places, which may be of interest for search:
Computer-aided design in general |
In patent documents, the following abbreviations are often used:
MVC | Model-View-Controller |
This place covers:
The conventional design paradigm, where a design is defined in terms of a sequence of actions to be performed. An example is the Jackson Structured Programming method.
Attention is drawn to the following places, which may be of interest for search:
Declarative |
This place covers:
The process of planning a system in terms of interacting objects for the purpose of solving a software problem as defined by the (formalised) user requirements. Examples are the design patterns from the book "Design Patterns: Elements of Reusable Object-Oriented Software" by Gamma et al.
Attention is drawn to the following places, which may be of interest for search:
Object-oriented method resolution | |
Inheritance | |
Object-oriented databases |
This place covers:
The conceptual step of converting an abstract representation (design or specification) of a software system, into a more concrete representation in the form of program code.
Attention is drawn to the following places, which may be of interest for search:
Specification techniques for generating programs | |
Compilation, i.e. the process of converting source code into binary code during the task of software engineering | |
Reverse engineering; Extracting design information from a source code | |
Porting source code to a different environment | |
Query generation in information retrieval |
This place covers:
Programming languages and paradigms that can be used by a programmer in order to create source code.
Attention is drawn to the following places, which may be of interest for search:
Processing or translation of natural language |
In patent documents, the following abbreviations are often used:
HLL | High Level Language |
This place covers:
Languages designed for functional programming that treats computation as the evaluation of mathematical functions. Examples are Sasl, Miranda and Haskell.
In this place, the following terms or expressions are used with the meaning indicated:
Functional programming | software development model which expresses algorithms as functions, i.e. as stateless mappings of input values to output values |
Declarative programming | programming paradigm that expresses a computation without describing its control flow |
This place covers:
List processing languages, e.g. Lisp and Scheme.
In this place, the following terms or expressions are used with the meaning indicated:
CAR | Function that determines the first element of a list |
CDR | Function that determines the list after its first element |
This place covers:
Programming languages expressing a program as a collection of logical statements.
In this place, the following terms or expressions are used with the meaning indicated:
Declarative programming | programming paradigm that expresses a computation without describing its control flow |
Horn clause | logical statement |
In this place, the following terms or expressions are used with the meaning indicated:
Unification | finding an assignment that satisfies all clauses |
Backtracking | done on partial unifications that cannot succeed, and to continue to find more possible unifications |
This place covers:
Programming languages having constructs for expressing parallelism, e.g. Occam.
This place does not cover:
Parallel logic programming | |
Detecting and extracting parallelism from program code |
This place covers:
Programming languages expressing algorithms as interacting objects, where an object is an aggregation of data (attributes) and actions (methods).
Examples of object oriented languages are Smalltalk, Ruby, Eiffel, C++, C#, Java, Oberon, Modula.
Attention is drawn to the following places, which may be of interest for search:
Object-oriented design paradigms | |
Object-oriented systems | |
Method invocation | |
Distributed object-oriented systems | |
Object-oriented databases |
In this place, the following terms or expressions are used with the meaning indicated:
Method | the action to be performed on (attributes of) an object |
This place covers:
Programming paradigm allowing different, orthogonal, aspects of a program (business rules, security, fault tolerance, data consistency) to be designed independently and to be merged later to produce a final source code product.
Aspect-Oriented Software Development foresees a full and independent design for all the secondary aspects of an application like security, persistency, synchronization, logging, etc., carried out at the same time as the design of the core functionality of the application.
In this place, the following terms or expressions are used with the meaning indicated:
Aspect Weaving | the process of merging the different aspects |
Join Points | the actual places in the program where the aspects are merged |
In patent documents, the following abbreviations are often used:
AOSD | Aspect oriented software development |
This place covers:
Intelligent editors that help a programmer to write programs, e.g. language-sensitive editors.
Examples:
- Proposing a closing bracket when an opening bracket is typed.
- Indenting of if-then-else statements.
- Verification of entered text (e.g. whether variables are already declared).
Attention is drawn to the following places, which may be of interest for search:
Text processing |
This place covers:
P programming techniques whereby a program is created by handling graphical programming objects representing programming constructs/statements rather than writing program text.
Attention is drawn to the following places, which may be of interest for search:
Use of icons for interaction | |
Intelligent editors | |
Development of GUIs, User Interface Management Systems (UIMS) | |
Web page development | |
Creating programs for controlling physical processes by graphically specifying the process to be controlled | |
Creating relay ladder logic program for Programmable Logic controllers (PLC) | |
Multimedia authoring |
This place covers:
Automatically generating program code (source code) from a specification/definition/model of what the program should do.
Typical examples: WO0108007, WO02086704, EP0737918, WO0177882.
Specific topics included:
- Generating a debugger from a formal specification: EP1071016;
- Generation of source code for web applications: WO0171566;
- Convert spreadsheet data into source code: US2003106040, US2004064470;
- Generate source code from XML: US2003167444;
- Generate a shader program from a graphics file: US2003179220;
- OMG's Model driven architecture (MDA).
In patent documents, the following abbreviations are often used:
MDSD | Model driven software development |
MDA | Model driven architecture |
This place covers:
Arrangement for keeping a model and the corresponding program code in sync when applying changes to any of them.
This place covers:
- Storing and retrieving reusable software modules into and from software repositories;
- Building, searching and maintaining software repositories containing reusable software parts;
- Managing repositories of software components, objects;
- Storing software components into a repository, thereby indicating additional information about the components, e.g. the function performed, what inputs are required, what outputs are generated;
- Querying the repository to retrieve components that satisfy the particular requirements, e.g. related to its function;
- Detecting program parts that are candidates for reuse;
- Design patterns.
- Using APIs and interfaces, e.g. for components, to make software reusable.
Attention is drawn to the following places, which may be of interest for search:
Exlining, i.e. finding similar sequences of code to replace them with a procedure invocation | |
Version control using repositories | |
Code clone detection, i.e. detection of identical pieces of code for the purpose of maintenance | |
Plagiarism detection in program code |
This place covers:
- Automatically generating a compiler or parser based on a specification of a grammar/syntax, e.g. Lex and Yacc.
- Generation of lexical analyzers.
Attention is drawn to the following places, which may be of interest for search:
Compilation per se |
In this place, the following terms or expressions are used with the meaning indicated:
Compiler Bootstrapping | creating a compiler using the language it is intended to compile |
This place covers:
The development and generation of source code for user interfaces, in particular GUIs.
Attention is drawn to the following places, which may be of interest for search:
User interaction with graphical user interfaces | |
Details relating to the actual functioning of (graphical) user interfaces |
This place covers:
The transformation of program code from one form into another.
This place covers:
The process of converting source code into binary code.
Attention is drawn to the following places, which may be of interest for search:
Compiler generators | |
Runtime code conversion |
In this place, the following terms or expressions are used with the meaning indicated:
Binary code | a representation of a code understood by a machine |
This place covers:
Determining grammatical structure of the source code with respect to a given formal grammar.
This place covers:
Processing language-external elements, e.g. compiler directives, macro definitions and macro expansions, and inclusion of library source files.
This place covers:
Converting sequences of characters into tokens, skipping comments.
This place covers:
Checking for correct syntax and building a data structure, e.g. parse tree.
Multibox parsers.
Attention is drawn to the following places, which may be of interest for search:
Parser generators | |
Parsing markup language streams |
This place covers:
Checking context-senstive conditions, e.g. whether variables have been declared.
This place covers:
Determining the dependencies between different program parts (e.g. data dependencies, which variables/values are used in expressions, and control dependencies, which statements have influence on other statements), in particular to determine whether such program parts should be placed in a certain order.
This place covers:
Determining whether references, e.g. pointers, reference variables and indexed array elements, actually refer to the same underlying memory element.
This place covers:
Checking semantic conditions which can be determined without actual execution of the program, e.g. whether variables are initialized.
This place covers:
Checking type compatibility of values, variables, parameters and expressions.
This place covers:
Generating an executable implementation of the program for the target machine architecture, usually via an internal form that is independent of the source programming language and that is also independent of the target machine architecture.
This place covers:
Assigning logical registers to variables, assigning physical register to logical registers, coalescing, spilling.
In this place, the following terms or expressions are used with the meaning indicated:
Coalescing | removing useless copy instructions from a program. This needs information about assigned registers and therefore it is commonly performed as a subtask of register allocation besides spilling and register assignment. |
This place covers:
Optimisation of the program code; the program code can take any form e.g. source code, assembly code, machine code.
Attention is drawn to the following places, which may be of interest for search:
Code refactoring |
Whenever an optimisation concerns speed, size, etc, such documents should be classified in the corresponding subgroups. In this group should be classified only special optimision techniques not present in any of the subgroups.
Contains optimizations that do not involve a trade off between different factors (speed, size, energy consumption | |
Involve a trade-off. They are specifically aimed to optimize one aspect, likely at the cost of another aspect. |
This place covers:
Optimisation methods specifically aimed at reducing the energy consumption of program code.
Attention is drawn to the following places, which may be of interest for search:
Means for Saving Power, Power Management strategies |
This place covers:
Optimisation methods specifically aimed at reducing the size of the program code, e.g. by replacing sequences of recurring instructions with a new macro instruction/superinstruction. Requires that the target architecture/virtual machine recognize this new instruction; Cross jumping; Tail Merging.
Attention is drawn to the following places, which may be of interest for search:
Data compression (e.g. PKZIP) |
Note that this group does not cover the compression of program code, which requires a decompression before it can be executed. Compression of program code in this sense does not result in the actual program being smaller; there is only a saving in the secondary storage or transmission via the network.
In contrast, the size-reduced code covered by this group is directly executable, so no decompression is needed before execution.
This place covers:
Detecting and removing of dead or redundant code. Redundancy elimination optimizations avoid repeated computation of the same value by computing the value once, saving it in a temporary variable, and reusing the value from the temporary variable when it is needed again. Examples of redundancy elimination optimizations include common subexpression elimination, loop invariant code motion and partial redundancy elimination.
In this place, the following terms or expressions are used with the meaning indicated:
Dead code | code that is never executed or that is unreachable. |
Redundant code | code that produces results that are never used or are irrelevant to the program execution or code that computes values that were already computed before. |
This place covers:
Detecting recurring sequences of instructions and replacing each of them with a call to a procedure/function that contains those instructions.
Attention is drawn to the following places, which may be of interest for search:
Reuse, i.e. identifying recurring pieces of code for purposes of reuse | |
Inlining | |
Code clone detection, i.e. detection of identical pieces of code for the purpose of maintenance | |
Plagiarism detection in a source code |
This place covers:
Optimisation methods specifically aimed at improving the execution speed of the program.
This place covers:
Avoiding cache misses at run-time. Cache can be instruction or data cache.
Splitting a program into frequently used and not frequently used parts (hot and cold parts) and keeping the hot parts in the cache.
Rearranging the individual instructions in order to have data/instructions present in the cache when they are needed.
This place does not cover:
Cache prefetching |
This place covers:
Replacing a procedure invocation with the instructions of the procedure, thus removing the cost of procedure invocation.
Attention is drawn to the following places, which may be of interest for search:
Exlining |
This place covers:
Increasing the Instruction Level Parallelism (ILP) that can be exploited by the hardware at run-time (pipelines, superscalar processors executing multiple instruction streams). Typically this is done by reordering the instructions (scheduling).
This place does not cover:
Exploiting coarse grain parallelism | |
Run-time scheduling or reordering of instructions by the hardware | |
Process scheduling |
In this place, the following terms or expressions are used with the meaning indicated:
Scheduling | reordering of instructions |
In patent documents, the following abbreviations are often used:
ILP | Instruction Level Parallelism |
This place covers:
Reducing or avoiding run-time pipeline stalls.
Pipeline stalls (or bubbles) are caused by control hazards – e.g. branches -, data hazards -one instruction depends on the result of another instruction and must wait for this instruction to finish- or resource hazards -there are not enough resources to serve all the instructions currently in flight - instructions must wait for resources to be freed in order to be fed to the pipeline.Control Hazards can handled by static branch-prediction, speculative execution or delayed branch. Data Hazards can be avoided by rearranging the instructions so that instructions that depend on each other's result are farther separated.
In a pipeline, there is only one instruction stream. So the parallelism consists in the overlapping of the instructions of the stream rather than executing the instructions of 2 streams simultaneously.
Attention is drawn to the following places, which may be of interest for search:
Hardware aspects of pipelining |
This place covers:
Software pipelining, e.g. Modulo Scheduling, transforms a loop described in a high-level programming language, such as C or FORTRAN, in such a way that the execution of successive iterations of the loop are overlapped rather than sequential. This technique exposes the instruction level parallelism (ILP) available between successive loop iterations to the compiler and to the processor executing the transformed code.
Attention is drawn to the following places, which may be of interest for search:
Hardware aspects of pipelining |
This place covers:
Generation of executable code from the optimized compiler-internal representation of the source code, taking the target machine architecture into account.
Attention is drawn to the following places, which may be of interest for search:
Run-time compounding of instructions by the hardware |
This place covers:
Speeding up the execution of a single task by subdividing the task into a plurality of subtasks and having the subtasks executed simultaneously on different processors. The subtasks are interdependent and they work together to achieve the same goal as the original task.
Attention is drawn to the following places, which may be of interest for search:
Exploiting fine grain parallelism |
This place covers:
Distributing the code of each of the subtasks to the available processors.
This place does not cover:
Considering CPU load at run-time | |
Load rebalancing |
This place covers:
Distributing iterations of parallelizable loops among the processors.
Attention is drawn to the following places, which may be of interest for search:
Software pipelining | |
Allocation of resources to service a request | |
Techniques for rebalancing the load in a distributed system at run-time |
This place covers:
Dividing the data used by the subtasks over the different processors.
This place covers:
Ensuring data consistency between subtasks.
This place does not cover:
Cache consistency protocols in hierarchically structured memory systems |
This place covers:
Detecting parallelism in sequential programs, e.g. by making use of control flow and data flow information.
In this group the burden to detect and extract parallelism is put on the compiler or another software tool. This contrasts with the G06F 8/314, where the burden of indicating parallelism is put on the programmer.
Attention is drawn to the following places, which may be of interest for search:
Techniques and language constructs to create parallel programs | |
Data flow analysis, control flow analysis |
This place covers:
Communication between subtasks, allowing the generated tasks to interact with each other, for example to pass parameters or to return results.
This place does not cover:
Communication between independent tasks |
This place covers:
Synchronisation between subtasks.
This place does not cover:
Synchronisation between independent tasks |
This place covers:
Compiler structure allowing for several source languages (multiple front ends) and/or several target machine architectures (multiple back ends). Some examples of techniques and compilers for this are:
- Architecture Neutral Data Format (ANDF);
- UCSD Pascal P-code;
- Universal Compiler Language (UNCOL);
- GCC - GNU Compiler Collection.
Attention is drawn to the following places, which may be of interest for search:
Generating code for just one computing platform |
In this place, the following terms or expressions are used with the meaning indicated:
Retargetable compiler | a compiler that can relatively easily be modified to generate code for different CPU architectures. |
This place covers:
Specializing a program for some or all of its possible input values.
Different flavours are:
- "normal" PE (partial evaluation): specialize program for certain values of its inputs
- "predictive" PE: predict the run-time values of some inputs and specialize the program accordingly. At run-time, check if the prediction was correct. If yes, execute it. If no, recompile using the actual values.
- "multi-version" PE: generate multiple specialized versions of the program corresponding to different inputs. At run-time choose the appropriate version.
- "placeholder" PE: specialize the program for the known inputs. For the unknown inputs, provide placeholders, that will be filled in at run-time.
Attention is drawn to the following places, which may be of interest for search:
Optimizing a method invocation based on the type of the receiving object |
This place covers:
Translating program code from a first high level programming language to a different second high-level programming language (e.g. from Java to C++). This transformation is independent of the target processor.
Attention is drawn to the following places, which may be of interest for search:
Source to binary translation | |
Preprocessors | |
Optimisation of source code | |
Binary to binary translation | |
Porting; modifying the source code of the application in order to adapt it to new/changed requirements | |
Porting source code to a different environment |
This place covers:
Static translation (i.e. pre-run-time) of binary code from one architecture to a different architecture.
This group covers the following forms of static binary code translation:
- Binary to binary
- Intermediate bytecode to another intermediate bytecode (e.g. Java bytecode, p-code)
This place covers:
Transformation of executable code into source code or assembly code.
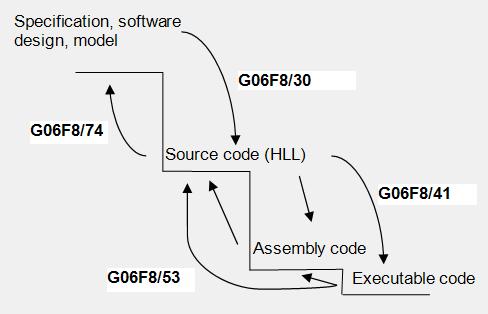
Attention is drawn to the following places, which may be of interest for search:
Reverse engineering | |
Protecting software against software analysis or reverse engineering, e.g. by code obfuscation |
This place covers:
Statically linking modules before load-time in order to create executable binary code.
Attention is drawn to the following places, which may be of interest for search:
Dynamic linking, i.e. linking at or after load time, during run-time |
This place covers:
- Installation and updating of computer software
- Methods that make the installation/update of software program transparent, automatic and user-friendly, both to the end-user and the network administrator. Methods that automatically select which programs should be updated, when and how this should happen, and where old and new programs should be located
Updating or installing software based on physical location of the target device.
Attention is drawn to the following places, which may be of interest for search:
Installation and upgrade of device drivers | |
Network booting | |
Program loading or initiating | |
Fault tolerant update or installation. For example when an error occurs during software upgrade, the system is rebooted and restored to the state before installation. | |
Secure aspects of licensing; Try and buy software | |
Arrangements in connection with the implantation of stimulators; Changing the program; Upgrading firmware | |
Downloading information (also software) into vehicles | |
Personalization of smart card applications | |
Download/install/upgrade software in mobile communication devices | |
Multimedia set-top boxes under program control |
This place covers:
- First-time installation of software.
- Unattended installation, installation scripts (answer file).
- Installation packages (containing list of files, program image, files itself, install/update instructions).
- Network installation plans.
- Type of installations.
- Silent installation - no display of the progress of the installation.
- Unattended installation - installation performed without user interaction.
- Self installation - unattended installation without the need of initial launch of the process.
- Headless installation - installation performed without using a monitor connected to the destination computer.
- Clean installation - cleaning up a destination partition (formatting) before actual installation.
- Flat installation - first copying installation files from a media to a hard disk and then installing them from the hard drive.
- Network installation - installation of a program from a shared network drive.
- Virtual installation - performing a virtual installation to check for errors before committing the real installation.
Attention is drawn to the following places, which may be of interest for search:
Loading of device drivers |
In this place, the following terms or expressions are used with the meaning indicated:
Installation | setup, deployment |
This place covers:
Removing software and all its related components.
Uninstallation of software i.e. removing software and all its related components, without interfering with the operation of other software;
Undoing installations/update.
Rollback, reverting to a previous installation/update status. Requires the use of some kind of log file.
Attention is drawn to the following places, which may be of interest for search:
Unloading program code from executable memory | |
Garbage collection |
This place covers:
Installation of whole systems by copying disk images to target systems,
Cloning installed systems.
Attention is drawn to the following places, which may be of interest for search:
Software billing |
In patent documents, the following abbreviations are often used:
BTO | Build to order |
MTO | Make to order |
This place covers:
Installation or update explicitly taking into account hardware characteristics of the target.
Attention is drawn to the following places, which may be of interest for search:
Retargetable compilation | |
Retargetable program loading |
This place covers:
- Updating of existing software, i.e. modifying already installed software to a desired version.
- Being informed of new software that has become available in order to update including installation for the update.
- Synchronization of software of disconnectable devices after their reconnection to the network automatically upgrading software to the correct version.
- Transparent update (e.g. after boot, after update becomes available, regular check for updates,…)
- User-initiated update.
This place does not cover:
Security arrangements therefor |
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
Scheduling of updates for software modules stored at the client | |
For set top boxes |
Attention is drawn to the following places, which may be of interest for search:
Error handling during software upgrade | |
Synchronizing caches | |
Replication of documents/files | |
Software upgrading/downloading on mobile terminals |
This place covers:
- Updating software stored in non-volatile, alterable, solid-state storage, e.g. flash or EEPROM.
- In place updating
Attention is drawn to the following places, which may be of interest for search:
Update program code stored in non-alterable ROM | |
Changing the capability of a processor by loading new microcode, e.g. representing a different instruction set | |
Secure firmware programming | |
Low level details of writing to solid-state storage |
This place covers:
- Updating software while it is executing or running
Specific topics included:
- Hot-plugging of new software into a running system
- Run-time adaptation of the functionality of executable code by relinking to new code modules
Attention is drawn to the following places, which may be of interest for search:
Power plants, Industrial process controllers | |
Telecommunication systems |
This place covers:
Update methods explicitly demonstrating how a new version of software is created from an old version and update instructions and/or differential data. The simplest way to update a piece of software from a first version to a second version is to remove the first version in its entirety and replace it by the entire second version. This method, although conceptually simple, is highly inefficient, especially in the case where the second version differs only slightly from the first version:
- It is always necessary to provide the target with the entire second version; if a network is involved, this puts a high burden on the network
- It might take a long time to perform the update because the entire first version has to be deleted and the entire second version has to be written.
This group tackles this problem in that the update is performed by using the existing instance of the first version as a basis and to generate the instance of the second version therefrom. The scope of the group can thus be described as dealing with the details of how to modify an existing instance of the first version in order to arrive at the second version.
Typically, the second version is created by only changing those parts of the first version that actually change. This can be accomplished by creating a difference file (delta) that describes the differences of the second version with regards to the first version. The delta is provided to the target and applied to the first version thus yielding the second version. This delta can be passive - the delta is applied by an updater - or active -the delta contains instructions to actually perform the update.
Incremental update more generally refers to details of the steps involved to convert one piece of software into another. Differential update is more specific and explicitly uses differences between the two pieces of software.
Attention is drawn to the following places, which may be of interest for search:
Updating remote displays by only transmitting differences | |
Comparing a list of software actually installed on a device and a list of software that should be installed on a device; identify software not installed that should be installed on install this software on the device | |
Delta for version control systems | |
Delta in the context of file systems | |
Calculation of difference between files | |
Compression in general |
This place covers:
Updating software that is stored in non-alterable ROM.
This place covers:
- Adapting the code of a program in response to new requirements, changes to the environment, detection of bugs, etc.
- When new functionality is required, analysing the code in order to find the points to edit; generating new code, and incorporating it into the application
This place covers:
Version control, administering version numbers and releases. Deals with the problem of managing a modular software system: keeping track of the changes and the different version of the modules, the interrelation between the modules, the effects of the changes of one module on the other modules, the problem of multiple users editing different modules.
Includes in particular :
- Make, Build
- Analysing changes to/conflicts between sources
- SCCS-like tools
- Dependency analysis
- Comparing/obtaining dates of last changes of sources/intermediates/targets;
- CVS - Concurrent Version Control, SVN, GIT, ...
This place does not cover:
Security arrangements therefor |
Attention is drawn to the following places, which may be of interest for search:
Dependency analysis in compilers | |
Dealing with different versions of software in the context of software updating | |
Configuration of peripheral devices | |
Configuration in the sense of changing parameters | |
Version control for text documents |
This place covers:
Applying any change to a computer program's code which improves its readability or simplifies its structure without changing its results. In software engineering, "refactoring" a source code module often means modifying the module without changing its external behavior, and is sometimes informally referred to as "cleaning it up".
Code refactoring can be considered the design-time equivalent of code optimization (G06F 8/443). Code refactoring is concerned with improving the structure of the code in view of easier maintenance whereas code optimization is concerned to make the code better for a particular aspect (speed, size, energy).
In this place, the following terms or expressions are used with the meaning indicated:
Code Refactoring | the process of changing software such that the changes do not alter the external behavior of the code, yet improve the internal code structure |
Re-engineering | In contrast to reverse engineering |
This place covers:
Augmenting program code with additional information in order to increase its understandability in view of easier maintenance.
Documenting program code, inserting comments in source code.
This place covers:
Reverse engineering of HLL source code to its underlying design, model.
Attention is drawn to the following places, which may be of interest for search:
When the reverse engineering is performed in the context of binary to binary translation | |
Decompilation and dissassembly | |
Protecting software against software analysis or reverse engineering, e.g. by code obfuscation |
This place covers:
Static analysis of the structure of program code.
Attention is drawn to the following places, which may be of interest for search:
Analysing program code in order to identify reusable program parts | |
Monitoring program code execution |
This place covers:
Detecting code clones, e.g. introduced as a result of copy & paste by the programmer.
Attention is drawn to the following places, which may be of interest for search:
Reuse, i.e. identifying recurring pieces of code for purposes of reuse | |
Exlining, i.e. finding similar sequences of code to replace them with a procedure invocation | |
Plagiarism detection for source code |
This place covers:
Adapting program code to run in a different environment, i.e. a different architecture or operating system.
This place covers:
Measurement of software metrics related to a software development project, such as product metrics and process metrics.
Attention is drawn to the following places, which may be of interest for search:
Measuring certain characteristics of a program in view of debugging |
Not to be confused with G06F 11/362 , which deals with measuring certain characteristics of a program in view of debugging.
This place covers:
The Year 2000 problem, i.e. adapting software so as to comply with a not-foreseen date format.
In patent documents, the following abbreviations are often used:
Y2K | Year 2000 |
This place covers:
Program control for general purpose computers.
Runtime execution of programs.
This place does not cover:
Program control for peripheral devices |
Attention is drawn to the following places, which may be of interest for search:
Note for use of these definitions:
In the sub-groups of G06F 9/00 there are rules of classification which differ from the rules of the IPC, and are specified in this section.
The sub-groups mentioned under "Informative references"; "Limiting references" and "Relationship between large subject matter areas" are to be taken as indicators as to where the document to be classified may be forwarded or circulated for classifiying.
Specific combinations or conventions of classification are mentioned under "Special rules of classification".
Not currently used, as old technology.
This place does not cover:
Arrangements for program control using storeddevelopment of programs; Software engineering |
Not currently used, as old technology.
This place covers:
Programming arrangements for computers having a stored program. Covers execution of stored programs, and arrangements therefor.
Attention is drawn to the following places, which may be of interest for search:
Program control for machine tools using a digital processor |
This place covers:
Arrangements for executing microcode in general.
A next instruction of the program, when fetched from program store, is translated into lower level microinstructions, usually by using the instruction to index into a microprogram or control memory to fetch a series of microinstructions which are then decoded to obtain control signals to carry out the function of the machine instruction.
Attention is drawn to the following places, which may be of interest for search:
Execution of machine instructions |
Precedence and classification rules:
The classification rules for subgroups G06F 9/22 - G06F 9/28 is different from those used in G06F 9/30 and subgroups.
All aspects disclosed in a document which are deemed useful for search receive a class, not just the subject matter of the invention. Hence multiple subgroups are to be used.
There is no distinction made between invention and additional subject matter, and the classes for additional subject matter are not used.
A single lower level group is given if appropriate. A higher level group is given for documents having features belonging to multiple subgroups.
In this place, the following terms or expressions are used with the meaning indicated:
Microprogram | internal set of instructions used to translate a machine instruction of the stored program into a series of control signals. The microprogram is usually fixed at runtime, and defines the operations of the processor. Changing the microprogram changes the functionality of the processor, i.e. what type of operations it can carry out, and how these are carried out. |
Nanoinstructions | instructions of a level lower than microinstructions i.e. multiple nanoinstructions are used to execute a microinstruction. |
In patent documents, the following words/expressions are often used as synonyms:
- "microprogram", "microcode", "firmware" and "microinstructions"
This place covers:
Microinstruction execution aspects independent of the type of microinstruction, e.g. decoding of microinstructions; timing.
Includes PLAs used as sequencers for microcode.
In patent documents, the following words/expressions are often used as synonyms:
- "PLA" and "Programmable Logic Array"
This place covers:
Specific types of microinstruction operations.
Microinstruction set, microinstruction format.
This place covers:
- Loading of microcode implying altering the processor functionality;
- Changing the processor operations by loading or modifying microcode in the control store, thereby altering the way in which instructions are implemented in microcode;
- Fetching control microcode from ROM into RAM for execution;
- Patching by loading new microcode. Usually implemented by substituting the microcode at a particular instruction address in the microstore by a correct version during instruction fetching.
Loading of operating system or application programs; loading of new versions of software G06F 9/445.
This place covers:
- microinstruction addressing arrangements;
- sequencers for microcode;
- microinstruction storage, and microinstruction retrieval or fetching.
This place does not cover:
Enhancement of operational speed, e.g. by using several microcontrol devices operating in parallel |
In patent documents, the following words/expressions are often used as synonyms:
- "microinstruction" and "microinstruction" or "microprogram" and "microprogram"
This place covers:
Formation of the microinstruction address e.g. using lookup table.
This place covers:
Retrieval of the next microinstruction
This place covers:
Address formation of the next microinstruction by selection according to the results of processing.
Next microaddress or microinstruction derived directly from the program flow, e.g. program counter, branch.
This place covers:
Address formation of the next microinstruction by selection of address on input of storage.
Selecting at the input to the control store, which address to use, and therefore which microinstruction is retrieved.
This place covers:
Address formation of the next microinstruction by selection of microinstruction on output of storage.
Inputting several addresses into the control store, and selecting at the output of the control store which microinstruction to execute.
This place covers:
Address formation of the next microinstruction by selection not based on the results of processing.
Selecting next microaddress or microinstruction not derived directly from the program flow, e.g. interrupt, patching.
Attention is drawn to the following places, which may be of interest for search:
Patching by microcode loading | |
Address formation of the next machine instruction for runtime patching |
In this place, the following terms or expressions are used with the meaning indicated:
Patching | repairing errors of microcode in read-only storage. Usually implemented by substituting the microcode at a particular address in the microstore by a correct version during fetching. |
Interrupt | changing execution flow in response to an (external) event which must be handled with a higher priority. |
This place covers:
Means to improve speed of microcode execution e.g. dual control stores.
Parallel or concurrent execution of microinstructions.
Takes precedence over other sub-groups of G06F 9/22.
This place does not cover:
Arrangements for executing microinstructions |
These rules of classification apply to the group G06F 9/30 and subgroups:
All aspects disclosed in a document which are deemed useful for search are classified.
There is no distinction made between invention and additional subject matter.
Note that combinations of subgroups are possible from different hierarchy levels, or from the same level within the hierarchy.
The following IPC subclasses are not used in this classification scheme, but are covered by the subgroups listed here:
IPC group G06F9/302 covered by CPC group G06F 9/3001;
IPC group G06F9/305 covered by CPC group G06F 9/30029;
IPC group G06F9/308 covered by CPC group G06F 9/30018;
IPC group G06F9/312 covered by CPC group G06F 9/30043;
IPC group G06F9/315 covered by CPC group G06F 9/30032;
IPC group G06F9/318 covered by CPC group G06F 9/30181.
In this place, the following terms or expressions are used with the meaning indicated:
Machine instructions | Executable instructions of the processor, which can be decoded to obtain control signals |
This place covers:
Execution of specific individual machine instructions with a specific opcode and/or instruction format.
Adaptation of hardware, and hardware control, to carry out the execution of a specific machine instruction with a specific opcode and/or instruction format.
Attention is drawn to the following places, which may be of interest for search:
Multiple parallel functional units executing instructions |
In the subgroups of G06F 9/30003, if the execution of the machine instruction includes special arrangements for the setting of a condition code or flag, then also use G06F 9/30094.
In the case of a single machine instruction which carries out a combination of operations, use a subgroup for each operation.
In the subgroups hereof, the terms in capitals which are used as examples, refer to well-known types of instructions characteristic to that subgroup.
This place covers:
Specific instruction to perform operation between input data operands, usually returning an output data operand as the result.
Instructions for complex operations on data, e.g. checksum, hash, transforms, cryptography and random number generator instructions.
Attention is drawn to the following places, which may be of interest for search:
Specific instruction for operation on memory operands |
This place covers:
Specific arithmetic instruction, e.g. add, multiply and multiply accumulate.
Includes how to select the specific operation to execute in an ALU.
In patent documents, the following abbreviations are often used:
ALU | Arithmetic Logic Unit |
MAC | Multiply-Accumulate |
FMA | Fused Multiply Add/Accumulate |
This place covers:
Arithmetic operation where the bit width operated on may be variable precision; e.g. floating point with rounding to fit register; double precision arithmetic.
Bit-sliced arithmetic operation.
Attention is drawn to the following places, which may be of interest for search:
Multiple arithmetic units executing an instruction in tandem or cascaded |
This place covers:
Specific instruction for operation on a series of connected bits, bytes, or characters.
Examples include the EDIT instruction which alters a portion of a character string, or a Find-First-One instruction which detects the position of the first '1' in a string of bits.
Includes cyclic redundancy check instructions.
This place covers:
Specific instruction for comparison between two operands.
Includes matching, greater/less than, minmax instruction.
In patent documents, the following abbreviations are often used:
MINMAX | instruction to find the minimum of a series of input operands, alternatively to find the maximum of the same. |
This place covers:
Specific instruction for conversion from one data format to another.
Includes Endian conversion; Conversion between integer and floating-point; Decimal conversion instructions.
Attention is drawn to the following places, which may be of interest for search:
Data re-arranging instruction, e.g. Shuffle, Permute |
This place covers:
Specific instruction for logical operation or combination, e.g. XOR, NOT.
This place covers:
Specific instruction for moving, rearranging, or re-ordering data within a register.
Examples include: Move instruction which transfers data between registers; Permute/Shuffle instruction which changes the order of data in a register; Rotate or Shift instruction which moves bits or bytes within a register.
Attention is drawn to the following places, which may be of interest for search:
Instruction for operation on string operands | |
Instructions for format conversion operations | |
Instruction for operation on memory operands |
In this place, the following terms or expressions are used with the meaning indicated:
Move | instructions to pass data between memory locations, or between registers, without operating on the data. |
Shift | instructions to move data in a serial fashion from one location to another, where the distance moved is usually less than a word, e.g. shifting data within a register by a few bits. |
Rotate | instructions which are shift instructions where the bits shifted serially out are inserted into the location at the opposite end. |
Permute or Shuffle | instruction which intermingles parts of a datum to produce a new datum. |
This place covers:
Specific instruction operating on multiple data stored in a single register, thereby effecting a SIMD operation.
Instructions operating on packed arrays of elements, e.g. vector, tile or matrix operations.
Attention is drawn to the following places, which may be of interest for search:
Multiple functional units executing an instruction in parallel |
This subgroup may be used in combination with other subgroups of G06F 9/30007, according to the operation performed.
This place covers:
Using a mask while operating on and/or generating packed data. A mask may contain one or more bits for each element of packed data and may be located in a mask register.
Generating a mask used for operating on and/or generating packed data.
In patent documents, the following words/expressions are often used as synonyms:
- mask and predicate
This place covers:
Specific instruction for operation on memory operands in general.
Specific instruction for control operation on memory.
Memory to memory Move instruction.
Stack instructions POP, PUSH
Table lookup instructions.
A combination of a memory operation and further operation e.g. atomic memory operations such as read-modify-write, test-and-set.
Register allocation instructions.
Attention is drawn to the following places, which may be of interest for search:
Specific instruction for data operation |
For atomic memory operations use in combination with serialisation control instructions G06F 9/30087, and possibly G06F 9/3834 for memory consistency.
This place covers:
Specific instruction to read or write data from a memory location, e.g. LOAD, STORE, Load Multiple.
Specific instruction to clear or reset a memory location, e.g. CLEAR.
Register reset or clear instructions.
Context saving or restoring instructions.
For Load Multiple when executed as an iterative instruction use also G06F 9/30065.
This place covers:
Specific instructions for control data or instruction prefetching from memory, e.g. Hint instruction.
Specific instructions to control cache operation, e.g. Cache Flush.
Specific instructions to control a TLB or a page table, e.g. page table entry clearing instruction.
This place covers:
- Specific instruction to control program flow in general.
- Execution of an instruction to select a next instruction other than the next sequential instruction, e.g. for branching.
- Execution of an instruction for facilitating branching, e.g. Prepare-To-Branch instruction.
Specific instruction for monitoring or tracing program flow e.g. breakpoint instruction; flow signature instruction.
Only to be used when there is subject matter relating to special adaptations or details of handling of an unconditional branch instruction.
This place covers:
Special adaptations to execute a specific instruction which unconditionally branches to a target address independent of any condition.
Examples of unconditional branch instructions are CALL, GOTO and RETURN insofar as these are unconditional.
Only to be used when there is subject matter relating to special adaptations or details of handling of an unconditional branch instruction.
This place covers:
Specific instruction which causes conditional branching to a target address dependent on a runtime condition, else continues execution with the next sequential instruction.
Includes IF-THEN-ELSE constructions.
Only to be used when there is subject matter relating to special adaptations or details of handling of a specific conditional branch instruction.
This place covers:
Specific instruction which causes a branching to one of several alternative target addresses depending on a runtime condition.
This place covers:
Specific instruction used for loop control, e.g. specific loop start or end instructions.
Specific instruction which is repeatedly executed, thereby forming a (short) loop, e.g. REPEAT.
Attention is drawn to the following places, which may be of interest for search:
Address formation for loops, loop detection | |
Loop buffering |
This place covers:
Specific instruction which causes a number of instructions to be skipped i.e. not executed, thus effecting a (short) forward branch, e.g. SKIP.
A skip of a single instruction is regarded as conditional instruction execution, not skipping.
Attention is drawn to the following places, which may be of interest for search:
Conditional branch instruction | |
Single instruction skip as conditional execution. |
This place covers:
Specific instruction for conditional operation depending on a runtime condition, which is not for control of program flow, i.e. instruction that is not a branch.
The operation carried out depends on a runtime condition, for example ADD or SUBTRACT depending on the value of the sign bit. Another example is a MOVE which is executed or not depending on a runtime condition.
Includes instructions which are executed conditional on a predicate or guard.
Includes conditional instructions in a branch shadow.
Attention is drawn to the following places, which may be of interest for search:
Conditional branch instruction | |
Multiple instruction skipping for forward branch. | |
Instruction which executes differently according to a mode |
G06F 9/30058 has precedence.
May be used in combination with other sub-groups of the G06F 9/30003 according to the operation performed by the conditional instruction, e.g. conditional MOVE in combination with G06F 9/30032.
In this place, the following terms or expressions are used with the meaning indicated:
Conditional | dependent on a runtime condition or operational status. |
Guard | a tag indicating a condition which is assigned to an instruction. According to the outcome of the condition evaluation, the instruction is executed or skipped. Often assigned by the compiler to avoid branches |
Predicate | same meaning as 'guard' |
This place covers:
Specific instructions for operation control in general.
Includes mode switching instructions.
Includes no-operation instructions [NOP].
Attention is drawn to the following places, which may be of interest for search:
Specific instructions for program flow control | |
Multi-cycle NOP used as a pipeline delay instruction |
This place covers:
Specific instruction to control an instruction pipeline, e.g. HALT, FLUSH
Instructions for variable delay of pipeline or execution, e.g. multicycle NOP.
This place covers:
Specific instruction to control power consumption or thermal aspects of the processor, e.g. SLEEP.
This place covers:
Specific instruction to control serialisation of instruction execution; to control synchronisation of instruction execution.
Includes specific instructions used to implement memory locks; barriers. Includes instructions to facilitate atomic execution.
Attention is drawn to the following places, which may be of interest for search:
Program synchronisation ; Mutual exclusion |
For atomic memory operations use also G06F 9/3004.
For barrier or fence instructions use also G06F 9/3834.
For synchronisation instruction which affects the execution of a thread use also G06F 9/3009.
This place covers:
Specific instruction to control multi-threading; starting and stopping threads, e.g. FORK; JOIN.
This place covers:
Special arrangements for the generation or storage of runtime conditions, e.g. flags (Carry, Zero flag, etc.); writing to status register.
Attention is drawn to the following places, which may be of interest for search:
Execution of instructions according to a runtime mode |
This place covers:
Groups of registers; register files.
Register file addressing; addressing partial registers.
Accessing register file e.g. contention.
Attention is drawn to the following places, which may be of interest for search:
Register address space extension | |
Register renaming |
In this place, the following terms or expressions are used with the meaning indicated:
Register | set of one-bit storages, e.g. latches, accessed in parallel |
Register file | set of registers. May be implemented in a single or in multiple memories |
In patent documents, the following abbreviations are often used:
GPR | general purpose register |
This place covers:
Special adaptation of the use of single or multiple registers for a dedicated purpose, not being general purpose registers. May not be part of the register file.
Examples include particular use of dedicated address register, control register, status register, condition code register, Top Of Stack register.
Attention is drawn to the following places, which may be of interest for search:
Program counter registers |
Only to be used when there is subject matter relating to special adaptations or details of use of a special purpose register.
This place covers:
Details of the structure of an individual register.
Registers having associated bits e.g. valid bits, tags, flags.
This place covers:
Registers which are logically partitioned into multiple operands, e.g. for packed data or parallel operations.
Attention is drawn to the following places, which may be of interest for search:
Multiple registers used for variable length operands |
This place covers:
Register structure for variable length operands, i.e. variable length data can be stored, e.g. single register for storing an M-bit integer or an N-bit integer, or a single register for storing an X-bit integer or a Y-bit floating point value.
Use of partial registers for short data.
Combinations of registers for longer or higher-precision data, e.g. by concatenation.
Accessing of variable length registers.
Attention is drawn to the following places, which may be of interest for search:
A single register for multiple operands |
This place covers:
Registers which cannot be addressed by an instruction, and hence are invisible to the architecture, e.g. coupled registers, not forming part of the register space.
Register with an associated copy, e.g. for saving of architectural state.
Use in combination with G06F 9/30123 for shadow register set used for another context.
In this place, the following terms or expressions are used with the meaning indicated:
Register space | the address space used by registers i.e. the range of program addressable register locations. |
This place covers:
The physical or logical organisation of the register space in general.
Includes partitioned, distributed or banked register files, e.g. per execution unit.
Local and global register files.
Register banks for register space extension use G06F 9/30138.
Register banks for context data use G06F 9/30123.
In this place, the following terms or expressions are used with the meaning indicated:
Register space | logical address space for registers, i.e. the range of addresses defined by a register specifier |
This place covers:
Organisation of sets of registers used for storing the data of a particular context, e.g. local variables.
Includes thread buffers used to hold the context of a thread, and forming part of an instruction stream.
Use in combination with G06F 9/30116 for shadow register set used for another context.
In this place, the following terms or expressions are used with the meaning indicated:
Context data | operands and data representing the architectural state of a context, and which needs to be saved on a context switch |
This place covers:
Organisation of sets of registers used to implement register windows.
May have a pointer to the first window location, which may be used as a base address. Used for example for fast context switching, by moving from a current window to a next window.
In this place, the following terms or expressions are used with the meaning indicated:
Register window | set of contiguous registers used to implement a window to hold context data |
This place covers:
Organisation of sets of registers used to store different types of data.
Includes address registers, Boolean registers, floating point registers, parameter registers.
This place covers:
Register stacks are a series of register locations implementing a stack. The register stack is addressable generally using a register containing the Top-of Stack pointer. Writing to the TOS location implies adding an entry to the top of the stack, reading implies removing an entry from the top of the stack.
The implementation of stack read/write operation in a register stack may involve physically shifting the entries in the queue up or down using shift registers; or alternatively may involve incrementing or decrementing the TOS pointer to access the next or previous register.
Details of shift registers implementing a FIFO buffer are also found here.
Attention is drawn to the following places, which may be of interest for search:
Special purpose register for TOS pointer |
In this place, the following terms or expressions are used with the meaning indicated:
Register stack | contiguous set of register locations used to implement a stack. May be implemented as a shift register |
Shift register | register which shifts its contents in a bit-parallel fashion into an adjacent register. |
In patent documents, the following abbreviations are often used:
TOS | Top of Stack |
This place covers:
Increasing or decreasing the number of available addressable locations in register address space, e.g. more or less physical registers than logical registers, register cache.
Extension of register address length e.g. using indexing.
This place covers:
Hardware implementation of register files.
Register file port architecture; address or data ports.
Internal bypass path of register files.
Adaptations of register file hardware for particular problems, e.g. for power saving; for fault tolerance.
Includes transposing register file being accessible vertically or horizontally.
In this place, the following terms or expressions are used with the meaning indicated:
Bypass path | direct connection between a register file input and output. |
This place covers:
Decoding of instructions in general, of opcode in particular.
Instruction format, instruction encoding, instruction word fields.
Instruction set as a whole.
Decoding of microinstructions G06F 9/223.
Attention is drawn to the following places, which may be of interest for search:
Decoding of microinstructions | |
Runtime instruction translation |
Runtime instruction translation using a decoder is classified under G06F 9/3017 and sub-groups, even if this involves decoding, since the purpose is translation.
In this place, the following terms or expressions are used with the meaning indicated:
RISC | Reduced Instruction Set Computer. Architecture having set of simple instructions which are decoded into direct control signals, and which take a single cycle to execute. |
CISC | Complex Instruction Set Computer. Architecture having set of complex instructions which are decoded into internal (native; microcode) instructions, and which may take multiple cycles to execute. |
This place covers:
Decoding of variable length instructions.
Includes instruction where the relative length of operation and operand part is variable.
Ensuring a whole instruction is decoded. Parsing variable length instructions (VLI).
Attention is drawn to the following places, which may be of interest for search:
Instruction pre-fetching when instruction length is variable, e.g. line-crossing fetch; alignment in instruction buffer |
This place covers:
Arrangements for determining and/or marking the boundaries of a variable length instruction (VLI); Special arrangements for determining the length of a variable length instruction other than by decoding the length.
Attention is drawn to the following places, which may be of interest for search:
Pre-decoding of instructions |
This place covers:
Instruction encodings (e.g. Gray coding) to achieve a secondary effect, e.g. power saving, saving memory space, security, fault tolerance.
Computer-aided instruction set design G06F 30/00.
Attention is drawn to the following places, which may be of interest for search:
Runtime instruction translation for compressed or encrypted instructions |
Use in combination with G06F 9/30178 for decompression by translation, or with G06F 9/3822 for format field decoding for VLIW.
This place covers:
Decoding operand fields of instructions; Format of operand fields of instructions, e.g. specifier format.
Attention is drawn to the following places, which may be of interest for search:
Decoding the opcode of instructions |
This place covers:
Instruction format which is shorter by having operand specifier field(s) missing but implied, e.g. Top of Stack, accumulator, dedicated register.
This place covers:
Decoding of immediate operand specifiers or constants; Concatenation of immediates; Buffering of immediates.
In this place, the following terms or expressions are used with the meaning indicated:
Immediate | data in an instruction to be used directly as an operand, e.g. without storing in a register |
Constant | same meaning as 'immediate' |
This place covers:
Runtime translation of an instruction by decoding an instruction which is non-native to produce an instruction or set of instructions that can be decoded by the processor. The decoding of machine instructions of the executing processor's instruction set, or decoding of lower level microcode is not meant to be included here.
Altering the format or encoding of the input instruction, e.g. length of fields.
Translating a single instruction, e.g. macro, into multiple executable instructions, or the reverse (macro formation).
Attention is drawn to the following places, which may be of interest for search:
Decoding of microinstructions | |
Decoding of instructions | |
Instruction emulation or interpretation |
In this place, the following terms or expressions are used with the meaning indicated:
Macro | An opcode which is an alias for a series of instructions, i.e. a function. |
Non-native instruction | An instruction which is not executable in the architecture of the processor. |
This place covers:
Runtime translation of a non-native instruction (e.g. Javabyte, legacy code) into an executable native instruction using hardware means, e.g. decoder, look-up table.
Runtime translation for the purpose of ISA emulation in hardware.
Instruction emulation or interpretation G06F 9/455.
In this place, the following terms or expressions are used with the meaning indicated:
Non-native instruction set | set of instructions intended to execute on a different architecture, which cannot run without translation or reformatting. Legacy code may be considered non-native. |
Non-native instruction | an instruction which is not executable in the architecture of the processor. |
This place covers:
Runtime translation of an encrypted or compressed instruction into an instruction which can be executed.
Attention is drawn to the following places, which may be of interest for search:
Special encoding of instructions for saving memory or power. |
This place covers:
Modification or extension of the execution of an instruction in general.
Modifications to the instruction itself, or to the architecture, which increase the number of operations available to the architecture.
Attention is drawn to the following places, which may be of interest for search:
Execution unit with adaptable datapath for complex operation |
This place covers:
Modification of the operation of an instruction according to one or more bits encoded within, or appended to, the instruction, e.g. prefix, sub-opcode.
Attention is drawn to the following places, which may be of interest for search:
Modification of the operation of an instruction according to an execution mode |
This place covers:
Modification of the operation of one or more instructions according to a mode of operation, e.g. mode flag in a mode register.
Attention is drawn to the following places, which may be of interest for search:
Mode switching instruction | |
Instruction operation extension or modification according to one or more bits in the instruction, e.g. prefix, sub-opcode |
This place covers:
Modification of the operation of an instruction according to a data type descriptor, e.g. dynamic data typing.
This place covers:
Modification of the operation of an instruction by modifying the decoding of the instruction using more than one decoder, or a decoder which is adaptable or programmable.
Extension of the instruction set using multiple decoders for multiple instruction sets.
This place covers:
Selecting or calculating the next instruction address.
Sequencers for machine instructions.
This place does not cover:
Concurrent instruction execution, e.g. pipeline, look ahead |
Attention is drawn to the following places, which may be of interest for search:
Subprogram jump |
This place covers:
Incrementing/decrementing means for the program counter.
Selection of next PC from pre-calculated constant values, e.g. +1, +2, 0, -1.
PC arrangements, e.g. multiple PCs.
In this place, the following terms or expressions are used with the meaning indicated:
Program counter | a dedicated register which holds the address of the current instruction in the program sequence |
In patent documents, the following abbreviations are often used:
PC | Program counter |
This place covers:
Address formation, or selection, for the next instruction, being a non-sequential address.
Address calculation or selection, for the execution of branch instructions in general, e.g. for multiple types of branch.
Selection of next instruction address from various alternatives, e.g. PC, a constant, branch target, branch fall-through.
In this place, the following terms or expressions are used with the meaning indicated:
PC address formation | address calculation, i.e. address selection |
This place covers:
Determination of program counter for an instruction that specifies where an address is located (rather than specifying the address itself) and branches using the address. The specification of the address location can be explicit (e.g. Branch R1) or implicit (e.g. RETURN). The address can be the target address or a base address used to calculate the target address.
Attention is drawn to the following places, which may be of interest for search:
Special adaptations or details of handling of a specific unconditional indirect branch instruction that are distinct from program counter determination | |
Special adaptations or details of handling of a specific conditional indirect branch instruction that are distinct from program counter determination |
In patent documents, the following words/expressions are often used as synonyms:
- Indirect branch, computed branch, register-indirect branch and indirect jump.
This place covers:
Formation of the next instruction address using an offset from the program counter.
Attention is drawn to the following places, which may be of interest for search:
Address formation of the instruction operand or result using PC-relative addressing |
This place covers:
Formation of the next instruction address for a loop.
Loop formation; loop detection.
Loop counters.
Attention is drawn to the following places, which may be of interest for search:
Specific loop control instructions or iterative instructions | |
Buffering of loop instructions |
This place covers:
Formation of the next instruction address for an interrupt, using hardware means e.g. look-up table.
This place covers:
Formation of the address of a next instruction for the purpose of patching an instruction.
Includes detection of program addresses or instructions to be patched.
Patching of software or loading of new version of software G06F 9/445.
Instruction emulation G06F 9/455.
Runtime patching of microcode in ROM G06F 9/268.
In this place, the following terms or expressions are used with the meaning indicated:
Patching | repairing errors in machine instructions in read-only storage at runtime. Usually implemented by substituting the instruction at a particular address in the memory by a correct version. |
This place covers:
- Addressing the instruction operand or the result.
- Operand addressing modes in general.
- Endian conversion.
Addressing of memories in general, address translation G06F 12/00.
Attention is drawn to the following places, which may be of interest for search:
Accessing an operand in a pipeline | |
Address translation |
In this place, the following terms or expressions are used with the meaning indicated:
Addressing mode | type of operand addressing e.g. indirect, indexed |
This place covers:
Increasing the size of the addressable operand memory space i.e. increasing the number of available addressable locations.
Extending the operand address space by increasing the bit length of addresses.
Extending the operand address space by use of multiple address spaces; bank pointer.
Address space extension in memory systems G06F 12/0615
Attention is drawn to the following places, which may be of interest for search:
Organisation of register space |
This place covers:
Address formation for a series or group of operands, e.g. for an array.
Address formation for pairs of operands at adjacent addresses i.e. addr;addr+1.
Attention is drawn to the following places, which may be of interest for search:
Prediction of operand addresses for operand prefetching | |
Addressing multiple banks |
May also be classified according to the addressing mode.
This place covers:
Address formation for a series of operands by adding a stride value to the previous address to form the next address.
May be used to predict the next operand address.
In this place, the following terms or expressions are used with the meaning indicated:
Stride | offset or displacement which may be a constant. |
This place covers:
Address formation using a single address operand, e.g. using the contents of an address register or GPR.
In this place, the following terms or expressions are used with the meaning indicated:
Indirect addressing | the address is the value contained in the register specified in the instruction. |
Direct addressing | the address is the value specified in the instruction. |
GPR | general purpose register |
This place covers:
Operand address formation using more than one address operand, e.g. using base + index/offset registers.
Indexed address formation or calculation details.
Uses at least two address operands which are added or concatenated. The resulting address may be longer than the base address, hence indexed addressing may be also used for address space extension.
Attention is drawn to the following places, which may be of interest for search:
Address space extension |
In this place, the following terms or expressions are used with the meaning indicated:
Indexed addressing | the address is the value contained in the base register specified in the instruction summed with the value contained in the index register specified in the instruction. The index part of the address usually consists of less bits than the base part of the address, and is therefore an offset from the base address |
In patent documents, the following words/expressions are often used as synonyms:
- " index"," offset", "displacement" and "delta"
In this place, the following terms or expressions are used with the meaning indicated:
Wraparound | incrementing the maximum address value, e.g. 11111111 leads to wraparound to the lowest address value, e.g. 00000000, so that addressing is continuous, avoiding an overflow error |
Modulo or circular addressing | same meaning than Wraparound |
In this place, the following terms or expressions are used with the meaning indicated:
Scaling | indexed addressing where the index address is multiplied by a factor before adding to the base address |
This place covers:
- Address formation using the program counter as a base for indexed addressing;
- PC-relative addressing.
Attention is drawn to the following places, which may be of interest for search:
Next instruction addressing using an offset from the program counter. |
This place covers:
Simultaneous execution of instructions in general, in parallel or pipelined.
Special architectures where instruction execution is concurrent.
Includes stack machines.
Concurrent program execution: G06F 9/46.
This place covers:
Prefetching and fetching of instructions for execution, in general.
Instruction buffering; instruction caches
This place covers:
Prefetching of instructions for branch paths.
In this place, the following terms or expressions are used with the meaning indicated:
Hedging | Fetching both paths of an unresolved conditional branch |
Branch folding | Removal of a branch instruction from the instruction stream, e.g. by including the branch condition in an instruction as a predicate |
This place covers:
Using a history of previous branch target addresses to predict the address to fetch from, e.g. branch target buffer, branch history buffer;
Address buffers for predicting next fetch address for a branch, e.g. return address stack.
Attention is drawn to the following places, which may be of interest for search:
Dynamic prediction of branch direction | |
Static prediction of branch direction | |
Hybrid prediction of branch direction |
In this place, the following terms or expressions are used with the meaning indicated:
BTB | buffer indexed by an instruction fetch address or PC, which returns the predicted target address if the instruction is a taken branch. |
BHT | buffer indexed by a branch instruction address, which returns a prediction of whether the branch is taken or not. |
Return address stack | Stack to hold the program address to return to after a Call-type branch. The stack structure allows nesting of Calls. |
In patent documents, the following abbreviations are often used:
BTB | Branch Target Buffer |
BHT | Branch History Table |
BTAC | Branch Target Address Cache |
This place covers:
Prefetching of instructions intended to be used more than once, thereby saving fetch time.
Buffering of instructions for reuse, e.g. trace cache.
Branch target caches for caching a branch target instruction.
The storing of addresses, e.g. branch target address caches (BTAC), is not meant to be stored here.
Program tracing for monitoring G06F 11/3466.
In this place, the following terms or expressions are used with the meaning indicated:
Branch target cache | History buffer of first instruction at a branch target, which returns an instruction rather than an address, thus saving fetch time. |
Trace cache | Cache storing a history of previously executed paths through the program, as sequences of instructions. Accessing the trace cache returns the next predicted instructions in the sequence. |
This place covers:
Prefetching of instructions intended to be used in a loop, thereby saving fetch time;
Buffering of instructions for loops.
Attention is drawn to the following places, which may be of interest for search:
Specific loop control instructions | |
Formation of the next instruction address for a loop; detection of loops |
This place covers:
Instruction prefetching in an architecture allowing instruction modification.
How to handle store-into-instruction-stream, wherein an instruction in memory is modified, e.g. by writing back a new operand value, hence the prefetched copy of the instruction is stale.
This place covers:
- Special arrangements for buffering of prefetched instructions;
- Prefetch buffers;
- Banked or partitioned instruction buffers.
In this place, the following terms or expressions are used with the meaning indicated:
Prefetch buffer | in this subclass, a buffer to hold a recently fetched set of instructions, usually between the instruction memory and the instruction decoder, e.g. cache line buffer. |
In patent documents, the following words/expressions are often used with the meaning indicated:
"cross-modifying code" | "instructions which can modify other instructions". |
"self-modifying code" | "instructions which can modify themselves". |
This place covers:
Arrangements for (correct) alignment of instructions in prefetch buffers.
Instruction prefetching which crosses a line in memory or cache, for example for variable length instructions.
Attention is drawn to the following places, which may be of interest for search:
Variable length instructions | |
Predecoding instructions for alignment information |
This place covers:
Decoding for enabling the concurrent execution of instructions.
Attention is drawn to the following places, which may be of interest for search:
Decoding of a single instruction |
This place covers:
Decoding for enabling the pipelined execution of instructions.
Predecoding stage in a pipeline.
Partitioned decoding stage.
Attention is drawn to the following places, which may be of interest for search:
Instruction alignment using predecode information |
This place covers:
Decoding for enabling the parallel execution of instructions, e.g. parallel decode units.
Special details of decoding multiple instructions in parallel, e.g. decoding of Very Long Instruction Word format field.
Attention is drawn to the following places, which may be of interest for search:
Compressed VLIW instructions |
This place covers:
Retrieving operands for instructions, from memory, registers, other pipeline stages or execution units.
Attention is drawn to the following places, which may be of interest for search:
Load, Store instructions | |
Register file accessing in general |
In patent documents, the following words/expressions are often used as synonyms:
- "input operand" and "source"
- "output operand", "result" and "destination"
This place covers:
Arrangements for the transfer of an instruction result to a dependent instruction, without first storing in the architected state, e.g. bypassing the register file;
Transfer of operand data from the output of a functional unit to the input of another functional unit, without waiting for the completion of the data producing instruction, or without waiting for the data to be stored in the register file, e.g. locally between pipeline stages, within a pipeline stage.
Attention is drawn to the following places, which may be of interest for search:
Transfer of data between Store and Load instructions for memory consistency |
In patent documents, the following words/expressions are often used as synonyms:
- "bypassing" and "forwarding"
This place covers:
Bypass of an instruction result to a dependent instruction in another pipeline, or group of execution units, e.g. between pipelines, between clusters;
Bypass arrangements for global data.
Attention is drawn to the following places, which may be of interest for search:
Parallel execution units organised in clusters |
In this place, the following terms or expressions are used with the meaning indicated:
Cluster | Group of execution units and register resources |
This place covers:
Prefetching of data operands;
Software data prefetching;
Prefetching from a data cache reduces cache misses during execution of the instruction using the data.
Prefetching between higher level memories: G06F 12/0862.
Attention is drawn to the following places, which may be of interest for search:
Specific instruction to prefetch data from memory | |
Instruction prefetching | |
Speculative load instructions | |
Prefetching between higher level memories |
In this place, the following terms or expressions are used with the meaning indicated:
Operand prefetching | Look-ahead fetching of an operand before the execution of the instruction which will use the operand |
This place covers:
Reuse or prediction of the value of an operand;
Operand value prediction using a history of the value of an operand;
Operand value buffering for reuse;
Prediction of the address of an operand.
Data caches in general:G06F 12/08.
This place covers:
How to maintain memory consistency during operand accessing for instruction execution.
Avoiding errors caused by loads and/or stores to the same memory address being executed out of order or concurrently.
Ensuring stored operands and fetched operands are consistent, e.g. memory disambiguation.
Ensuring out-of-order loads receive the latest store information by forwarding.
Cache consistency protocols: G06F 12/0815.
Multiprogramming arrangements for transaction processing: G06F 9/466.
Multiprogramming arrangements for program synchronisation: G06F 9/52.
Attention is drawn to the following places, which may be of interest for search:
Specific atomic or synchronisation instructions, e.g. Read-Modify-Write | |
Operand bypassing between Load and Store instructions | |
Consistency of architectural state | |
Cache consistency protocols |
In this place, the following terms or expressions are used with the meaning indicated:
Memory consistency | Keeping data in the memory up-to-date. Read data should not be stale; written data should not be overwritten by older data, which may occur in out-of-order execution. |
Memory disambiguation | Checking stores against earlier executed out-of-order loads, and re-issuing the loads if their data is stale. |
This place covers:
Runtime scheduling or issuing of instructions, e.g. dynamic instruction scheduling, out of order instruction execution.
Issuing policies or mechanisms for instructions. Instruction dispatching to execution units or execution buffers.
Concurrent execution of instructions.
Synchronisation of instruction execution.
Runtime scheduling of tasks: G06F 9/4806
Attention is drawn to the following places, which may be of interest for search:
Accessing of operands for issue | |
Re-issuing of faulting instructions |
In this place, the following terms or expressions are used with the meaning indicated:
Issuing | Runtime selection or scheduling of the instructions to execute. |
Superscalar | Architecture where more than one instruction is selected to be executed in parallel in one cycle. |
VLIW | Very Long Instruction Word being a compound instruction word formed by the compiler, containing multiple sub-instructions to be issued and completed together in one cycle |
This place covers:
Special arrangements to detect or record data dependencies between instruction operands at issue time, e.g. register scoreboarding.
In this place, the following terms or expressions are used with the meaning indicated:
Data dependency | When a first instruction specifies an operand which is also specified in a following second instruction, the second instruction is dependent on the first, and cannot be executed until the dependency is resolved, or the operand is available. |
Register scoreboard | Table of indicators of which instructions use which registers. May be used for dependency checking by detecting two instructions having a matching indicator. |
In patent documents, the following words/expressions are often used as synonyms:
- "Pseudo data dependency" , "false data dependency" , "anti-dependency" , "write-after-write dependency" and "output dependency"
This place covers:
Special arrangements to carry out register renaming, e.g. as a means of avoiding pseudo dependencies;
Rename tables and buffer, which may form part of a reorder buffer.
Attention is drawn to the following places, which may be of interest for search:
Reorder buffers |
In this place, the following terms or expressions are used with the meaning indicated:
Register renaming | Associating a logical register specified in an instruction to a unique physical register. Allows multiple physical registers to be assigned to hold data for multiple instances of a logical register, thus avoiding false dependencies.Relies on the set of physical registers being larger than the set of logical registers. |
RAW, read-after-write dependency | Occurs when a read to the same location occurs after a write to the same location. If the instructions are not in program order, this may lead to wrong execution. |
WAW, write-after-write dependency | It occurs when a write to the same location occurs after another write to the same location. If the instructions are not in program order, this may lead to wrong execution. |
Pseudo data dependency, false dependency, anti-dependency, output dependency | Dependency which may be resolved without wrong execution, e.g. a write followed in program order by another write; a read followed in program order by a write. |
In patent documents, the following words/expressions are often used as synonyms:
- "RAW" and "read-after-write dependency"
- "WAW" and "write-after-write dependency"
- "pseudo data dependency", "false dependency", "anti-dependency", "output dependency"
This place covers:
Execution of instructions ahead of program order, with the presumption that execution will prove to be correct, e.g. speculative loads, boosting.
Speculative instructions which are executed, e.g. alternative paths of a branch.
Execution of instructions dependent on a branch before its outcome is known.
Execution of instructions in a low-level transaction, e.g. machine instructions between a start transactional execution machine instruction and an end transactional execution machine instruction.
Attention is drawn to the following places, which may be of interest for search:
Conditional instruction execution, e.g. predication | |
Result nullification for executed instructions | |
Recovery after mis-speculation |
In this place, the following terms or expressions are used with the meaning indicated:
Speculative instructions | Executed instructions which may not be on the actual path taken through the program, and therefore may require recovery after execution if mis-speculation occurs. |
Speculative loads | Look-ahead or early execution of load instructions, where recovery would be needed in the case of mis-speculation. |
Transaction | A sequence of instructions executed as an atomic group. A transaction either commits (its updates take effect), or aborts and is rolled back (its updates are discarded). |
This place covers:
Speculative execution of instructions using dynamic branch prediction;
Using runtime conditions, and the previous behaviour of branches, to predict the outcome of a branch, without having to wait for its execution, e.g. branch history table;
Early generation of branch results.
Attention is drawn to the following places, which may be of interest for search:
Prediction of a branch address/target | |
Using hybrid branch prediction |
In this place, the following terms or expressions are used with the meaning indicated:
Dynamic prediction | Branch prediction based on runtime conditions, as opposed to compile-time branch prediction. |
Branch history table | Branch prediction based on runtime conditions, as opposed to compile-time branch prediction. |
Branch Target Buffer | Buffer indexed by an instruction fetch address or PC, which returns the predicted target address if the instruction is a taken branch. |
Branch History Table | Buffer indexed by a branch instruction address, which returns a prediction of whether the branch is taken or not. |
Branch Prediction Counter | saturating counter used to obtain a weighting for a branch prediction based on several branch executions. |
In patent documents, the following abbreviations are often used:
BTB | Branch Target Buffer |
BHT | Branch History Table |
BTAC | Branch Target Address Cache |
This place covers:
Speculative execution of instructions using static branch prediction, e.g. branch taken strategy;
Branch prediction performed by compiler, and not dependent on runtime conditions, e.g. hint bits.
Attention is drawn to the following places, which may be of interest for search:
Prediction of a branch address/target | |
Using hybrid branch prediction |
In this place, the following terms or expressions are used with the meaning indicated:
Static prediction | Branch direction is predicted based on compile-time branch prediction. |
Hint bit | Bit in branch instruction inserted by compiler to give an indication whether branch predicted taken or not. |
In patent documents, the following words/expressions are often used as synonyms:
- "hint bit" and "static bit"
This place covers:
Prediction schemes involving more than one type of predictor, e.g. selection between prediction techniques;
Static and dynamic prediction used alternately;
Local and global prediction mechanisms;
Two-level branch prediction.
Attention is drawn to the following places, which may be of interest for search:
Prediction of a branch address/target | |
Using dynamic prediction, e.g. branch history table | |
Using static prediction, e.g. branch taken strategy |
In this place, the following terms or expressions are used with the meaning indicated:
Two-level branch prediction | Two-dimensional prediction where the output of one method is used as an index into another method to provide a prediction (e.g. branch history's output as an index into a pattern history table). |
This place covers:
- Issuing instructions from multiple threads each having a context, including at least a program counter, and possibly registers and execution resources;
- Includes multiple streams for different threads, or from both directions of a branch;
- Interleaved execution of threads in a single or in multiple streams;
- Stream selection.
Thread scheduling or multithreading at OS or application level G06F 9/46.
This place does not cover:
Dispatching of multiple tasks or threads |
Attention is drawn to the following places, which may be of interest for search:
Context registers for multiple streams | |
Execution units or pipeline architectures for executing multiple streams |
In this place, the following terms or expressions are used with the meaning indicated:
Instruction stream | Architectural aspects, e.g. resources and context, used to execute a thread or series of instructions. Includes at least a program counter, and possibly including dedicated instruction buffers, registers, status register, execution units. |
This place covers:
Issuing of compound instructions;
Compounding single instructions into a group;
Issuing a group of instructions, that must complete in the same cycle;
Dispatching aspects of compound instructions, e.g. variable format VLIW instructions.
Attention is drawn to the following places, which may be of interest for search:
Decoding of VLIW format field |
In this place, the following terms or expressions are used with the meaning indicated:
Compound instruction | Consisting of sub-instructions, i.e. contains multiple opcodes, e.g. VLIW instructions. |
This place covers:
Post-execution stages
This place covers:
Special arrangements for reordering of instructions issued out-of-order;
Queue arrangements include reorder buffers;
Age tags include marking the instructions with the original program order.
In this place, the following terms or expressions are used with the meaning indicated:
Reordering | Restoring the program order after instruction execution, ensuring that the instructions complete in the correct order. |
Age tag | An indicator associated with an instruction to indicate its original program order, e.g. in the case of instructions executed out-of-order. |
This place covers:
Special arrangements to write back results to the architectural state or memory, which may be for ensuring correctness of the architectural state;
Special arrangements to write back multiple results from a low-level atomic or transactional block, e.g. machine instructions between a start transactional execution machine instruction and an end transactional execution machine instruction.
Attention is drawn to the following places, which may be of interest for search:
Specific machine instruction to store data to memory | |
Maintaining memory consistency | |
Recovery of architectural state after an exception |
In this place, the following terms or expressions are used with the meaning indicated:
Architectural state | Runtime data in the pipeline resources, including program counter, instruction queue, status register, condition codes, general purpose and special purpose registers, rename data, pipeline registers, etc. The state is updated when one of these resources is written to. |
This place covers:
Ensuring correctness of the architectural state by nullifying the results of wrongly executed instructions.
Nullifying may use, for example, preventing writeback; tagging the result as invalid; clearing of result.
Arrangements for nullifying the result of a predicted instruction where the predicate resolves to false.
Nullifying multiple results from a low-level atomic or transactional block, e.g. machine instructions between a start transactional execution machine instruction and an end transactional execution machine instruction.
Attention is drawn to the following places, which may be of interest for search:
Instructions which execute conditionally | |
Recovery from exceptions |
In this place, the following terms or expressions are used with the meaning indicated:
Nullification | Invalidation of an instruction result. The instruction has already executed, but the results are invalid, and must not update the architectural state. |
This place covers:
Recovery of correct instruction execution after an exception or fault;
Restoring the correct architectural state after an exception, e.g. after branch mis-prediction, arithmetic overflow.
May require nullifying wrong results; flushing the instructions in the pipeline; restarting the pipeline from the point of exception.
Error detection or correction: G06F 11/00.
Exception handling in genera: G06F 11/0793.
Attention is drawn to the following places, which may be of interest for search:
Instruction result nullification |
The group is only to be used for the handling of exceptions caused by instruction execution.
In this place, the following terms or expressions are used with the meaning indicated:
Architectural state | The runtime data in the pipeline resources, including program counter, instruction queue, status register, condition codes, general purpose and special purpose registers, rename data, pipeline registers etc. |
Exception, fault | Error caused by the execution of an instruction, e.g. floating point overflow; page fault; mis-speculation. |
This place covers:
Recovery using multiple copies of architectural state;
Restoring the architectural state to that previous to an exception using a previous version of the state, e.g. checkpoint, future file, shadow registers. Also known as rollback.
Software debugging: G06F 11/362.
Attention is drawn to the following places, which may be of interest for search:
Shadow register structure |
The subgroup is only to be used for the handling of exceptions caused by instruction execution. In particular, checkpointing for software debugging is not meant.
In this place, the following terms or expressions are used with the meaning indicated:
Architectural state | the runtime data in the pipeline resources, including program counter, instruction queue, status register, condition codes, general purpose and special purpose registers, rename data, pipeline registers etc. |
This place covers:
Handling or nullification of an instruction exception, e.g. using exception flags, which does not occur in the cycle in which the exception is detected, but later, e.g. at writeback stage.
This place covers:
Concurrent execution using instruction pipelines;
Control of instructions moving through a pipeline of functional stages. A typical pipeline consists of these stages: Instruction fetch; Instruction decode; Operand fetching; Instruction issue; Instruction execution; Instruction completion/Result writeback;
Pipeline control, e.g. flushing, halting;
Pipeline stages, e.g. type of stage, number of stages;
Variable length pipeline, e.g. elastic pipeline;
Counterflow pipeline;
Cascaded pipelines.
Data-driven systems, e.g. tokens: G06F 9/4494.
Computer architectures for data-driven systems: G06F 15/82.
Attention is drawn to the following places, which may be of interest for search:
Specific instructions for pipeline control | |
Asynchronous pipeline control, e.g. using handshaking |
In this place, the following terms or expressions are used with the meaning indicated:
Pipeline | Series of linearly sequential execution stages for executing instructions. The stages have buffers between them for output data which is input into the next stage. The buffers may be clocked so that data from one stage moves into the next stage on a clock signal. All stages move at once, else an asynchronous pipeline. |
Counterflow pipeline | Pipeline in which instructions travel down pipeline, but data travels up pipeline. |
Cascaded pipeline | Parallel pipelines where a group of instructions are issued in successive cycles to produce a staggered execution of the group. |
This place covers:
Instruction pipeline synchronisation;
Timing aspects of instruction pipelines, e.g. clock cycle, derating;
Clocking of pipeline stages; clock domains;
Clock skew problems;
Clock gating in pipelines, e.g. for power saving;
Latches and buffers between pipelines stages.
Attention is drawn to the following places, which may be of interest for search:
Specific instructions for pipeline control. |
In this place, the following terms or expressions are used with the meaning indicated:
Clock skew | lack of synchronicity between instances of a clock signal caused, e.g. by differing clock wire lengths. |
This place covers:
Asynchronous pipeline, e.g. using handshake signals between stages, e.g. ACK, DONE signals.
Pipelines where the stages do not all move at the same time.
In this place, the following terms or expressions are used with the meaning indicated:
Asynchronous pipeline | Pipeline where not all stages move at once, e.g. execution in a stage starts when a signal is received from previous stage, and ends by sending a done signal to next stage. |
Handshake signals | Exchange of signals between stages, e.g. to inform a next stage when data is available to process, and to inform a previous stage when data may be forwarded. |
This place covers:
Pipeline with dynamically varying length, e.g. elastic pipeline.
Multiple pipelines having different lengths.
In this place, the following terms or expressions are used with the meaning indicated:
Pipeline length | The number of pipeline stages. |
This place covers:
Pipeline architecture where a single stage is split into sub-stages (e.g. superpipelining) using pipeline buffer, with higher clocking rate implied for that stage, e.g. pipelined execution unit; pipelined decode unit.
Pipeline architecture having multiple stages for the same function, e.g. two execution stages, without higher clock rate.
Attention is drawn to the following places, which may be of interest for search:
Pipelined decoding |
This place covers:
Concurrent instruction execution using slave processor or coprocessor which controls its own execution i.e. has a decode unit or sequencer;
Means and protocol to transfer instructions and data to a slave processor, and to receive results in return;
Detection of presence or absence of a slave processor;
Reconfigurable coprocessors i.e. not special purpose.
Vector processors: G06F, G06F 15/8053.
Cryptographic processors: G06F 21/123 .
I/O or DMA processors: G06F 13/12.
Image or graphics processors: G06T 1/20.
Digital data processing G06F 17/00, G06F
Attention is drawn to the following places, which may be of interest for search:
Execution units executing under control of a master decoder | |
Peripheral processor | |
Vector processor |
In this place, the following terms or expressions are used with the meaning indicated:
Host | master processor to which the coprocessor is a slave |
In patent documents, the following words/expressions are often used as synonyms:
- "COP" and "coprocessor"
This place covers:
Slave processors which receive and decode instructions which are not explicit in the instruction set of the host, e.g. commands; function calls; using an escape code; using memory-mapped commands;
Slave processors which are adapted to execute a non-native instruction set, e.g. Java coprocessor.
In this place, the following terms or expressions are used with the meaning indicated:
Non-native instruction set | Instructions which cannot be executed on the master processor |
This place covers:
Special arrangements or protocols for transfer of instructions or commands, and for exchange of data with a slave processor which executes non-native instructions.
This place covers:
Special arrangements for concurrent instruction execution using parallel functional units, implying the concurrent execution of multiple instructions, one in each of the functional units;
Parallel execution pipelines.
Arrays of processors G06F 15/78, G06F 15/80, G06F 15/16.
Attention is drawn to the following places, which may be of interest for search:
Parallel decode units | |
Concurrent execution using a slave processor |
This group is only to be used for special architectural arrangements to enable the concurrent execution of instructions, not for the mere presence of parallel functional units.
Parallel functional units does not usually mean parallel processors. Multicore architectures may be found here only if they carry out concurrent execution of instructions from the same program.
In this place, the following terms or expressions are used with the meaning indicated:
Functional unit | Unit within the processor which carries out part of the execution of an instruction. |
This place covers:
Multiple parallel functional units controlled by a single instruction, e.g. SIMD.
For SIMD execution, this class contains details relevant to the execution aspects, e.g. executing a global instruction according to local conditions.
SIMD architectures: G06F 15/80.
In this place, the following terms or expressions are used with the meaning indicated:
SIMD | Acronym for "single instruction multiple data" being an architecture having a set of homogenous execution units which execute the same instruction in any given cycle, but which each have their own operand data, e.g. vector data. |
This place covers:
Special arrangements at runtime for performing multiple iterations of a loop in parallel using SIMD lanes.
Attention is drawn to the following places, which may be of interest for search:
Reducing the execution time required by program code via optimisations performed during compilation | |
Software pipelining using a compiler | |
Distributing iterations of parallelizable loops among processors using a compiler | |
Parallelism detection by a compiler |
This place covers:
Runtime determination of a vector length used for performing multiple iterations of a loop in parallel.
Using a vector length variable stored in a vector length register for performing multiple iterations of a loop in parallel.
This place covers:
An execution model where multiple independent threads execute a same instruction in parallel, typically on different data elements (SIMT), where conditional instructions may cause different threads to follow divergent execution paths through a program, which may result in individual threads being inactive at times, and each thread may have its own instruction address counter and register state.
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
Processor architectures or configurations for image data processing |
Attention is drawn to the following places, which may be of interest for search:
Specific instructions to control multi-threading, e.g. FORK or JOIN instructions |
In this place, the following terms or expressions are used with the meaning indicated:
Warp | A warp is a set of parallel threads that execute the same instruction together. |
Thread Block | A thread block is a set of concurrent threads that can cooperate among themselves through barrier synchronization and shared access to a memory space private to the thread block. Once a thread block is assigned to a streaming multiprocessor, it is further partitioned into warps. |
Grid | A grid is a set of thread blocks that may each be executed independently and thus may execute in parallel. |
Streaming multiprocessor | A streaming multiprocessor executes warps and comprises multiple stream processors. |
In patent documents, the following abbreviations are often used:
SIMT | Single Instruction Multiple Thread |
CTA | Cooperative Thread Array |
GPGPU | General-Purpose Computing on Graphics Processing Units |
SM | Streaming Multiprocessor |
SP | Streaming Processor |
CUDA | Compute Unified Device Architecture |
OpenCL | Open Computing Language |
In patent documents, the following words/expressions are often used as synonyms:
- "CUDA", "OpenCL" and "GPGPU"
- "thread block", "work group" and "cooperative thread array"
- "thread" and "work item"
- "warp", "wavefront" and "thread group"
- "streaming multi-processor" and "compute unit"
This place covers:
Special arrangements, in a SIMT architecture, to handle different threads following divergent execution paths (e.g., control flow paths) through a program due to a conditional instruction.
Reconvergence of threads in a SIMT architecture.
This place covers:
Multiple parallel functional units controlled collectively by multiple instructions.
Includes special techniques of parallel functional unit control in a superscalar or VLIW architecture.
Hardware streams.
MIMD architectures: G06F 15/16.
This group is only to be used for special architectural arrangements to enable the concurrent execution of instructions, not for the mere presence of parallel functional units executing multiple instructions.
In this place, the following terms or expressions are used with the meaning indicated:
MIMD | Acronym for "multiple instruction multiple data" being an architecture having a set of homogenous execution units which execute different instructions in any given cycle, and which each have their own operand data. |
VLIW | Acronym for "very long instruction word" being an architecture having a compound instruction word formed by the compiler, containing multiple sub-instructions to be issued and completed together in one cycle, and having no interdependencies. |
Hardware stream | Hardware resources used for the context and execution of a stream or thread of instructions. |
This place covers:
Control of parallel execution by groups of functional units, such as multiple execution units sharing local memory, e.g. clusters;
Partitioned architectures, e.g. for hardware multistreaming.
In this place, the following terms or expressions are used with the meaning indicated:
Cluster | Group of execution units with shared register resources. |
Hardware stream | Hardware resources used for the context and execution of a stream or thread of instructions. |
This place covers:
Multiple functional units which are controlled in tandem or cascade to carry out an instruction.
Multiple functional units controlled by the same instruction but not in the same cycle, e.g. multiplier-accumulator.
Hierarchical adders: G06F 7/50.
In patent documents, the following abbreviations are often used:
MAC | Multiplier-accumulator unit |
FMA | Fused multiplier-accumulator unit |
This place covers:
Multiple functional units which are controlled in tandem or cascade to carry out an instruction which is a complex operation, possibly over multiple cycles.
This place covers:
Parallel functional units controlled in tandem to execute complex operations using adaptable datapath.
Reconfigurable computer architectures: G06F 15/7867.
This place covers:
Execution of a single program.
Attention is drawn to the following places, which may be of interest for search:
Program initiating or program switching in the context of multiprogramming |
In this place, the following terms or expressions are used with the meaning indicated:
High level language | refers to what is commonly known in the art, i.e. a language containing human readable constructs intended to be used by a human programmer and to be translated to binary code for execution.The fact that it is theoretically possible to read, understand and directly program binary code does not qualify this type of code as HLL. |
Low-level language | language that provides little or no abstraction from a computer's instruction set architecture |
In patent documents, the following abbreviations are often used:
HLL | High level language |
This place covers:
Starting up or shutting down a computer system and loading of the operating system.
This place does not cover:
Security arrangements for bootstrapping |
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
For set top boxes |
Attention is drawn to the following places, which may be of interest for search:
Low level details of resetting means | |
Compiler bootstrapping | |
Installation of computer software | |
Fault tolerant booting | |
Details of Power-On Self Test (POST) |
In this place, the following terms or expressions are used with the meaning indicated:
Bootstrap | a simple program that begins initialisation of the computer's operating system |
In patent documents, the following abbreviations are often used:
IPL | Initial program load |
This place covers:
Initialisation of the processor and the processor's direct environment immediately after the initial reset signal.
This group deals with local issues - there is no network involved.
Includes:
- Initial microcode loading;
- Selecting the very first instructions to be executed after a hardware reset;
- Processor address boot facilities;
- I/O channel initialisation;
- Making BIOS ROM invisible after booting;
- Means to shadow BIOS from ROM to (faster) RAM.
Attention is drawn to the following places, which may be of interest for search:
Loading microcode per se | |
Configuring of multiprocessors |
This place covers:
Initialisation of processors in a multiprocessor system immediately after the initial reset signal.
Attention is drawn to the following places, which may be of interest for search:
Configuring of multiprocessors |
This place covers:
Loading of the operating system and the preparatory steps for loading the OS.
Also includes the launching of application programs once the OS has been loaded, and OS formats on storage devices.
This place covers:
Searching and selecting a bootable boot device.
This place covers:
Computer systems having more than one bootable OS
- Choosing one of the available bootable OSs and booting from that OS (dual-boot or multi-boot);
- Providing mechanical means to switch between the OSs (see US2006107029);
- When a computer is switched on for the first time, the user is required to choose one of the OSs available on the computer. Once an OS is chosen, the other OSs are made unavailable. The next time the computer is started, it will boot only the selected OS (see EP0794484).
Attention is drawn to the following places, which may be of interest for search:
Emulating one OS using another | |
Two active OSs, where one OS (the guest OS) is running as an application in the other OS (the host OS) | |
Multiple OSs running simultaneously in the context of a VMM | |
When one of this plurality of OSs serves as a backup OS in case of failure, recovery OS |
This place covers:
Initialisation and configuration of peripheral devices, insofar as this configuration is related to the interaction with the operating system.
Also deals with the configuration of the operating system in order to be able to interact with peripheral devices.
A peripheral device in this class should be understood as a passive entity, i.e. whose functioning is controlled by the host computer to which it is attached. Systems involving a host computer with attached devices that have processing capabilities of their own should be treated as a multiprocessor or a networked distributed system.
This initialisation/configuration does not have to occur during booting (although it typically does) - it can also take place e.g. when a device is hot-inserted (plug and play).
This group deals with local issues - there is no network involved.
- Assigning IRQ lines, I/O addresses;
- Configuring registers on the peripheral;
- Device discovery: detecting which devices are present; building device trees;
- Adapting OS for device configuration;
- Device initialisation;
- Config.sys peripheral device facilities.
Loading or installation of device drivers. This does not necessarily have to occur at boot time.
Attention is drawn to the following places, which may be of interest for search:
Configuration of printer parameters | |
Updating of firmware in peripheral devices | |
Configuring software or OS when this configuration is not related to interacting with the peripheral device | |
Program control for peripheral devices - the inner workings of a device driver, i.e. how the driver performs its job of interfacing between OS & device, how the driver is structured, etc. | |
Electrical details of hot-plugging, plug and play | |
Peripherals with a processor and software running thereon together with the computer's processor can be considered a multiprocessor system. A distinction has to be made between the device driver - i.e. the software that runs on the host to interface with the peripheral - and the software running on the peripheral. | |
Reconfiguration of FPGAs, PLDs | |
HAVi networks | |
Configuration of network elements | |
Management of devices over a network |
A device driver is understood to be software used by a computer to control/operate a peripheral device. A peripheral is any kind of device that can be attached to/inserted into a computer in order to expand its functionality (modem, sound card, disk drives). A device driver- i.e. the piece of software that is loaded on a host computer and that enables the host computer to control the operation of an attached peripheral - differs from the peripheral's operating software - i.e. the piece of software that resides on the peripheral itself and executed by the peripheral's processor that allows the peripheral to operate as an independent unit.
In this place, the following terms or expressions are used with the meaning indicated:
Peripheral Internal | an expansion card that is plugged into one of the ISA/PCI slots |
Peripheral External | an external device connected through the serial/parallel port a PC card |
This place covers:
Arrangements for automating the process of device driver loading or configuration of a peripheral device or the operating environment of the computing element hosting the peripheral device in in response to dynamic changes in the peripheral constitution of the computing element (addition or removal of peripheral devices).
Plug-and-play in the context of this class occurs either during boot time or during run-time (live addition or removal).
This place covers:
The peripheral device itself contains all the information (or a reference to a place where the information is stored) required for its configuration and the configuration of the operating environment. In other words, it is the peripheral device and not the operating environment that is burdened with the task of providing configuration information or device drivers.
This place covers:
Booting of client computers, processors or devices that do not have the necessary boot code locally available but retrieve the boot code from a remote source, e.g. a boot server in a network environment.
Specific topics included:
- Booting of diskless computers ("net" computers);
- "Push" booting: a server computer boots a client computer by sending a boot program to the client computer;
- PXE (Preboot Execution Environment)
The Preboot Execution Environment (PXE) is an industry standard client/server interface that allows networked computers that are not yet loaded with an operating system to be configured and booted remotely by an administrator. The PXE process consists of the client notifying the server that it uses PXE. If the server uses PXE, it sends the client a list of boot servers that contain the operating systems available. The client finds the boot server it needs and receives the name of the file to download. The client then downloads the file using Trivial File Transfer Protocol and executes it, which loads the operating system.
- Booting a thin client in a "client device/data center" environment (see US2006/161765);
- Network booting;
- Booting diskless workstations;
- Booting thin clients.
Attention is drawn to the following places, which may be of interest for search:
Booting of multiprocessor systems, e.g. where one processor (the master) sends the boot or initialisation code to the other processors (slaves) | |
Wake-on-LAN (WoL) | |
BOOTP, DHCP protocol | |
Network protocols involving booting |
Remote booting in the context of a first-time and one-off installation of an OS is also classifed in the G06F 8/61.
In patent documents, the following abbreviations are often used:
RIPL | Remote Initial Program Load |
PXE | Preboot Execution Environment |
This place covers:
Suspend/Resume and Hibernate/Wake Up refer to techniques to put a system in a low power, non-operating mode, thereby preserving the system state that existed at the time of going into Suspend or Hibernate. The next time the computer is started, operation continues at the point where it left off, rather than starting from scratch.
- Speeding up the boot process by restoring persisted data from previous executions rather than going to the whole boot process.
- Hibernating a system to persistent storage on a first computer, transporting the storage to a second computer and resuming the execution there. Please note that this is not process migration.
- Multiple removable storage devices, each having a different hibernated system image stored thereon; resuming the different system images on one computer by switching the storage devices.
- Quickly bringing a computer into an operational state by copying a memory image from persistent storage to RAM, thereby bypassing the lengthy conventional boot process.
Attention is drawn to the following places, which may be of interest for search:
Low-level, electrical details of suspend and resume | |
Power Management | |
Normal Shutdown (without saving state information - the next boot starts from scratch) | |
Suspending a running process and resuming its execution later in the context of process scheduling | |
Booting a computer system when an error/ fault is involved. Includes Dealing with errors that occur during the boot process itself (e.g. when encountering a corrupt BIOS); * Rebooting the system after a previous irregular shutdown (e.g. due to a power failure), thereby restoring as much as possible the system state that existed before the irregular shutdown occurred. In absence of an emergency power supply, a power failure will cause the computer system to be simply powered down, inevitably resulting in the loss of system state. The next time the computer is booted, the system state will be restored as much as possible. | |
Graceful shutdown: When a power failure is detected, an emergency power supply (e.g. UPS) is activated giving the system enough time to do a proper shutdown (when shutting down a computer system, no state information is saved). Graceful hibernation:When a power failure is detected, an emergency power supply (e.g. UPS) is activated giving the system enough time to do a proper hibernation (thereby saving the system state) before eventually powering down. Dealing with power failures that occur when the system is in suspend mode, i.e. when the RAM is still powered; In battery-powered systems, suspending or hibernating the system when the battery level drops below a predetermined level | |
Wake-on-LAN |
The techniques of Suspension and Hibernation differ from each other in the degree of persistency of saving the system state.
With Hibernation, the system state is stored on a non-volatile memory device, e.g. HDD, while in the case of Suspension, the system state is stored in volatile memory (e.g. RAM).
In the G06F 9/4418 we only deal with situations where the reason or the system to suspend or hibernate is controlled/intentional e.g. after user presses power off button, after a preset period of inactivity for power saving purposes. When the reason to suspend or hibernate is the occurrence of a power failure, low battery voltage or another anomaly (e.g. system hang), then the document should be classified in G06F 11/1441 (see Related Fields). The subsequent restart of the system is classified in G06F 11/1417.
In this place, the following terms or expressions are used with the meaning indicated:
Hibernation | also known as Suspend-to-Disk (S2D) and is defined as sleeping mode S4 in the ACPI specification. |
Suspension | also known as Suspend-to-RAM (STR) and is defined as sleeping mode S3 in the ACPI specification. |
This place covers:
Shutting down the computer, the opposite operation of bootstrapping (G06F 9/442).
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
Suspend and resume | |
Graceful shutdown in case of power failure, e.g. using an uninterruptible power supply (UPS) |
This place covers:
Preparing a program for execution including the actual launching of the program.
This place does not cover:
Bootstrapping | |
Security arrangements for program loading or initiating |
Attention is drawn to the following places, which may be of interest for search:
Updating of computer software | |
Loading of microcode | |
Process Migration | |
Protocols for network applications involving the movement of software and/or configuration parameters, e.g. applets |
This place covers:
Run-time configuration of software and computer applications, for example:
Configuring the Windows registry;
User profiles: roaming (i.e. restoring the user's settings at a different computer), multiple users (i.e. each user has a different profile).
Attention is drawn to the following places, which may be of interest for search:
Configuration management in the context of software development | |
Configuration of peripheral devices | |
Configuration of FPGA, PLA | |
Gaming configure | |
Personalization of smart cards | |
Configuration of parameters specifically aimed at networking/communication | |
Protocols for network applications involving terminal/user profiles | |
Differentially changing configuration parameters |
Configuration wizards that assist a user in configuring a software application, are also classified in G06F 9/453 (Help systems).
This place covers:
Roaming user profiles; migrating configuration settings between computers.
Attention is drawn to the following places, which may be of interest for search:
Network-specific arrangements/protocols involving user profiles |
This place covers:
Ways to load program code whereby, rather than first loading the entire program code before starting execution, the program code is loaded only when needed.
Also includes:
- Saving memory space and preventing unnecessary processing by only loading the program parts that are actually used; Parts that are never executed are never loaded;
- Starting execution once certain parts are loaded: no need to wait for the whole program to be loaded;
- Executing instructions as they are loaded: the idea of streaming;
- Java constant pool resolution
- Dynamic linking/loading is also known as: incremental, partial, run-time, lazy; on-demand linking/loading.
In patent documents, the following abbreviations are often used:
DLLs | Dynamic Link Library |
This place covers:
Dynamically loading special software components to exisitng applications in order to extend their functionality, e.g. Adobe Flash-Player.
This place covers:
Determining the right version of a software component to be loaded.
This place covers:
Program loading explicitly taking into account hardware characteristics of the target.
Attention is drawn to the following places, which may be of interest for search:
Retargetable program installation/update |
This place covers:
Computer programs containing code native to multiple instruction sets (processor architectures).
This place covers:
Mechanisms to allow e.g. different versions of conflicting libraries to be used simultaneously; for example the Windows "DLL Hell".
This place covers:
How software components should be placed in a RAM, e.g. occupying neigbouring sections.
This place covers:
- Sharing program code/data between different applications in order to reduce the memory footprint;
- Solutions to problems that arise when program code/data is shared (e.g. sharing of global variables and Java static fields), often resulting in the duplication of program code/data.
This place covers:
Running programs without having to install or load them beforehand. Execute-in-place refers to running without loading (i.e. without copying to RAM), while portable applications more refer to running without installing.
This place covers:
Skipping or reducing the step of loading and initialization of program code.
Techniques used:
- XIP: eXecute-In-Place: execute programs from where they are persistenly stored. There is no program loading.
- Pre-initialise modules: program code may be loaded, but it is already partially or totally initialised
- Romization of program code
XIP (Execute In Place) refers to the execution program code directly from the memory where it is stored, without first loading the program code to volatile executable memory (RAM).
Where the G06F 9/445 relates to the preparatory process of making program code ready for execution - loading, i.e. transferring the code to executable memory; linking, i.e. resolving references; initializing data structures - XIP relates to methods where the program code can be directly executed without having to go through this preparatory process.
One definition of XIP, taken from US2002/069342: "A XIP architecture is defined by a system's ability to execute one or more bytes of code while still resident within non-volatile memory (e.g., read-only memory (ROM)), without first transferring the code to volatile memory (e.g., random access memory (RAM)."
Another definition of XIP, taken from US2004/193864: "A called execute-in-place (XIP) technology refers to a specific function provided with a storage device, which data or command codes stored in the storage device can be directly accessed by a central processing unit (CPU) in a computer system, without pass through a random access memory (RAM), thus reducing power consumption and data loss, and increasing executing speed."
For program code to be directly executable from the memory where it is stored, it is required that the memory is suitable to directly execute code (read US2002/138702, [0004]-[0008]), and that the code is in such a form that it can be directly executed.
Examples of XIP:
- In normal computer systems, directly executing program code from an externally connected memory device;
- In embedded systems, executing the software directly from the non-volatile memory where it is stored.
Also included:
- Romization, romizer: processes and tools to generate a directly-executable program image.
- Semi-directly-executable code: the code is partially prepared for execution, the rest takes place at load time.
The U3 technology does not fall under the XIP technology, because the program code is not executed directly from the USB stick.
This place covers:
Specific techniques to make code immediately runnable, e.g. making address adjustments (relocation) to enable immediate execution, or prebinding (Mac OS). General aspects of pre-runtime link editing are however classified in G06F 8/54.
This place covers:
Executing applications without installing them before, for example according to the U3 standard, or portable application packages ("Portable App") started directly from a USB stick.
This place covers:
Verification of program code, for example:
Java bytecode verification.
Proof carrying code.
inter instruction consistency checks.
This place does not cover:
High-level semantic checks | |
Prevention of errors by analysis, debugging or testing of software |
- In G06F 11/36 group, the question is: does the program do what it is expected to do? In other words, for a given input, does the program produce the expected output? The program is considered as a black box, only the external behaviour is studied. The tests that are performed do not take into account the implementation or the language that is used to write the program. We are here on the level of users/developers/specifications.
- In G06F 9/44589, a test is performed to see whether the (compiled) program code does not do anything that is not allowed by the rules of the target machine. In other words, the question is: does the program comply with code specific requirements?
The two groups are on a different level. It is possible for a program to respect all code specific requirements and thus to pass G06F 9/44589 tests, but not to produce the expected output and thus not to pass the G06F 11/36 test
- In the G06F 8/43 (Compile-time checking), source code is checked. In most cases, this is done by the compiler but it can also be performed by a separate program. In contrast, the G06F 9/44589 tests already compiled code. In the G06F 8/43, the verification is performed based on source code specific aspects, whereas in the G06F 9/44589 this is done on the basis of target machine related aspects
This place covers:
- Unloading program components from memory or terminating applications, e.g. when they are not needed anymore.
- Java class unloading: removing Java classes from memory when they are not used anymore, e.g. because the class has become "unreachable".
Class unloading is not the same as Garbage Collection: in class unloading, what is removed is program code in executable memory (classes), whereas in Garbage Collection it is data (objects, i.e. class instances) that are removed.
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
Uninstallation | |
Garbage collection |
This place covers:
Implementations of specific programming paradigms to execute computer programs, the programming paradigms being e.g. object-orientated, procedural, data driven or finite state machine
In this place, the following terms or expressions are used with the meaning indicated:
OO | Object-oriented |
This place covers:
Relates to procedural execution, i.e. imperative programming where the program is built from one or more procedures (subroutines).
This place covers:
Invocation and execution of subroutines, for example:
- Implementation of a call stack: creating and deleting activation records, reserving space on the stack to store local variables and to pass the arguments
- Argument passing
- Locating variables at higher level in the invocation chain
- Co-routines
- Re-entrant functions
- Function or method overloading: considering the type of all actual arguments/return type of a function to select a proper function instance to execute Calling functions in another programming language
Also covered are other combinations of several instructions, for example combinations of instructions to perform (counted) loops.
Attention is drawn to the following places, which may be of interest for search:
Hardware implementation of instructions that change the program flow to another address (jumps, branches, goto) | |
Remote procedure calls (RPC) | |
Stack caching |
In patent documents, the following words/expressions are often used as synonyms:
- Subprograms,subroutines, functions, procedures, object oriented methods
This place covers:
Finding the entry address of a subroutine and how to preserve the return address
Attention is drawn to the following places, which may be of interest for search:
Static linking, i.e. before load-time | |
Hardware implementation of instructions specifically designed to keep the return address (e.g. branch-and-link, jsr) | |
Branch prediction in a pipelined system | |
Dynamic linking, i.e. at or after load-time |
This place covers:
Execution aspects of object-oriented programs
In this place, the following terms or expressions are used with the meaning indicated:
OO | Object-oriented |
This place covers:
- Object-oriented method resolution, i.e. given a method invocation on a reference (pointer) to an object, how to locate the correct code that implements this method. Typically this is done using virtual function tables.
- Only deals with the resolution of an object-oriented method.
Attention is drawn to the following places, which may be of interest for search:
Remote method invocation (RMI) |
This place covers:
- Speeding up the run-time object-oriented method resolution by predicting the type of the referenced object
In patent documents, the following abbreviations are often used:
PIC | Polymorphic inline cache |
This place covers:
Object oriented class hierarchies including run-time addition of classes to a hierarchy virtual inheritance and/or polymorphism.
Attention is drawn to the following places, which may be of interest for search:
Object-oriented method resolution |
Documents in G06F 9/449 deal with Object-oriented method invocation and will inevitably talk about class hierarchies, which is the subject of G06F 9/4492. However, this alone does not justify classification in G06F 9/4492: only when the document discloses specific details about class hierarchies, the symbol G06F 9/4492 is justified.
In this place, the following terms or expressions are used with the meaning indicated:
Method overriding | subclass provides a specific implementation of a method that is already provided by one of its superclasses |
Polymorphism | creating a variable, a method or an object that has more than one form |
This place covers:
- Making objects persistent and restoring objects from persisted form.
Includes:
- Pointer swizzling
- Flattening objects
Attention is drawn to the following places, which may be of interest for search:
Serialization in the context of RPC, RMI | |
OO databases |
This place covers:
- Software aspects of data driven systems, i.e. systems where the action is dictated by the presence or availability of data at the inputs of the logical circuits, rather than by sequential instruction execution under supervision of a central clock
Attention is drawn to the following places, which may be of interest for search:
Specification techniques, e.g. Petri nets | |
Data flow analysis during compilation | |
Architectures for data or demand driven systems |
This place covers:
Unification is one of the main ideas behind logic programming, best known through the language Prolog. It represents the mechanism of binding the contents of variables and can be viewed as a kind of one-time assignment.
This place covers:
Program execution implemented by a Finite State Machine. There must be enough technical details about the FSM implementation to allocate the subgroup.
This place covers:
- The inner working of user interfaces, in particular graphical user interfaces (GUIs), including:
- Interaction of the GUI with applications and OSs
- The structure and interaction of software components of GUIs
- Implementation of GUI concepts typically used in operating systems, e.g. desktop metaphors, widgets or windowing mechanisms
- Implementation of GUI automation mechanisms, e.g. record/replay of user interactions on the GUI
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
User interfaces for testing or debugging software | |
User interface for databases, visualization of query results | |
User interfaces to web services | |
User interfaces for the field of automation |
Attention is drawn to the following places, which may be of interest for search:
Methods for a user to interact with the GUI, e.g. scrolling, drag and drop, menus | |
Digital output to a display device | |
Development and generation of source code for user interfaces | |
User interfaces for portable communication terminals, e.g. mobile phones |
In this place, the following terms or expressions are used with the meaning indicated:
User interface | is the space where interaction between humans and machine occurs |
In patent documents, the following abbreviations are often used:
HCI | Human-computer interaction |
MMI | Man-machine interaction |
CHI | Computer-human interaction |
GUI | Graphical user interface |
This place covers:
Methods to execute and interact with an application, whereby the application's program code runs on the server, and the GUI runs on the client (terminal). The user interacts with the remotely running application through the local GUI. GUI events/commands run back and forth between client and server. All processing is done at the server.
This place does not cover:
Protocols for virtual reality |
Attention is drawn to the following places, which may be of interest for search:
Communication between two running processes | |
Terminal emulation |
This place covers:
- Customizing the help according to the user's previous actions
- Getting help by pressing f1
- Wizards, application assistants, visual cues
- Online tutorials
This place covers:
- User interfaces in multiple human languages, adapting user interfaces to suit a foreign culture
- Game localisation
Attention is drawn to the following places, which may be of interest for search:
Pseudo-localisation | |
Processing or translation of natural language |
In this place, the following terms or expressions are used with the meaning indicated:
Language localisation | internationalisation (i18n), globalisation |
This place covers:
The emulation of entities, e.g. operating systems, processors, classified under G06F 9/00.
Attention is drawn to the following places, which may be of interest for search:
In-circuit emulation | |
Dynamic binary instrumentation may use techniques similar to emulators and binary optimizers | |
Virtual memory | |
Terminal emulation | |
Computer simulation, in which a model of a system under investigation is beng simulated |
In this place, the following terms or expressions are used with the meaning indicated:
Emulation | In computing, emulation refers to the duplication and imitation of the functions of one computer system/program by another computer system/program, different from the first one, so that the emulated behaviour fully or closely resembles the behaviour of the original system/program. |
This place covers:
Software implementation of a machine (computer) that executes programs like a physical machine:
- Java Virtual Machine (JVM);
- Microsoft .NET common language runtime (CLR);
- Smalltalk virtual machines.
This place does not cover:
Compile time binary to binary translation | |
Run-time interpretation of high level language programs | G06F9/4551 |
Run-time binary to binary translation |
This place covers:
Interpretation of high-level language code, e.g. BASIC.
Attention is drawn to the following places, which may be of interest for search:
Handling natural language data |
This place covers:
Giving commands to a computer (OS) by means of a (graphical) user interface.
These commands can be given via the command line or by performing actions on GUI objects.The commands are typically interpreted by a command interpreter.
- Scripts, recording and executing GUI command scripts.
This place covers:
The execution of binary code/bytecode that is not native to the current run-time execution environment by translating the non-native binary code/bytecode into native code just before execution and subsequently executing the native code .
Subsequently, execution can be optimised as follows:
- By performing a retranslation of the non-native binary code/bytecode yielding more optimal native binary code e.g. by taking into account run-time information;
- By directly transforming the native binary code yielding more optimal native binary code .
The G06F 9/45516 also deals with the initial and subsequent run-time transformation of native binary code into more optimal native binary code.
For the purpose of completeness, the G06F 9/45516 also deals with the translation of intermediate bytecode to a different intermediate bytecode (e.g. Java bytecode to UCSD P-code). This however, is a more theoretic possibility and will not occur frequently.
The majority of the documents in this class deal with the translation of intermediate bytecode to native binary code and more specifically with the dynamic compilation of Java bytecodes into native code (JIT compilation).
- The G06F 9/45516 is the dynamic counterpart of the G06F 8/52
Both classes have the same goal (i.e. translation from one binary format into another) but the point in time when this translation is performed is different: at run-time, just before or during execution (G06F 9/45516) and statically, pre-run-time (G06F 8/52).
- Because the translation in the G06F 9/45516 takes place just before execution, there is less time available
- Difference between G06F 9/45516 and G06F 9/3017
Both G06F 9/45516 and G06F 9/3017 deal with run-time translation of binary code. However, in the G06F8/455B4 the translation relates to a program as a whole and is realised by a software translator, whereas in the G06F 9/3017 the translation relates to individual instructions that are about to be executed and is performed by the processor's internal hardware and.
In G06F 9/45516, the processor is fed with the translated, native instructions; it doesn't know anything about the translation that took place. However, in G06F 9/3017 the processor is fed with the non-native instructions; translation into native code takes place on-the-fly (i.e. at the moment the instruction is actually executed by the internal hardware of the processor).
- Difference between G06F 9/45516 and G06F 9/45508
- The G06F 9/45508 is also related to the execution of binary, non-native code. However, the non-native code is emulated rather than translated: an emulator acts as an virtual machine and interprets the non-native code.
This place does not cover:
Run-time instruction translation | |
Profiling per se |
This place covers:
Translation of code at runtime prior to executing it natively, e.g. bytecode into native machine code. Dynamic compilation.
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
Translation of one binary program to another before the program is ever executed. Static binary translation. |
This place covers:
Optimisations carried out at runtime without changing the instruction set architecture.
This place covers:
Conversions or optimisations, e.g. done by JavaScript engines or similar plugin technologies built into another execution environment.
Attention is drawn to the following places, which may be of interest for search:
Dynamic loading of plugins/add-ons |
This place covers:
- Simultaneously executing multiple operating systems using a Virtual Machine Monitor (VMM). The following passage, taken from US2004230794, provides a good definiton of a VMM: 'A VMM enables plural operating systems to run on a single machine by "virtualizing" the entire machine. Conventionally, an operating system controls the use of the physical hardware resources of a machine (e.g., the memory, the processor, etc.), and thus the actual hardware of the machine is exposed to the operating system. When a VMM is used, however, the machine's hardware (e.g., devices) are only exposed to the VMM. The VMM, then, exposes "virtual" machine components to the operating systems'.In G06F 9/45545, plural operating systems execute simultaneously as guest and host (without a VMM)..
- Process switching for virtual machines;
- Handling of non-implemented instructions;
- Address trapping for emulating other memory architectures;
- Host/guest and mode switching instructions;
- Switching between endian modes (endian conversion on a bus G06F 13/40).
This place does not cover:
Loading of microprogram | |
Mode switching during interrupts per se |
This place covers:
Emulation of one OS by another OS
- Simultaneously executing first and second operating systems by executing the second OS as a guest OS on top of the first OS (the host OS). No virtual machine monitor (VMM) is needed. The use of guest and host OSs is described in the following passage, taken from US2004230794: ' Certain techniques allow operating systems to exist side-by-side on the same machine without the use of a virtual machine monitor. One such technique is to have one operating system act as a "host" for the other operating system. (The operating system that the "host" is hosting is sometimes called a "guest.") In this case, the host operating system provides the guest with resources such as memory and processor time '
- Interrupt handling of other OS
- Non I/O services of other OS, e.g. facilities for emulation of virtual memory
- Memory mapping and address trapping for emulating I/O
Associated address trapping is in G06F 9/45533.
This place does not cover:
I/O emulation |
This place covers:
A bare-metal hypervisor runs directly on the host's hardware to control the hardware and to manage guest operating systems, e.g. Citrix XenServer, VMware ESX, Microsoft Hyper-V..
This place covers:
Hypervisor runs within a conventional operating system environment.
This place covers:
Para-virtualisation is a virtualization technique that presents a software interface to virtual machines that is similar but not identical to that of the underlying hardware.
This place covers:
Mechanisms to adapt the instruction set of a guest system to the instruction set offered by the underlying hypervisor and/or native processor.
This place covers:
- Management and integration aspects of hypervisors.
- Functions needed to manage virtual machines or to integrate them into the execution environment that are specific to a hypervised system, e.g. handling of virtual machine instances, creating, cloning, deleting instances, starting and stopping virtual machines, distributing and migrating instances, managing I/O and storage access, isolating virtual machines for security reasons, managing memory of instances.
The following CPC breakdown codes are used for refined classification. Please also consider classification in the main trunk symbols referenced by the breakdown codes.
This place covers:
Handling single instantations of virtual machines, e.g. creation from template or copy of another instance.
This place covers:
Virtual machines running within other virtual machines.
This place covers:
Managing the placement of virtual machine instances.
This place covers:
Specifics about start/stop in the context of virtual machines.
Attention is drawn to the following places, which may be of interest for search:
Program initiating | |
Task life-cycle in general |
This place covers:
Specifics about input/output within virtual machines, e.g. accessing storage, or external devices, using specific drivers.
Attention is drawn to the following places, which may be of interest for search:
Loading of device drivers | |
Internal functioning of device drivers |
This place covers:
Specifics about memory management within virtual machines, e.g. accessing and allocating memory.
Attention is drawn to the following places, which may be of interest for search:
Allocation of memory to service a request | |
Memory management in general |
This place covers:
Mechanisms to isolate virtual machine instances from other instances; protection of virtual machines.
Attention is drawn to the following places, which may be of interest for search:
Security arrangements in general |
This place covers:
Specifics to enable monitoring or debugging within virtual machines.
Attention is drawn to the following places, which may be of interest for search:
Monitoring and debugging in general |
This place covers:
Specifics to enable network access of virtual machines.
Attention is drawn to the following places, which may be of interest for search:
Network virtualisation | |
Network-specific arrangements for supporting networked applications |
This place covers:
aspects of multiprogramming, i.e. where more than one process / task is present and this presence is essential for identifying the problem and / or the solution; a process / task is defined here as a program in execution.
Attention is drawn to the following places, which may be of interest for search:
Object-oriented software design | |
Multi-threading at the hardware level | |
Saving and restoring the state of a system, i.e. hibernation | |
Batch processing | |
Suspend and resume task / process / thread execution without details on context saving and restoring | |
Saving and restoring the state of a mobile agent together with additional details on the mobile agent itself | |
Saving and restoring program state during debugging | |
Access rights for memory resources, e.g. access to memory according to privilege rings | |
Access rights associated to human beings or documents where the final aim is to enforce protection at the user level without giving technically relevant details on the multiprogramming implementation | |
Documents just mentioning a multiprocessing / distributed object-oriented systems and which focus on a specific use / application (e.g. e-commerce, monitoring, information retrieval, security) | |
Documents mentioning a transaction but dealing, in fact, with nothing more than techniques involving a request for a service, without any detail on the ACID (Atomicity, Consistency, Isolation, Durability) properties; e.g. e-commerce transactions | |
Cryptographic protocols | |
Network security protocols | |
Protocols for real-time services in data packet switching networks | |
Network protocols for data switching network services | |
Aspects already covered by G06F 9/48, G06F 9/50, G06F 9/52, G06F 9/54 | See special rules of classification of the corresponding classes |
Rule 1
When a document qualifies for one of the groups in the table of rule 2 below, the group G06F 9/46 should not be assigned.
Rule 2
The following table specifies the group to be assigned:
Technical details on | Group to be assigned |
Saving or restoring of program or task context | |
Saving or restoring of program or task context with multiple register sets. This group takes precedence over G06F 9/461 | |
Program control block organisation. This group takes precedence over G06F 9/461 | |
Structure and arrangements for distributed object oriented systems, e.g. CORBA, Jini, DCOM | |
Transaction processing, namely transactions involving the ACID (Atomicity, Consistency, Isolation, Durability) properties | |
Transactional memory, i.e. transparent support for the definition of regions of code that are considered a transaction, the support being provided either in hardware, software or with hybrid-solutions. This group takes precedence over G06F 9/466. For speculative lock acquisition, G06F 9/528 takes precedence | |
Specific access rights for resources, e.g. using capability register |
Rule 3
The following text specifies the groups which could be assigned in addition to the groups of rule 2 above, to cover further technical details; the group(s) identified as context information should also be checked and assigned, if relevant:
Further technical details on:
The structure of bridges between different distributed object-oriented systems
- Context information: G06F 9/465
The lookup of interfaces and/or the structure of lookup servers / repositories
- Context information: G06F 9/465
The handling of references to remote objects / namespace implementation details within the context of distributed object-oriented systems
- Context information: G06F 9/465
This place covers:
transfer, initiation or dispatching of tasks, i.e. programs in execution, either locally or within a distributed system
Attention is drawn to the following places, which may be of interest for search:
Specific details on power distribution and power saving | |
Scheduling of printer jobs | |
Instruction streams within a processor (e.g. hardware threads) and instruction level details | |
Suspension and resumption at system level (i.e. involving the bootstrapping) | |
Mere loading of code linked to the initiation | |
Details on the task context structure as well as on its saving and restoring | |
Scheduling in terms of space | See special rules of classification for G06F 9/50 |
Process migration in the context of load (re-)balancing, without any technically relevant detail on the migration itself | |
Mere starting of a backup application at a certain date/time | |
Low level (bus-related) details of interrupt handling and interrupt controllers | |
Mere starting of an antivirus application at a certain date/time | |
Scheduling of human resources |
Rule 1
When a document qualifies for one of the groups in the table of rule 2 below, the group G06F 9/48 should not be assigned.
Rule 2
The following table specifies the group to be assigned:
Technical details on | group to be assigned |
Initiation of a task by means of an interrupt, i.e. the aspects of handling/servicing an interrupt | |
InterruptI interrupt priority mechanisms. This group takes precedence over G06F 9/4812 | |
InitiationI of a task by means of an timer related interrupt. This group takes precedence over G06F 9/4812 | |
InitiationI of a task by means of an interrupt with variable priority. This group takes precedence over G06F 9/4812 | |
Initiation of a task by means of an interrupt with variable priority, said priority being time dependent. This group takes precedence over G06F 9/4812 and G06F 9/4831 | |
Initiation, transfer and dispatch of a task, i.e. a program in execution, by another program; creation, e.g. fork() system call, and initiation, e.g. exec() system call, of a task / process / thread, virtual machine in the same or different machine | |
Task life-cycle, e.g. stopping, restarting, resuming execution. This group takes precedence over G06F 9/4843. For scheduling algorithms and internal operation of a scheduler, G06F 9/4881 takes precedence | |
Resuming the execution of a task on a different machine, i.e. migration. This group takes precedence over G06F 9/4843. This group takes precedence over G06F 9/485. For migration for load balancing purposes, G06F 9/5088 takes precedence | |
Mobile agents, i.e. tasks specifically designed to migrate. This group takes precedence over G06F 9/4843. This group takes precedence over G06F 9/485. This group takes precedence over G06F 9/4856. For cloning and replication of mobile agents, only G06F 9/4868 should be assigned. For migration policy, e.g. auction, contract negotiation, of mobile agents, only G06F 9/4875 should be assigned. | |
Scheduling strategies for dispatcher, e.g. round robin, multilevel priority queues; internal operation of a scheduler | |
Algorithms for real-time scheduling of processes, i.e. scheduling taking into account the deadlines of the applications being executed. This group takes precedence over G06F 9/4843. This group takes precedence over G06F 9/4881. | |
Power and heat aware scheduling of tasks. This group takes precedence over G06F 9/4843. This group takes precedence over G06F 9/4881 |
Rule 3
The following text specifies the groups which could be assigned in addition to the groups of rule 2 above, to cover further technical details; the group(s) identified as context information should also be checked and assigned, if relevant:
Further technical details on:
Exception handling
- Context information: G06F 9/4812
Application starting, stopping, resuming
- Context information: G06F 9/485
Scheduling of tasks on multiprocessor systems
Scheduling of a set of tasks by taking into account precedence and dependency constraints, or time and/or occurrence of events
Scheduling of a set of tasks by taking into account constraints on resources, resource based scheduling of tasks
Internals of a task scheduler
In patent documents, the following words/expressions are often used as synonyms:
[scheduling in terms of time] | [with the acceptation of task scheduling, i.e. when to assign a task to a computing unit] |
[scheduling in terms of space] | [with the acceptation of resource scheduling, i.e. which resource(s) to allocate and how to partition them] |
It is the first interpretation, the one which can be found in the context of the G06F 9/48
This place covers:
selection, allocation and de-allocation of hardware and/or software resources, like servers, processes, threads, CPUs, memory; combination and/or partitioning of resources, e.g. cloud computing, hypervisors and logical partitions; mapping of tasks onto parallel / distributed machines; load balancing and re-balancing of resources in distributed systems.
This place does not cover:
Specific details on power distribution and power saving | |
Allocation of disk resources and storage resources in general not being RAM | |
Scheduling of printer jobs | |
Specific details on emulation and internal functioning of a virtual machine | |
Mapping of tasks onto multi-processor systems carried out at compile-time | G06F9/45M1 |
Pure scheduling aspects, i.e. scheduling in terms of time, without considering resource allocation | |
Garbage collection techniques | |
Allocation of human resources | |
Cryptographic protocols | |
Network security protocols | |
Protocols for real-time services in data packet switching networks | |
Network protocols for data switching network services | |
Allocation of resources within a printer / multifunctional peripheral |
Rule 1
When a document qualifies for one of the classes in the table of rule 2 below, the class G06F 9/50 should not be assigned.
Rule 2
The following table specifies the class to be assigned:
Technical details on: | Class to be assigned: |
Allocation of resources to service a request | |
Allocation of resources to service a request, the resources being hardware resources other than CPUs, Servers and Terminals This class takes precedence over G06F 9/5005 | |
Allocation of memory resources to service a request This class takes precedence over G06F 9/5005 This class takes precedence over G06F 9/5011 for documents detailing both the allocation and release of memory resources, the class G06F 9/5022 should also be assigned | |
Release of resourcesThis class takes precedence over G06F 9/5005 This class takes precedence over G06F 9/5011 For documents detailing both the allocation and release of memory resources, the class G06F 9/5016 should also be assigned | |
Allocation of processing resources, e.g. CPUs, Servers, Terminals, processes, threads, virtual machines | |
A llocation of processing resources by considering data affinity This class takes precedence over G06F 9/5005 This class takes precedence over G06F 9/5027 | |
A llocation of processing resources by considering the execution order of a plurality of tasks, e.g. taking priority or time dependency constraints into consideration. Candidates for this group are documents dealing with requests for composite (web) services, where the various components should execute in a certain order and resources for said execution should be assigned accordingly. Also included are documents dealing with "workflow" like systems, where a request to "execute" a project definition, comprising a set of interrelated actions, is sent to a server This class takes precedence over G06F 9/5005 This class takes precedence over G06F 9/5027 | |
A llocation of processing resources by considering hardware capabilities This class takes precedence over G06F 9/5005 this class takes precedence over G06F 9/5027 | |
Allocation of processing resources by considering the load This class takes precedence over G06F 9/5005 This class takes precedence over G06F 9/5027 | |
Allocation of processing resources by considering software capabilities, namely software resources associated or available to the machine, e.g. Web services offered by a specific machine This class takes precedence over G06F 9/5005 This class takes precedence over G06F 9/5027 | |
Partitioning or combining of resources This class should contain also documents dealing with cluster membership, i.e. assignment of a server to a certain group based on some criteria (see exemplary documents WO0156785, EP0805393). | |
Algorithms for mapping a plurality of inter-dependent sub-tasks onto a plurality of physical CPUs This class takes precedence over G06F 9/5061 | |
Grid computing, cloud computing With the expression grid / cloud computing it is meant an environment where multiple services are offered by the various members of the grid (often making use of idle periods), said members being usually located over a large scale network. Candidate documents should have at least one of the following concepts: i) set up of a grid, e.g. registering a new member, re-organizing the grid; ii) usage of a service in the grid, e.g. locating the member, servicing a request. This class takes precedence over G06F 9/5061 | |
Logical partitioning of resources; management and configuration of virtualized resources This group deals with the creation and management (e.g. allocation) of logical partitions and resulting virtual machines in multiprocessor systems; it also deals with the concept of virtualization in general, namely the mere management (e.g. creation, deletion) of an abstract, logical representation of a resource and its configuration (e.g. re-definition of its behaviour). This class takes precedence over G06F 9/5061 For documents detailing the migration of a virtual machine to a different node, the class G06F 9/4856 should also be assigned | |
Techniques for balancing or rebalancing the load in a distributed system by taking into account the load of the whole system | |
Techniques for balancing or rebalancing the load in a distributed system by migrating tasks / jobs / virtual machines This class takes precedence over G06F 9/5083 For documents detailing the migration of a task/job/virtual machine to a different node, the class G06F 9/4856 should also be assigned | |
Allocation of resources based on power and heat considerations |
Rule 3
The following table specifies the classes which could be assigned in addition to the classes of rule 2 above, to cover further technical details; the class(es) identified as Context information should also be checked and assigned, if relevant:
Further details on:
Allocation based on performance criteria
- Class to be assigned: S06F209/5001
Allocation based on proximity
- Class to be asigned: S06F209/5002
Indication of availability of resources
- Class to be assigned: S06F209/5003
- Context information: All groups belonging to G06F 9/50
Enforcing and/or taking into account lower and/or upper ceilings on resource usage in the context of resource allocation
- Class to be assigned: S06F209/5004
- Context information: All groups belonging to G06F 9/50
Cluster membership
- Class to be assigned: S06F209/5005
- Context information: G06F 9/5061
Dependency or time-specific aspects which are taken into account during the allocation
- Class to be assigned: S06F209/5006
- Context information: G06F 9/5038
Allocation of low-level processor resources, e.g. logical units, registers, cache lines, decoding stages
- Class to be assigned: S06F209/5007
Monitoring techniques used in conjunction with the CPU / thread allocation
- Class to be assigned: S06F209/5008
- Context information: All groups belonging to G06F 9/50
Offloading computations (e.g. because lacking some of the necessary capabilities)
- Class to be assigned: S06F209/5009
Allocation based on priority
- Class to be assigned: G06F 2209/5011
Creation, use, management of pool of resources
- Class to be assigned: S06F209/5010
- Context information: All groups belonging to G06F 9/50
Controlling aspects of an already submitted request, e.g. polling for a status, deleting / modifying the request
- Class to be assigned: G06F 2209/5013
Reservation of resources so as to have them ready at the time of the actual allocation
- Class to be assigned: G06F 2209/5014
- Context information: All groups belonging to G06F 9/50
Selection, by a broker, based on the submitted request, of an appropriate server via a registry or a yellow pages server
- Class to be assigned: G06F 2209/5015
Session management
- Class to be assigned: G06F 2209/5016
Task decomposition
- Class to be assigned: G06F 2209/5017
Selection of a thread / process within a multithreaded / multiprocessing machine, said selection being aimed to service a request
- Class to be assigned: G06F 2209/5018
Workload prediction within the context of CPU / process allocation and load rebalancing
- Class to be assigned: G06F 2209/5019
- Context information: G06F 9/5083, G06F 9/5088
Workload threshold within the context of CPU / process allocation and load rebalancing
- Class to be assigned: G06F 2209/5019
- Context information: G06F 9/5083, G06F 9/5088
remote execution techniques whereby program code is executed remotely from the client that initiated the execution and the client provides the code to the remote machine
- Class to be assigned: S06F209/5409
- Context information: All groups belonging to G06F 9/50
The expression "scheduling", in the patent- and non patent-documentation, can have two distinct meanings when referring to task and resources:
1) scheduling in terms of time, with the acceptation of task scheduling, i.e. when to assign a task to a computing unit,
2) scheduling in terms of space, with the acceptation of resource scheduling, i.e. which resource(s) to allocate and how to partition them.
It is the second interpretation, the one which can be found in the context of G06F 9/50.
This place covers:
Arbitrating access from tasks to shared resources (e.g. mutual exclusion), synchronising the execution of tasks with respect to each others (e.g. producer - consumer) ; a task is defined here as a program in execution.
Attention is drawn to the following places, which may be of interest for search:
Speculative instruction issuing and/or data consistency | |
Transaction processing | |
Arbitration of access on a bus | |
Concurrency management in a database |
Rule 1
When a document qualifies for one of the groups in the table of rule 2 below, the group G06F 9/52 should not be assigned
Rule 2
The following table specifies the group to be assigned:
Technical details on | Group to be assigned |
Barrier synchronisation | |
Algorithms to detect and / or avoid deadlocks when tasks interact with each other | |
Mutual exclusion algorithms, specific implementations of locks and other means to ensure a "correct" (from the concurrency point of view) access to a shared resource | |
Speculative execution beyond synchronisation primitives (e.g. busy lock). This group takes precedence over G06F 9/526; e.g. if a document discloses a mutual exclusion algorithm involving speculative execution beyond busy locks, then it should be classified only in the G06F 9/528 and not also in the G06F 9/526 |
Rule 3
The following text specifies the groups which could be assigned in addition to the groups of rule 2 above, to cover further technical details:
Further technical details on:
Low level features of atomic instructions (e.g. test & set) used to implement locks / mutual exclusion primitives
- Context information: G06F 9/526, G06F 9/528
Tokens (e.g. cooperative locking), token managers and lock managers
- Context information: G06F 9/526, G06F 9/528
Multi-mode locks, i.e. with locks specifying also a mode (e.g. read-write)
- Context information: G06F 9/526, G06F 9/528
This place covers:
Communication between tasks, i.e. programs, processes, threads in execution, either on the same machine or on different ones, where the multiprogramming aspect is relevant, e.g. Inter-Process-Communication.
Attention is drawn to the following places, which may be of interest for search:
Communication between a device and a CPU without any technically relevant detail on multiprogramming concepts or with device specific details | G06F 3/00, G06F 13/00, G06F 13/102 (for device drivers) |
Interaction of the user with the system, i.e. the GUI, and not between the Processes / applications subsequent to the user interaction | |
Communication which does not involve multiprogramming concepts, e.g. invocation of a subroutine | |
Pattern-adapters | |
Non-remote method invocation between objects | |
Architectural details, e.g. interface repositories, object adapters, on distributed object-oriented systems, e.g. CORBA, DCOM Communication-specific details of the remote method invocation should (also) be classified in G06F 9/548 | |
Allocation of a remote service to a client | |
Communication between tasks but predominant aspect peculiar of another field, e.g. monitoring, information retrieval on the web, software download and installation | |
Addressing memory | |
Hardware mechanisms for inter-CPU communication | |
Collaborative editing on a file without any technically relevant details on the event handling aspect | |
Cryptographic protocols | |
Event management relating to network management, e.g. alarms produced by network devices, and no technically relevant details on the multiprocessing aspect is present | |
Messages being distributed over a network, i.e. e-mails, instant messaging | |
Network security protocols | |
Protocols for real-time services in data packet switching networks | |
Network protocols for data switching network services |
Rule 1
When a document qualifies for one of the groups in the table of rule 2 below, the group G06F 9/54 should not be assigned.
Rule 2
The following table specifies the group to be assigned:
Technical details on | Group to be assigned |
Adapter mechanisms e.g. between incompatible applications | |
Communication between tasks, either on the same machine or on different ones, by subscribing to events and issuing event notifications when certain events happen, e.g. Event Management Systems, Unix alarms; communication aspects related to the broadcasting of the notifications | |
User-generated data transfer from the process / application point of view, e.g. clipboards, dynamic data exchange (DDE), object linking and embedding (OLE) | |
Communication of processes via buffers, shared memory, pipes, sockets and the like | |
Communication between tasks residing in different layers e.g. user- and kernel-space | |
Communication of processes via a message passing system, i.e. messaging middleware, and the inherent technicalities, e.g. message structure or queue handling; delivery of messages according to preferences of the recipients (which have to be processes) | |
Implementation of Remote Procedure Calls, e.g. stubs, (un-)marshalling of parameters, namely invocation of a procedure at a remote location; lightweight RPC, i.e. procedure call between protection domains / different address spaces on a single machine | |
Implementation of Remote Method Invocations, i.e. details which are peculiar to RPC between (mainly Java and COM) objects, e.g. object serialization, stub / proxy download. This group takes precedence over G06F 9/547. |
Rule 3
The following text specifies the groups which could be assigned in addition to the groups of rule 2 above, to cover further technical details:
Further technical details on:
Communication aspects related to task execution in a client-server system
- Context information: All groups belonging to G06F 9/54
Interception of communications between tasks / layers
- Context information: All groups belonging to G06F 9/54
Handling of events within a single system, e.g. Unix alarms
- Context information: G06F 9/542
Distributed event management systems or handling of events produced in a distributed system
- Context information: G06F 9/542
Event handling related to the execution of a GUI and as long as the event handling aspect is technically relevant
- Context information: G06F 9/542
Broadcasting / multicasting and sequence related problems of event related messages and as long as the network aspect, if any, is not predominant
- Context information: G06F 9/542
Exchange of messages between processes by using a Message Oriented Middleware, e.g. Java Messaging Services
- Context information: G06F 9/546
Particular techniques for handling message queues (or similar structures)
- Context information: G06F 9/546
Remote execution techniques whereby program code is executed remotely from the client that initiated the execution and the client provides the code to the remote machine
- Context information: All groups belonging to G06F 9/54
This place covers:
- Error avoidance (G06F 11/004);
- Identification related to error detection/correction or monitoring (G06F 11/006);
- Reliability and availability analysis of computing systems (G06F 11/008);
- Error detection and/or correction (G06F 11/07);
- Detection or location of defective computer hardware by testing at a time outside of "normal operating mode", e.g. during standby, idle time or at power on (G06F 11/22);
- Checking the correct order of processing (G06F 11/28);
- Monitoring on computing systems (G06F 11/30);
- Prevention of errors by analysing, debugging or testing of software (G06F 11/36).
This place does not cover:
Error detection, correction or testing in information storage based on relative movement between record carrier and transducer | |
Monitoring, i.e. supervising the progress of recording or reproducing | |
Checking stores for correct operation; Testing stores during standby or offline operation |
Attention is drawn to the following places, which may be of interest for search:
Testing of electronic circuits | |
Testing or monitoring of control systems or parts thereof | |
Methods or arrangements for verifying the correctness of marking on a record carrier | |
Monitoring patterns of pulse trains | |
Coding, decoding or code conversion, for error detection or error correction; Coding theory basic assumptions; Coding bounds; Error probability evaluation methods; Channel models; Simulation or testing of codes | |
Arrangements for detecting or preventing errors in the information received | |
Arrangements for monitoring or testing data switching networks | |
Network arrangements, protocols or services for recovering from a failure of a protocol instance or entity |
The error detection or correction process in neural networks is also covered (G06F 11/1476).
In this place, the following terms or expressions are used with the meaning indicated:
fault | physical defect, imperfection or flaw that occurs within some hardware component, or logical defect of a piece of software. Essentially, the definition of a fault, as used in the fault tolerance community, agrees with the definition found in the dictionary. Faults may be permanent, transient or intermittent. |
error | the logical manifestation of a fault, observable in terms of incorrect instructions of or corrupted data in a (computer) system. For example, a fault in a DRAM cell will never be observed if the memory location is never accessed. Specifically, an error is a deviation from accuracy or correctness. |
failure | the incorrect functioning of a system as perceivable by a user or the system's environment as a consequence of an error. A failure is the non-performance, the untimely performance or the performance in a subnormal quantity or quality of some action that is due or expected. |
redundant hardware | additional hardware for performing the same function as another hardware part, provided that in faultless operation you could renounce on either hardware parts of the system without losing functionality. |
data representation | a physical or logical encoding (scheme) for data, which allows the latter to be processed, stored or transmitted by a machine. |
redundancy in data representation | a representation of data using more resources than strictly necessary to encode the desired information such that in the error free situation one could renounce some of said resources without losing information. |
redundancy in operation | performing (a set of) operations more than once, performing sequentially different implementations of a particular function or performing additional operations which (allow to) restore a system in a state from which its correct operation can be resumed after a failure. |
time diversity | the concept to have a redundant system in which one of the redundant components operates with a delay with respect to the other in order to avoid common mode failures that would affect both redundant components in the same way at the same time, thereby not being detectable/correctable. |
master-checker setup | a redundant configuration in which a master CPU drives the system. The checker CPU is synchronized (often at clock level) with the master. It processes the input data stream as the master (and often also the very same program). Whenever the master drives an output signal, the checker compares its own value with the data written by the master. A mismatch triggers an error signal. The master-checker mode is supported in many modern microprocessors by a comparator integrated into the pin driver circuitry, thus reducing the external logic to a few chips for interfacing the error signals. The master-checker system generally gives more accurate answers by ensuring that the answer is correct before passing it on to the application requesting the algorithm being completed. It also allows for error handling if the results are inconsistent. Depending on the merit of a correct answer, a checker-CPU may or may not be warranted. In order to alleviate some of the cost in these situations, the checker-CPU may be used to calculate something else in the same algorithm, increasing the speed and processing output of the CPU system. There are two possible configurations: Master-Listener and Cross-Coupled. The Master-Listener lock step configuration pairs two processors, with one as a complete Master and the other as a complete Listener, the latter having disabled output drivers. In the Cross-Coupled configuration, one of the processors, the SI-Master, drives the system interface bus, while the other processor, the SC-Master, drives the secondary cache bus. The SI-Master has disabled output drivers for the secondary cache interface bus while the SC-Master has disabled output drivers for the system interface bus. |
normal operating mode | the operation of a system or software once it is deployed and provides the desired service as opposed to its development, maintenance, test or idle time. |
fault masking | hiding the presence of a fault to the user or the environment of a (computer system by means of some sort of redundancy such that the perceived system functionality is not affected. |
active fault masking | taking particular actions (e.g. reconfiguration or failover) not performed in the error free situation to mask a fault. |
passive fault masking | when a system operates such that no particular action is necessary to mask a fault because all necessary operations are constantly performed independently of the presence of a fault (e.g. majority voting). |
interconnection | physical media and may be of point-to-point type or of bus type. Two interconnections are only considered redundant if: they both physically connect the same nodes, wherein nodes are the source producing or the final destination consuming the data to be transmitted, and are configured to perform the same data transmissions. |
monitoring | observing and/or measuring parameters or status of a running system. |
mirrored data | two copies of the data where it is supposed that both copies contain the same data at any moment. |
backed up data | the second copy of the data reflects the data of the first copy at a particular moment. |
In this group the use of the Indexing Codes G06F 2201/00 and lower is mandatory.
This place covers:
All measures taken to prevent an error from happening. This can either be by preventing the fault from being present or by ensuring that the presence of the fault will not lead to an error.
This place does not cover:
Measures in response to the occurence of a fault, e.g. measures designed to limit the impact of the error |
In this group the use of the Indexing Codes G06F 2201/00 and lower is mandatory.
This subgroup is only to be used for subject-matter for which no other technique (like fault-masking based on redundancy) to respond to the occurrence of a fault applies. If techniques corresponding to G06F 11/07 and subgroups apply, the subject-matter must be classified there instead.
In this group the use of the Indexing Codes G06F 2201/00 and lower is mandatory.
This place covers:
Reliability theory describes the probability of a system completing its expected function during an interval of time. In reliability theory availability is the degree to which a system is in a specified functioning condition. In the literature various definitions can be found. One well established defines availability as "the probability that a system is operating at a specified time t", Barlow and Proschan: Mathematical Theory of Reliability (1975). A simple representation of availability is a ratio of the expected value of the uptime of a system to the aggregate of the expected values of up and down time. For example in the case of systems having a MTBF (Mean Time Between Failure) and MTTR (Mean Time to Recovery), availability = MTBF/(MTBF + MTTR). Typical terminology that the group contains: error prediction, failure rate, predictive maintenance, longevity, etc. A lot of documents deal with pure theory and propose new formula for better assessing a system in terms of reliability.
This place does not cover:
Forecasting, planning |
In this place, the following terms or expressions are used with the meaning indicated:
Reliability | The term refers to the ability of a system or component to perform its required functions under stated conditions for a specified period of time. |
Availability | The ratio of the total time a functional unit is capable of being used during a given interval to the length of the interval. |
Downtime | The term downtime is used to refer to periods when a system is unavailable. |
Uptime | Part of active time during which an equipment, machine, or system is either fully operational or is ready to perform its intended function. |
MTBF | Mean Time Between failure is the predicted elapsed time between inherent failures of a system during operation. |
MTTF | Mean Time to Failure is the time taken for a part or system to fail for the first time. |
MTTR | Mean Time To Repair is a basic measure of the maintainability of repairable items. It represents the average time required to repair a failed component or device. |
MTTR | Mean Time To Recovery is the average time that a device will take to recover from any failure. |
This place covers:
- Error detection/correction on computing systems using redundancy in data representation (also includes RAID systems involving parity) (G06F 11/08 and subgroups).
- Error detection/correction on computing systems using redundancy in operations (G06F 11/14 and subgroups).
- Error detection/correction on computing systems using redundancy in hardware (G06F 11/16 and subgroups).
- Error or fault processing without redundancy (G06F 11/0703 and subgroups).
- Safety measures (G06F 11/0796)
In this place, the following terms or expressions are used with the meaning indicated:
Fault | Physical defect, imperfection, or flaw that occurs within some hardware component, or logical defect of a piece of software. Essentially, the definition of a fault, as used in the fault tolerance community, agrees with the definition found in the dictionary. Faults may be permanent, transient or intermittent. |
Error | The logical manifestation of a fault, observable in terms of incorrect instructions of or corrupted data in a (computer) system. E.g. a fault in a DRAM cell will never be observed if the memory location is never accessed. Specifically, an error is a deviation from accuracy or correctness. |
Failure | The incorrect functioning of a system as perceivable by a user or the system's environment as a consequence of an error. A failure is the non-performance, the untimely performance or the performance in a subnormal quantity or quality of some action that is due or expected. |
Redundant hardware | Additional hardware for performing the same function as another hardware part, provided that in faultless operation you could renounce on either hardware parts of the system without loosing functionality. |
Data representation | A physical or logical encoding (scheme) for data, which allows the latter to be processed, stored or transmitted by a machine. |
Redundancy in data representation | A representation of data using more resources than strictly necessary to encode the desired information such that in the error free situation one could renounce to some of said resources without loosing information. |
Redundancy in operation | Performing (a set of) operations more than once, or performing sequentially different implementations of a particular function, or performing additional operations which (allow to) restore a system in a state from which its correct operation can be resumed after a failure. |
Normal operating mode | The operation of a system or software once it is deployed and provides the desired service as opposed to its development, maintenance, test or idle time. |
Fault masking | Hiding the presence of an fault to the user or the environment of a (computer system by means of some sort of redundancy such that the perceived system functionality is not affected. |
Active fault masking | Taking particular actions (e.g. reconfiguration, failover) not performed in the error free situation to mask a fault. |
Passive fault masking | When a system operates such that no particular action is necessary to mask a fault because all necessary operations are constantly performed independently of the presence of a fault (e.g. majority voting). |
Mirrored data | Two copies of the data where it is supposed that both copies contain the same data at any moment. |
Backed up data | The second copy of the data reflects the data of the first copy at a particular moment. |
This place covers:
The methods for error/fault processing on computing systems in normal operating mode that do not imply the use of any redundancy techniques. The error/fault processing, as it is defined in the subgroup, comprises one or more of the following steps:
- the error detection step (G06F 11/0751 and subgroups)
- the error/fault reporting/storing step (G06F 11/0766 and subgroups)
- the root cause analysis step of the error/fault (G06F 11/079)
- the remedying step (G06F 11/0793), wherein:
- the error/fault reporting/storing refers to collecting/storing of information related to the error/fault (e.g. a performing a memory dump after detecting an error).
- the root cause analysis of an error aims at identifying the initial cause of an error/fault.
- the remedying step refers to the actions taken on the computing system in order to overcome an error/fault.
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
Monitoring power failures | |
Responding to power failures | |
Error/fault processing in manufacturing/control systems/environment | |
Error detection, correction or monitoring in information storage based on relative movement between record carrier and transducer | |
Error in transmission systems (error detection/correction in data transmission) |
Attention is drawn to the following places, which may be of interest for search:
Exception handling during concurrent execution | |
Error/fault detection or recovery by retry | |
Error/fault detection by checking the correct order of processing of a system or a program | |
Monitoring per se, reporting or storing of non-error data | |
Protection against unauthorized use of memory | |
Computer security, e.g. detection of attacks, malware, unauthorised accesses | |
Fault management in networks wherein the error/fault is related to the data exchange protocols or to the network equipments (e.g. routers or switches) | |
Monitoring of traffic in a network or of network components (e.g. routers or switches) | |
Network security detection/protection against malicious traffic | |
Monitoring testing in wireless networks |
A document classified in G06F 11/0703 - G06F 11/0793 must receive at least one classification for the "functional aspect" and at least one classification for the "architectural context" according to the two following actions.
Action 1 – Classifying the functional aspect (see groups G06F 11/0751 - G06F 11/0793):
- Classifying the document in a subgroup corresponding to the most relevant functional aspect of the error/fault processing described in the document;
- G06F 11/0751 and its subgroups for the function of error/fault detection, e.g. comparing data to an error threshold;
- G06F 11/0766 and its subgroups for the function of error/fault reporting/storing, e.g. performing a memory dump after detecting an error;
- G06F 11/079 for the function of root cause analysis, e.g. determining the first error event causing the others;
- G06F 11/0793 for the function of error/fault remedying, e.g. executing a specific interrupt handler to clear the error/fault;
- A document can be classified in more than one group of the list defined above based on details of different functional aspects disclosed in the document.
Action 2 – Classifying the architectural context (see groups G06F 11/0706 - G06F 11/0748):
- Classifying the document in a subgroup ) corresponding to the most relevant architectural context described in the document;
- A document can be classified in more than one group under G06F 11/0706 based on details of different architectural contexts disclosed in the document;
- In case the document does not disclose any specific architectural context details or only refers to a general computer, the generic head group, G06F 11/0706, should be used.
This place does not cover:
Drivers for digital recording or reproducing units | |
Circuits for error detection or correction within digital recording or reproducing units | |
For distributed storage of data in networks, e.g. transport arrangements for network file system [NFS], storage area networks [SAN] or network attached storage [NAS] |
Attention is drawn to the following places, which may be of interest for search:
Monitoring per se, reporting or storing of non-error data |
This place does not cover:
Recovery from an exception in an instruction pipeline | |
By retry | |
For recovering from a failure of a protocol instance or entity |
This place covers:
A safe computer system protects its user(s) and/or environment from hazards whether its intended function is performed correctly or not. This group deals with measures taken to ensure that a computer-based system stays safe (i.e. does not present a danger to persons or its environment) when it is no longer able to provide its normal functionality due to the presence of an error. This requirement typically occurs in many real-time control systems. The subject-matter of is group is different from fault-masking since the latter attempts to maintain the desired functionality of a system in the presence of faults whereas this group relates to ensuring a safe condition when faults cannot be masked, thereby degrading the desired system functionality.
Attention is drawn to the following places, which may be of interest for search:
If such a system continues to operate albeit with degraded hardware or software functionality, additional classification symbols in the appropriate subgroups may be necessary. |
In this group the use of the Indexing Codes G06F 2201/00 and lower is mandatory.
This place covers:
Documents where the error detection/correction in a computer system is done by redundancy in the representation of the data.
Most often this redundancy arises from the fact that more bits are used to represent the data than strictly necessary. However, these groups cover as well cases where the data is stored twice, but in different formats (e.g. the second time using inverse logic).
However, subject-matter where 2 (or more) identical copies of the data are stored, is not treated here (see informative references)
This place does not cover:
Data with redundancy of data representation stored on storage with movable components | |
Error detection or correction codes per se | |
Transmission of data using redundancy of data representation |
Attention is drawn to the following places, which may be of interest for search:
Redundant storage of data |
Generally only 1 class is given. Only invention information is classified.
This place covers:
Subject matter where more bits are used to represent the data than strictly necessary, however without representing the data twice (or more often).
Subject-matter dealing with host-to-memory or host-to-host transfers is classified in this group per se, except when the protection is on the level of blocks of data (which is in G06F 11/1004).
Attention is drawn to the following places, which may be of interest for search:
Protecting a block of data words |
As soon as the redundant representation is stored on storage, the subject-matter should be classified in G06F 11/1076 and subgroups and not in other subgroups. This is independent of how the redundant representation is determined or what representation is used. Group is not used for classification.
In this place, the following terms or expressions are used with the meaning indicated:
Memory | solid state devices used as main memory which are either directly addressable by the associated CPU (meaning that they are located on the high speed bus), or are not addressable internal memories (such as registers and buffers). As such, memory is different from storage. |
Storage | media from which data needs first to be loaded before it can be used for computing. |
This place covers:
The use of checking codes on bigger units of data than a single word to detect the presence of errors in the data.
This group does not cover correction of data.
In this group, it is irrelevant for what purpose the checking is being used (e.g. for storing the data in memory, for transmission of the data to another component in the computing system, ...) as long as it is related to error detection.
Attention is drawn to the following places, which may be of interest for search:
Security arrangements for protecting computers or computer systems against unauthorized activity | |
Computer virus detection or handling | |
Using checking codes for detecting unauthorised modifications | |
Using checking codes in data communication |
This place covers:
That subject-matter where the error detection and/or correction is done on data stored in a single solid state device (i.e. the detection/correction is done when reading data from or writing data into the memory). It is independent of what function the solid state device has in the system. The relevant criterium is the type of component on which the data is stored (i.e. solid state devices in contrast to disks, tapes or other storage devices with moving components).
This place does not cover:
To protect a block of data words |
Attention is drawn to the following places, which may be of interest for search:
Protection of blocks of data being transferred (from memory to memory or between host and memory) | |
Parity RAID in storage |
G06F 11/1004 takes precedence.
This place covers:
This group and its subgroups cover specific code arrangements, i.e. documents describing how the ECC codes to be applied to the data are determined. As an example, documents describing row and column parity are classified here
G06F 11/1048 takes precedence.
Attention is drawn to the following places, which may be of interest for search:
Protection against unauthorized access to memory |
Not used for classification.
This place covers:
ECC codes where different bits of a data word are stored in different memory modules. Documents classified here, do not deal with calcualtion of ECC/EDC but only on where the data with the corresponding code is stored in the device (e.g. on different modules of the same device).
Attention is drawn to the following places, which may be of interest for search:
Parity distribution in a Redundant Array of Independent storage devices |
Only classify here when no other group applies.
G06F 11/1012 (code arrangements) takes precedence.
G06F 11/1048 (hardware arrangements) takes precedence.
This place covers:
This group and its subgroups cover coding where the hardware plays a role, e.g. to make the error correction or detection faster, to reduce the power consumption for detecting/correcting errors, ...
The hardware involved must be described.
Attention is drawn to the following places, which may be of interest for search:
Parity in RAID systems |
This place covers:
This group covers documents in which no error detection/correction by redundant coding is performed at all in the normal situation.
Subject-matter covering circuits where ECC/EDC codes are calculated in parallel during operation are to be classified in G06F 11/1048.
Not used for classification.
Attention is drawn to the following places, which may be of interest for search:
Memory refresh tehniques |
This place covers:
This group covers ECC when it concerns a feature which is specific to caches or content addressable memories.
For instance if an additional ECC is used for the cache with respect to the memory.
This place does not cover:
G06F 11/1072 takes precedence
G06F 11/1072 takes precedence
Documents classified in this group should be sent to G11C 29/00 as well.
This place covers:
Covers all subject-matter related to memories of which the cells can store more than 2 values.
Attention is drawn to the following places, which may be of interest for search:
Architectural details of multilevel memories |
Documents classified in this group should be sent to G11C 29/00 as well.
This place covers:
Redundancy using parity calculation and stripping in redundant arrays of storage devices such as :
- Hard Drives (e.g. RAID)
- Semiconductor memories (e.g. RAID of SSD/Flash disks)
- Optical Drives (e.g. RAID in ODD archives)
- Tape (e.g. RAIT)
Mirroring in RAID: G06F 11/2053
Use of parity in memories which do not constitute a redundant array and are close to the processor (e.g. ECC or arithmetic code in a semiconductor memory on the high speed bus): G06F 11/1008
This place does not cover:
Control as such of RAID system | |
Mirroring | |
Redundancy on a disk used for reproduction |
If the document can be classified in a subgroup of the G06F 11/1076, then it should not appear in the head subgroup. Only those documents which cannot be classified in one or several subgroups (e.g. G06F 11/108, G06F 11/1084 etc) have to be classified in the head subgroup.
It is important to evaluate whether the parity calculation aspect is present and if specifics about fault recovery / rebuilding are present in the document. If such topic is not present of if the document talks about general parity aspects mixed with other topics, the Indexing Code groups should be used.
In this place, the following terms or expressions are used with the meaning indicated:
RAID | Redundant Array of Independent Disks is a technique for implementing fault tolerance in storage devices. |
Rebuild | Action of regenerating lost data from redundant data present in available drives / memories. |
JBOD | Just a Bunch Of Disks represent a group of disks without particular redundant scheme implemented. |
This place covers:
Using the parity to reconstruct data which would otherwise have been lost when a storage device is failing or is removed.
When the reconstruction takes place once a new disk is available, G06F 11/1092 subgroup is used.
When the reconstruction takes place on a spare disk that was available, G06F 11/1088 subgroup is used.
This place does not cover:
Actual replacement of a failing disk |
In this place, the following terms or expressions are used with the meaning indicated:
RAID | Redundant Array of Independent Disks is a technique for implementing fault tolerance in storage devices. |
This place covers:
Although not fully consistent with the title of this group we consider that prophylactic additional saving-related measures like check-pointing, backing-up or state copying, which are performed before the occurrence of a fault in order to be able to recover or restore (at least partially) in case a fault occurs in the future, and which do not rely on hardware redundancy, are to be classified under this group.
The corresponding reverse operations of restoring and/or recovering and/or rolling back fit in naturally, since these are performed after the occurrence of a fault. The same holds for any type of redoing. All these activities are considered particular cases of error correction.
Retrying an operation may be part of an error detection mechanism when used in conjunction with a counting or time-out scheme. It may constitute an error correction when it is used to overcome a transient error. In both cases it is a mechanism used after the occurrence of a fault.
In this group the use of the Indexing Codes G06F 2201/00 and lower is mandatory.
This place covers:
The techniques covered by G06F 11/1402 imply at least an attempt to correct an error. They do not cover the detection as such, which may be found in G06F 11/1497 or G06F 11/1479.
Classification of documents relating to snapshots is done as follows :
- documents describing the use or creation of snapshots to deal with the detection or correction of errors are classified in G06F 11/00, and normally in subgroups of G06F 11/1402.
- documents describing other uses of snapshots (or creation of snapshots for such purposes) are not classified in G06F 11/00. They are classified in G06F 16/00 or G06F 3/06 unless the specific use is provided for in another classification place.
- General-purpose treatment of snapshots (e.g. management of valid snapshots, determining not needed snapshots, storage optimisation, ...) is dealt with in G06F 16/00 if the snapshots are on file level. If the snapshots are volume-based snapshots, they are dealt with in G06F 3/00 since they concern the management of storage space in this case.
In this place, the following terms or expressions are used with the meaning indicated:
Persistent data | Data which are still relevant after a normal power off/ power on cycle or a logoff/logon procedure. Typically, the user determines when such data should be modified or destroyed (since they are not relevant anymore).Thus, persistent data is not equivalent to data that is stored in a non-volatile manner, the latter merely giving an indication of the type of memory/storage used to save the data. Non-volatile data does not need to be persistent, but persistent data is always non-volatile. |
This place covers:
Measures taken inside the processor or relating to individual processor instructions. To implement these measures, additional hardware (such as registers) can be used. A necessary condition to classify here, is that the operating system is unaware of the measures taken.
This place covers:
The solution of a specific problem related to the functioning of the computer system(s) as a whole in contrast to a particular application functionality. It is intended to cover firmware level (e.g. BIOS), OS level, file system level and/or utilities.
This group is NOT intended to include database specific techniques. Note that if the solutions in these groups involve the use of particular software techniques covered in G06F 11/1479 /low, the documents should be classified there as well. See e.g. the comment under G06F 11/1438 relating to additional classification in G06F 11/1479.
This place covers:
Restricted to correction (attempt) of errors during or using the boot process.
Attention is drawn to the following places, which may be of interest for search:
Booting in general | |
Reboot as part of upgrading to verify the successful upgrade |
This place covers:
Reconfiguration meaning that the system undergoes modification of the components that make up the system or their arrangement in response to an error being detected. The components can be either hardware or software components.
Example:
- The system switches to a minimal video driver in case the normally used video driver does not give any image anymore.
Counterexamples:
- redistributing the load on individual processors of a multiprocessor system in an overload condition
- masking faults by reconfiguring redundant hardware (e.g. making a standby component primary, changing the role of disks in a mirrored pair, ...)
This place does not cover:
Software update in general | |
Checking for a new version of software when a failure occurs with the current version |
Attention is drawn to the following places, which may be of interest for search:
Isolating or reconfiguring faulty entities in data switching networks |
This place covers:
Potential to recover from errors during or after software update or upgrade or installation processes. Also applies when this process is performed by a specific update/install software or even by the application itself.
This place covers:
There is redundancy in the metadata used to access a given stored data item.
Examples are :
- File systems having redundant FATs or redundant tuples
- Redundant CMOS/BIOS data defining the disk layout
Counterexamples are :
- Retry a read from a disk sector by the disk controller when the read fails. This should be classified G11B 20/00
- Retrying the disk I/O request by the CPU. This should be classified in
Attention is drawn to the following places, which may be of interest for search:
File management in general |
This place covers:
The act of restarting a software module (e.g. an application, but not the complete OS, because this would imply a boot process which is covered in G06F 11/1417) either to recover from an error or in order to prevent an error (the latter being rejuvenation). The restarting or rejuvenating may be based on a previous state saving of the software module. Usually, this is based on a previously saved dynamic state of the software module. The dynamic state of a software application or process or task includes at least some of stack, heap, open files, etc. information, from which the application can later continue processing. Continuing from a previously saved state without full application restart is also covered by this group.
If the application restart or rejuvenation mechanism is implemented in an OS or middleware layer outside the application, this aspect is to be additionally classified in G06F 11/1482.
This place covers:
Measures taken out of a normal operating mode (after boot) but before abnormal termination of the system to enable a machine to continue processing from a defined state after a re-initialisation (reset or re-powering) of the machine. Example: power is monitored, when voltage drop is detected, the RAM is saved to disk. After power restore, RAM is reloaded from disk. Or, battery used to temporarily backup the RAM during a (short) power outage.
Without error see G06F 1/3203.
Attention is drawn to the following places, which may be of interest for search:
Means for saving power |
If a spare power supply is used, additionally G06F 11/2015 must be given (either as additional or invention, depending on the circumstances)
This place covers:
Examples :
- printer or disk I/O retry by the Operating System.
- Repeated requests by a client to the server
Attention is drawn to the following places, which may be of interest for search:
Detecting errors in the information received | |
Error detection mechanisms part of a communication protocol |
Documents should only be classified here when they concern transmit or communication errors and where the mechanisms used are not part of a communication protocol and no other group of G06F 11/14 and subgroups or G06F 11/16 and subgroups applies.
This place covers:
Backup done either on file or data block level. Covers, backing up of any type of file, independent of the data it contains.
Note: Due to considerable overlap in technology, backups and data backup systems frequently are confused with archives and fault-tolerant systems. However:
- Backups differ from archives in the sense that archives are the primary copy of data whereas backups are a secondary copy of data.
- Data backup systems differ from fault-tolerant systems in the sense that data backup systems assume that a fault will cause a data loss event, whereas fault-tolerant systems do not.
The scope of this group also covers ensuring that the data to be saved (as backup copy) is consistent (i.e. represents a meaningful state), especially if the copy is made of data within a distributed system.
Attention is drawn to the following places, which may be of interest for search:
Data replication | |
Mirroring | |
Data archiving |
This place covers:
All operations related to data management which are used for the backup data.
Examples of management of the data that is backed up :
- managing versions of backups
- formatting for compatibility with different systems
- consolidation of backed up data
Attention is drawn to the following places, which may be of interest for search:
File management in general |
Documents relating to authorisation control or data security of the backups should also be sent to G06F 21/00 for classification
This place covers:
- any determination of what data should be subjected to backup (e.g. what type of data, which origin of data, according to criticality of the data, ...)
- determining the necessity to include particular data (e.g. based on whether the data has changed)
- in what form the data should be backed up (e.g. incremental backup, full backup, differential backup, ...)
This place covers:
all techniques that are used to detect multiple copies of data items (e.g. files, data blocks, strings of data, ...) and to use this knowledge to optimize the backup (e.g. by not retransmitting the detected item, by not storing the detected item twice,...).
This is irrespective of whether the multiple copies are between (backups of) data at different times or between (backups of) different data items having a part in common or between (backups from) different hosts.
Attention is drawn to the following places, which may be of interest for search:
Redundancy elimination in general |
This place covers:
subject-matter where the hardware arrangement is affected by its use as backup system or where a particular system arrangement is proposed for backup. However, this does not imply that a particular hardware component must be physically modified for backup purposes
The following are some examples :
- additional (temporary) memory or storage is used to enable efficient writing on the backup medium
- storage which is configured to automatically perform a backup, when connected to a system to be backed up.
- A specific type of hardware being used for backup
A distributed architecture where some processing nodes are dedicated to particular backup functions
This place covers:
All operations related to the management of the backup process.
Examples are :
management of backup process :
- how to make the backup process faster
- avoiding data restoration by unauthorized persons
In this group the use of the Indexing Codes G06F 2201/00 and lower is mandatory.
Documents relating to authorisation control or data security of the backups should also be sent to G06F 21/00 for classification
This place covers:
Everything relating to arrangements in which the distributed architecture is of importance for the backup. Examples: Optimizing bandwidth, selecting machines (source or target) for backup, time multiplexed scheduling of backup clients, hierarchical distribution of backup control functionality to different networked machines.
This place covers:
All subject-matter dealing with techniques of limiting the impact of the backup process on normal operations, e.g. by minimizing the backup window.
This place covers:
Problems relating to restoring data from a backup using a backup/restore application (in contrast to data movement services of an OS). Examples: Finding and ordering the necessary tapes, handling a target format that is no longer the same as the original one, target system configuration has changed and new locations must be determined, improving restore efficiency.
Data migration from one machine to another one |
This place covers:
Logging techniques or the usage thereof for the purpose of attempting to recover from errors.
Ensuring that a log contains all necessary data to enable a restore.
Maintenance of the logged data (e.g. pruning obsolete entries to reduce the recovery time).
This place does not cover:
Journaling used as a data transmission mechanism for asynchronous mirroringCreating a consistent baseline of stored data for recovery to avoid long log processing at restore time is to be classified in other parts of | |
Journaling for asynchronous mirroring |
Attention is drawn to the following places, which may be of interest for search:
Logging in general | |
Logging in database systems |
In this place, the following terms or expressions are used with the meaning indicated:
Logging | recording physical or logical changes to stored persistent data to allow a system to recover from crashes or other errors and maintain the stored persistent data in a consistent state. |
Journal | is a chronological record of data processing operations. It is considered equivalent to logical logging. |
This place covers:
general recovery techniques of transactional systems; detailed techniques of transaction processing in database systems (e.g. ensuring ACID properties of updates in database systems) are not classified here.
Attempting to recover from errors within transactions that create/update/modify data. The term transaction is understood broadly.
Attention is drawn to the following places, which may be of interest for search:
Error recovery for (main) memory accesses implemented as transactions | |
Transactional file systems | |
Making database transactions atomic |
Documents being classified here that concern transactions in database management systems should be sent to G06F 16/20 for classification as well.
This place covers:
All techniques implemented by software means, i.e. where the fault tolerance does not result from the hardware and is not bound to a particular redundant hardware architecture.
Software architectures and structural approaches independent of the particular problem solved or function that is achieved. As a consequence, documents describing such technique for a particular purpose or hardware architecture as covered by the subgroups of G06F 11/14 and G06F 11/16 should be classified there as well. As a particular example for this see the comments under G06F 11/1482 relating to additional classification in G06F 11/1438.
Documents where the kind of fault tolerance used (active-active, voting, active-passive, ...) is fixed by the hardware architecture and cannot be influenced by the software, should not be classified in this group.
Examples are: Fault-tolerance using data-diversity (e.g. by using different equivalent input data sets for each retry of a function), corrective actions e.g. following a plausibility check. Other examples include measures taken before run time (e.g. duplication of instructions for comparison at compile time) or robust data structures (see XP745785).
Counterexample : the operating system for a Tandem Himalaya system will not be classified here, because it is bound to a hardware architecture that provides the fault tolerance and it does not employ any of the generic techniques covered by G06F 11/1479.
This place covers:
There is a software layer (on top of the operating system or integrated in the operating system) which makes applications which are not fault-tolerant run in a fault tolerant way. Typically, this is done by scheduling requests of the application more than once.
A typical example of this is fault tolerant cluster software.
Another example is an OS that detects a faulty process and creates a further copy of the same process on the same processor (but potentially in another memory area).
If the layer implements an application restart or rejuvenation mechanism, this feature is to be additionally classified in G06F 11/1438.
Documents where there is necessarily some hardware redundancy, get an Indexing Code as well in the HW redundancy groups.
Documents which describe said middleware/OS technique in combination with only one redundant hardware architecture always go into the G06F 11/16 and subgroups, but where said technique is explicitly suitable for other redundant hardware architectures, they are classified in G06F 11/1482 as well.
The restart related aspect of the second example is to be classified additionally in G06F 11/1438.
Note that G06F 11/1482 as such does not imply failover mechanisms, although the underlying hardware becomes redundant because of the software layer. Hence, this hardware redundancy aspect requires classification as well, in this particular case in G06F 11/2023 (example docs: US2003018927, US2003105852).
This place covers:
For error detection the output of multiple versions (typically based on different source codes) of the application code or portions thereof are compared or voted (note that this is different from an acceptance test as defined in G06F 11/1489). This can be in different programming languages, different compilers or implementation of alternative algorithms. The versions may be executed sequentially, concurrently or in parallel on different hardware (thereby making the latter redundant).
This place covers:
For error detection an acceptance test (mostly a plausibility check or a limit on execution time) is performed on critical code blocks. If the test is not passed, the output of another execution of the same or an alternative version of the block is used for recovery. The executions may be sequential or parallel. Note that an acceptance test is performed using the output of only one of the executions.
If the other execution is systematically performed on the same hardware, this has to be additionally classified in G06F 11/1497.
This place covers:
In contrast with G06F 11/1482, here the redundancy is inherent in the application itself. Thus, the application does not rely on any other layer to be fault-tolerant. The redundant portions are necessarily identical, since otherwise the redundancy is not realized at runtime, but is hard coded.
Attention is drawn to the following places, which may be of interest for search:
Replication implemented at OS- or middleware level is covered by | |
N-modular type | |
Details of time redundant execution on a single processing unit |
This place covers:
Using comparison or voting for the concurrently running replicas of the application software.
This place covers:
A piece of software (module, function, complete application, ...) is always executed two or more times sequentially or concurrently (e.g. as threads) on a single processing unit in order to address transient faults. In particular, this groups covers those aspects relating to the provision of the identical input to all executions of the software. When more than two execution are foreseen this can be used for error correction (not only detection). In particular, this group covers the techniques used to instantiate multiple executions of redundant software, the temporary storage of intermediary results or the duplication of contexts for each instance, as well as the measures taken for the subsequent error detection or fault masking. Note that this group also covers (non-redundant) hardware support for time redundant execution and, thus, cannot be a subgroup of G06F 11/1479.
This place covers:
- Systems where hardware redundancy is used to detect errors or to correct errors based on the output produced by the redundant components.
There are three types of hardware redundancy that can be found here:
The hardware redundancy is used for error detection only: such systems imply that there are at least (and normally only ) two redundant components, which are both active, the output of which is compared (G06F 11/1608, G06F 11/1629). Disagreement indicates an error.
The hardware redundancy is used for error detection and correction: such systems imply that there are at least three redundant components, which are all active, the output of which is voted. In the presence of an error the majority of correct outputs is used to correct the error. Since this is done without reconfiguration of the system, i.e. by ignoring the erroneous component(s), this is called passive fault masking (G06F 11/18).
The hardware redundancy is used for error correction only: such systems imply that there are at least one active component and at least one passive component suited to replace the active one in case the latter is failing. The detection of the failure is not (necessarily) based on hardware redundancy, however the correction of the error is. It requires a reconfiguration of the system as a result of which the functionality of the failing component is switched over to a spare (failover, takeover). This is called active fault masking (G06F 11/20).
In this context, voting and comparing are decision processes as to the correctness of the output of the system. This is in contrast to membership determination processes (which may also use majority building), which concern decisions on what the configuration of a system should be.
Testing of redundant computer hardware justifies an Indexing Code in appropriate subgroups of G06F 11/16. Testing of non-redundant but identical computer hardware (e.g. on a wafer) using comparison or voting techniques is G06F 11/22 only. Verifying components against a "golden master" is neither run-time nor fault-masking, this it is not G06F 11/16 but G06F 11/22 or G01R 31/00.
The subgroups fall apart in 2 types :
- "architectural groups", i.e. groups that specify constructional elements (i.e. G06F 11/1608 and G06F 11/1629)
- "functional groups", i.e. groups that define a particular functionality that is independent of the architecture (i.e. G06F 11/1666 and G06F 11/1675). These groups may be relevant for any type of hardware redundancy or fault masking.
Redundant hardware is a prerequisite to correct permanent (hardware) faults, but is equally successful with transient faults. Thus, G06F 11/18 and G06F 11/20 provide mechanisms that can successfully deal with both types of faults.
- Active fault masking implies a reconfiguration and, thus, a retry in the new configuration for the operation (or set of operations) that encountered the error. Otherwise there would not be error correction. Hence, to avoid double classification of (at least) all documents in G06F 11/20 there is the precedence rule under G06F 11/14.
Examples:
- Not every (symmetric) multiprocessor is redundant per se, because criteria (A) is not necessarily true. However, additional error detection and reconfiguration functionality typically implemented in software (OS or application level) could be used to make processors operate redundantly.
- A point-to-point connection that initialises to use as many parallel lanes as possible and automatically reconfigures itself to use less lanes following an error implies redundant communication media, because criteria (A) and (B) are both true.
See definitions in G06F 11/2002 and subgroups regarding redundancy in communications.
In this group the use of the Indexing Codes G06F 2201/00 and lower is mandatory.
Documents dealing with replication are classified in G06F 11/16 and subgroups (in particular in G06F 11/2094 and (G06F 11/2097 or G06F 11/1658) only when the purpose of the replication is for error handling or error detection. If the use is another one (e.g. performance or load balancing) or is not disclosed, the document should be classified in G06F 16/10 instead.
Some systems having a set of equivalent/similar hardware resources all used under normal conditions may be reconfigured in response to an error to use only a subset of these resources while still providing the same full logical functionality, however possibly with degraded performance.
In order to decide where such documents are to be classified, the following criteria are used:
- (A) If a reconfiguration mechanism is used following the error detection, we are in the presence of error correction using active fault masking.
- (B) If said mechanism is able to correct permanent hardware faults, this implies the presence of some form of redundancy in hardware.
If both criteria apply, the subject-matter is for G06F 11/20: A AND B => G06F 11/20.
Note in particular that:
G06F 11/14 (redundancy in operation) provides mechanisms that can ONLY deal successfully with transient faults.
In this place, the following terms or expressions are used with the meaning indicated:
Redundant hardware | additional hardware for performing the same function as another hardware part, provided that in faultless operation you could renounce on either hardware parts of the system without loosing functionality. |
This place covers:
- Systems with multiple clock generating components with active or passive fault masking, i.e. where the system is continuously clocked even in the presence of failing clock generators.
- Single clock generators that are fault tolerant in themselves, e.g. by comprising multiple oscillators.
- Arrangements that only detect clock faults based on redundancy at or in the clock generating level (typically by comparing signals output by two clock generators).
- The symbols G06F 11/1608, G06F 11/18 and G06F 11/20 are to be used where appropriate to capture the type of mechanism implementing the clock fault tolerance, if no EC symbol in the respective field is already given.
Note that this group does not require, that the clocked system itself is fault-tolerant.
This place does not cover:
Clock signal generation circuits/techniques as such even when redundancy is involved within such circuits | |
Appropriate clock signal distribution on ICs or between discrete components | |
Clock (phase) synchronisation in general, even when used to ensure the synchronous operation of multiple processors | |
Measures taken at clock level to achieve lockstep operation of redundant processing components | |
Time of day; time pieces | |
Oscillators, pulse generators or clock synthesizers | |
Oscillators, pulse generators or clock synthesizers if a loop in involved | |
Synchronisation of processor clocks representing time (time of day, logical/virtual time, real time clocks; NTP, PTP, UTC) |
Attention is drawn to the following places, which may be of interest for search:
Fault-tolerant synchronisation of clocks representing time | |
Error detection by comparing the output signals of redundant hardware | |
Checking static stores for correct operation is |
In this place, the following terms or expressions are used with the meaning indicated:
Clock signal | designates the common periodic square-waved signal on which synchronous digital components base their operations. This signal does not represent any absolute or relative real, logical or virtual time value (although such time may be derived therefrom by counting periods of this clock signal). |
Computing-related hardware the run-time behaviour of which is not controlled by software (e.g. ALUs, counters, decoders, ...). As soon as the redundant hardware under consideration, the output of which is compared, comprises a software programmable processor ((micro-)controller, CPU, microprocessor, ...), this should go to the G06F 11/1629.
Comparing is understood largely , i.e. it encompasses coherency checks (are the compared results similar enough to be considered the same or equivalent?) not only identity tests.
Processor(s) comparing the input from redundant sources (like buffers) are G06F 11/1608 as long as they do not compare their own results. The latter would have to be additionally classified in G06F 11/1629.
This place covers:
This group is intended to contain systems in which the redundant components are programmable (hardware) processors, the runtime behaviour of which is defined by software/firmware.
Comparing is understood largely , i.e. it encompasses coherency checks (are the compared results similar enough to be considered the same or equivalent?), not only identity tests.
FPGAs are programmable in respect of their configuration only. In general, the resulting run-time functionality thereof does not constitute a software controllable processor, thus systems comprising redundant FPGAs, the functionality of which is not run-time programmable, should be in 16B, as long as they form part of computer hardware.
Comparisons of input values are not to be classified here. They may, however, be for G06F 11/1608 as long as said input is produced by redundant sources. If such a comparison is used to detect errors in the transmission of data, this should be H04L 1/00. Redundant sources like sensors may be G05B rather than G06F (see also comments of G06F 11/1616).
This place covers:
This group is intended to comprise systems in which there is no comparator hardware. Instead, all redundant components send their respective output results to each other and each perform the comparison (in software) between their own output and the one(s) received from the other redundant components. This would cover processors exchanging results via a local (processor) bus as well as distributed system which communicate the results via LAN or other type of network.
- If there are more than 2 redundant units, this group applies only as far as there is no fault masking (this would be G06F 11/18).
- Redundant hardware comparators distinct from but directly associated with the redundant processing components go into G06F 11/1645.
This place covers:
- Consists of systems often denoted as master/checker in which there is no separate comparator unit. Instead, one or some of the redundant unit(s) (the checker(s)) do(es) additional work to perform the comparison, thereby detecting erroneous behaviour and checking the system for correct operation. The additional compare functionality may be implemented in hardware on the corresponding processing component(s), or in software executed by the corresponding processing component(s).
- Master/checker type architectures in which two processors operate in clock lockstep, where the checker compares the values driven by the master with its own corresponding internally present by otherwise disabled outputs. If a discrepancy is detected, the checker produces an error signal. See the glossary for citations of example master-checker structures. Note that this type of architectures also falls in the G06F 11/1654.
- Master/checker architectures where the checker is limited in processing functionality with respect to the master, even though this is not absolutely in line with our definition of hardware redundancy.
This place covers:
Here one or more hardware units separate from the redundant components are used to compare the results produced by the redundant components. Further details of subgroups
G06F 11/1645 and the comparison itself uses redundant hardware
This covers architectures in which there are comparator units (typically but not necessarily respectively associated with but) distinct from each one of the redundant processing components. The comparators are considered redundant when they perform the same comparison on (copies of) the same signals/data.
This place covers:
Documents in which an additional mechanism is provided to determine which one(s) of the redundant component(s) shall survive after the detection of the error. This may (but need not) involve a determination of which component is correct, in which case this redundant component can be used to correct the error in the other one(s) such that all redundant processing components can finally continue their operation.
However, since they are not based on a majority decision, (otherwise they would be G06F 11/18, see in particular G06F 11/181), the determination of the surviving component(s) is usually not done using redundancy in hardware. Rather, some diagnostics or simple priority rules, possibly based on prior behaviour are used.
Techniques in this group may use active fault masking, passive fault masking (i.e. ignoring the faulty component), or other techniques like retry. If these are described they should get an Indexing Code in the respective field as well.
This place covers:
- Here one of the processing components is usually called the "master", the other(s) may be denoted as slave(s), checker(s), or shadow(s). The master's: outputs drive the system. The slave's: outputs are used for comparison but are otherwise disabled from reaching other components of the system.
- Architectures in which both processors have a master and a slave role but for distinct parts of the system, i.e. for different types of output.
There may be an overlap of this group with G06F 11/1637 when the slave itself also performs the comparison, thereby making it a checker as well.
This group should only be used when there effectively is an asymmetry in the role of the redundant processors. On the contrary, the mere statement that a comparator or bridge or the like selects the outputs of one the processors to drive the attached components does not suffice to justify a different role of the processors.
This place covers:
The following types of data transfer activities (possibly using data replication) from a memory, the content of which is assumed to be good, to a one that is not yet current (note that the concerned memories do not need to be themselves redundant):
- sporadic resynchronisation processes used to reintegrate a redundant component into an active/active system, such process being started in an attempt to correct a fault for instance by rebooting a failing component or by replacing it.
- synchronisation processes occurring at start-up of some redundant active/active systems in which the redundant components have to negotiate when they are all ready to enter the lockstep mode of operation.
- initialisation processes used to make a redundant component ready to work as a stand-by in active/passive systems.
Documents in this group describing techniques in the context of active/passive systems should additionally have at least one Indexing Code in the G06F 11/20 (see also the comments in G06F 11/2097).
This place covers:
- Initialising data of a (newly activated) spare disk, provided this is not a mirror disk (the latter being in G06F 11/2082).
- Typical examples for this are the preparation of file system or database replica.
This place covers:
- The term memory is meant to comprise solid state devices used as main memory which is directly addressable by the associated CPU, as well as non addressable solid state internal memories (e.g. registers, buffers). It does however not need to be RAM.
- Redundant caches and main memory mirroring (in which case the Indexing Code G06F 11/20 should be given). One of the following Indexing Codes should be used where appropriate to better characterise the fault detection or correction mechanism involved: G06F 11/18, G06F 11/20.
- Error detection (or fault masking) using data replicated in different areas of the same memory device is also covered.
These documents differ significantly from the other mechanisms in G06F 11/1658 relating to (main) memory.
This place covers:
This the appropriate place for comparisons performed on the output of redundant memory (areas).
This place covers:
The 16T groups address the problem of ensuring that corresponding outputs of redundant active components are simultaneously available for error detection or correction at a given time. This does not imply that these outputs are produced simultaneously (see e.g. US2002116662). Such system are frequently said to operate in lockstep (at least at some level of abstraction).
Some active/standby systems using active fault masking, where a standby unit is to be maintained in close time synchrony with its primary , the standby unit thereby effectively maintaining itself current to be ready for failover. Documents of this latter type shall also get at least an Indexing Code in G06F 11/2097.
This place covers:
Here systems either use a common clock (clock lockstep) or are otherwise synchronised to such an extend that they produce comparable outputs within the same clock cycle, although not necessarily exactly in phase. If not using a common clock , the synchronisation measures taken affect the clock signal.
This place covers:
Here we have documents where the synchronisation occurs at statically predictable places in the code either after each instruction or after each instruction of a predetermined type (e.g. memory write or I/O operation) or by using explicit synchronisation instructions/operations.
This place covers:
- Synchronisation mechanisms that are triggered by events asynchronous to the main program. Typical example is synchronisation at the occurrence of an interrupt.
- Also cases in which the events are I/O operations performed in response to a polling mechanism.
This place covers:
Here the synchronisation process is initiated when a predetermined count (>1) of units of work is achieved.
This could be clock cycles, (selected types of) instructions, interrupts, I/O-operations, elapsed time units or any other suitable countable unit.
In most cases documents should also be classified in one of the other lower subgroups of G06F 11/1675
In this place, the following terms or expressions are used with the meaning indicated:
Quantum | A predetermined count (>1) of units of work |
This place covers:
Time diversity is the concept to have an active/active system in which one of the redundant components operates with a delay with respect to the other in order to avoid common mode failures that would affect both redundant components in the same way at the same time, thereby not being detectable by comparison. Typically the time delay is a small odd multiple of the half clock period. It has to be taken into account when comparing the outputs in order to compare outputs resulting from the same logical steps, which by definition are not produced simultaneously. (Should time diversity turn out to be a concept useable for active/passive system as well, this group would have to be moved one level up).
This place covers:
- Fault masking: hiding the presence of a fault to the user or the environment of a [computer system by means of some sort of redundancy such that the perceived system functionality is not affected.
- Passive fault masking: when a system operates such that no particular action is necessary to mask a fault because all necessary operations are constantly performed independently of the presence of a fault (e.g. majority voting).
In G06F 11/18 this is achieved by redundant active hardware components, the output of which is subjected to a (voting) process which ensures that only output considered correct is propagated in the system. Thereby, those redundant components which are in error are simply ignored, this resulting in a correction of the error(s) through the hardware redundancy.
Passive fault masking means that a system produces correct behaviour/outputs in the presence of faulty components.
Voting is a majority building process, by which the output agreed upon by a majority of the redundant components is selected as the correct one, thereby tolerating any minority number of erroneous outputs.
The subgroups fall apart in 2 types:
- "architectural groups", i.e. groups that specify constructional elements (i.e. G06F 11/182, G06F 11/183 and G06F 11/184, G06F 11/185)
- "functional groups", i.e. groups that define a particular functionality that is independent of the architecture (G06F 11/181, G06F 11/187, G06F 11/188).
This place does not cover:
With continued operation after detection of the error |
This place covers:
Documents including an elimination of a faulty component based on the results of a passive fault masking process, through which those components being in the minority are assumed to be the erroneous ones. They can, thus, be eliminated without the need for a separate fault location process. Note that this group implies that the fault masking as such is passive i.e. the correct system output can be produced before the faulty component is eliminated.
This place covers:
The voting process when it is performed in software by the redundant components themselves, based on their own output and the ones received from the other redundant components. There is no voter hardware.
Processors exchanging results via a local (processor) bus as well as distributed system which communicate the results via LAN or other type of network.
Redundant processing while the other groups at the same level are not.
A system having only a single redundant processing component performing the voting in software is covered as well.
This place does not cover:
Redundant voters distinct from but directly associated with the redundant processing components go into |
This place covers:
Here one or more hardware units separate from the redundant components are used to vote the results produced by the redundant components.
G06F 11/184 where the redundant components implement processing functionality
Documents where the outputs of redundant processors / CPUs / microcontrollers are voted to perform the passive fault masking.
G06F 11/185 and the voting is itself performed redundantly
Documents where the voting process itself is implemented using redundant hardware, i.e. where the voter does not constitute a single point of failure. The voter does not need to be implemented in hardware, but could be realised as software processes on dedicated voting processors.
Counter-example: each redundant component has a voting module in software, which uses the outputs produced by the other redundant components. This is G06F 11/182.
This place covers:
Specifics on how the voting process is performed in contrast to remaining G06F 11/18 groups which relate to architectural aspects of the systems.
This group is only used for voting for redundant hardware components. See G06F 11/1497 and G06F 11/1479 and subgroups for voting in the context of redundant software.
This place covers:
Concerns documents where the majority is formed by outputs which are considered equivalent, although not identical. This is frequent in control applications where inputs of the redundant components do not originate from the same source of information. or where they are gained at (slightly) different times. Tolerances or other plausibility or coherence criteria may be used to determine which outputs form the majority.
This place covers:
Head-group for all documents in which faults are masked actively, i.e. after the masking is done, the fault is not present anymore in the active part of the system. It is to be noted as well that we are talking exclusively about fault masking and not about error masking.
The subgroups fall apart in 2 types :
- "architectural groups", i.e. groups that specify the constructional element which is redundant (i.e. G06F 11/2002, G06F 11/202 and G06F 11/2053)
- "functional groups", i.e. groups that define a particular functionality that any active fault masking arrangement needs to implement (i.e. G06F 11/2097). This functionality is independent of the particular constructional element which is redundant.
A general concept in the field of active fault masking is that a surviving component takes over the load/work of failing one in addition to its own normal work. For such documents the symbol G06F 2201/85 should be used except for documents getting a dedicated group for this concept (e.g. G06F 11/2035).
In G06F 11/181 there are also documents dealing eliminating a faulty component. G06F 11/165 possibly uses active fault masking (to ensure the continued operation, some kind of decision is needed to identify one of both components as failed and this one may completely be removed from the system). However, since in those two groups the active fault masking is rather a consequence of the voting or compare, we decided to take this particular subject-matter out of the G06F 11/20.
Failover comprises one or more of the following activities:
- error detection : this is not a failover specific mechanism since there is no link between detection and failover => such docs to be classified according to the used mechanisms but not necessarily in G06F 11/20
- determination of the spare to be used
- activation of the determined spare
- declaration of the activated spare as primary
- elimination of the faulty unit
There is failover taking place as soon as any functionality of a hardware component is taken over by another hardware component, whatever the functionality is.
In this place, the following terms or expressions are used with the meaning indicated:
Fault masking | hiding the presence of an fault to the user or the environment of a computer system by means of some sort of redundancy such that the perceived system functionality is not affected. |
Active fault masking | taking particular actions (e.g. reconfiguration, failover) not performed in the error free situation to mask a fault. |
This place covers:
All cases where architectural components involved in communication are redundant, as long as no communication protocol layer independent of a particular application is involved.
Examples pertaining to subgroups of G06F 11/2002 are:
- Duplicate connection lines
- Redundant busses (serial or parallel)
- Redundant bus controllers (e.g. PCI)
- Network interface boards describing built-in redundancy
- A redundant setup of two network adapters which are not redundant in themselves
Fault tolerance in communications is for H04L rather than G06F 11/00 if the mechanism described is implemented by a communication protocol layer that is independent of a particular application.
Examples that should be classified in H04L :
- fault tolerant FTP protocol.
- client having a session management layer, the layer independently maintaining connections with a server.
- operations relating to establishing or cancelling connections between nodes.
- message replication or retry by a routing algorithm (even fault-tolerant routing);
- dealing with transmission errors occurring on the interconnection media (H04L 1/00)
Attention is drawn to the following places, which may be of interest for search:
Flexible arrangements for bus networks involving redundancy | |
Recovering from network faults | |
Fault tolerant routing |
The subgroups G06F 11/2005, G06F 11/2007 and G06F 11/2012 are to be used together in order to classify 9 different types of redundancy in this field. Regarding details of communication failover no subgroup is foreseen. This has to be searched using the other architectural criteria.
Example: Two PCs connected to a LAN by a respective LAN controller and additionally being connected to each other by a USB cable via respective USB controllers, where the USB connection can be used as alternative path to transmit the same data. This configurations gets all the three subclasses.
Remarks:
- A communication switch implements control logic to realise physical connections between a set of data input ports and a set of data output ports, thus, if not H04L 49/00 this is G06F 11/2005 .
- Data transfer between processors and memories is not considered communication (rather it is addressing), hence redundant interconnects between processors and memories is G06F 11/2002 (not G06F 11/2007).
Examples below illustrate how the scheme should work in some typical situations:
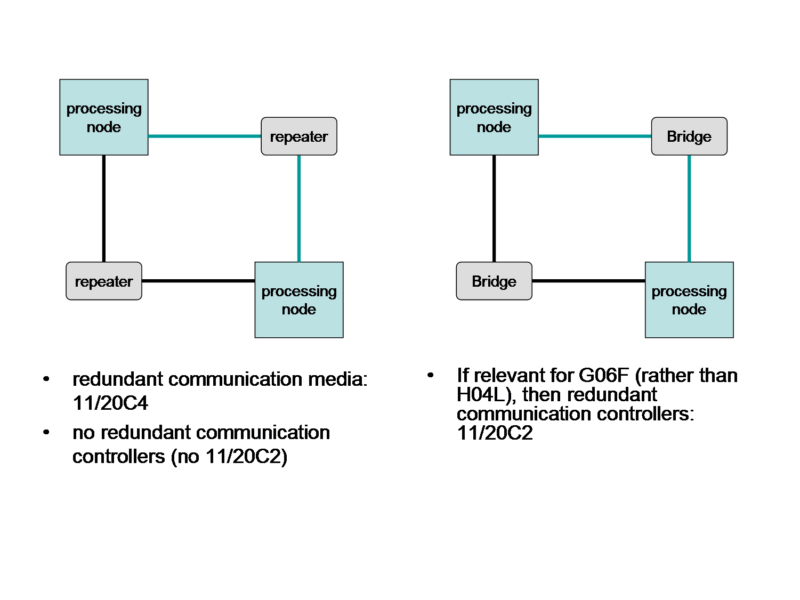
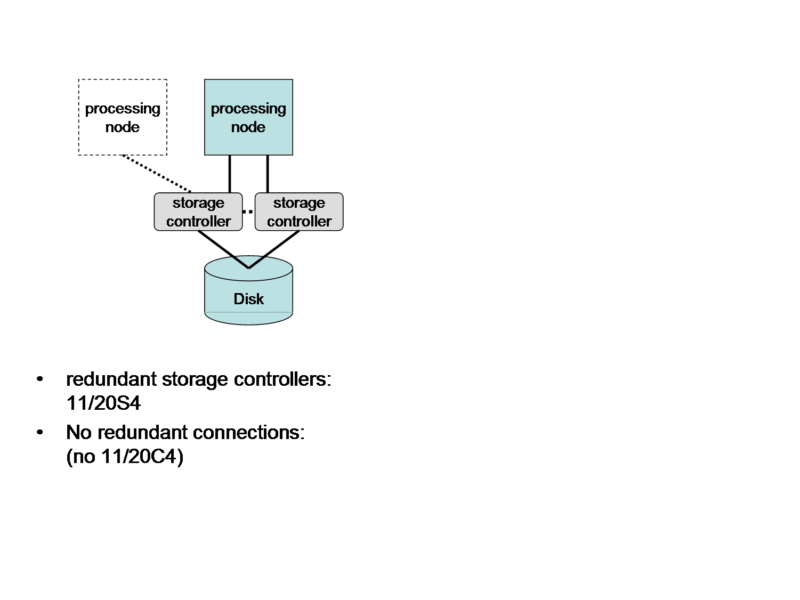
This place covers:
Communication controllers are nodes as defined under G06F 11/2007 dedicated to performing communication control logic.
This place covers:
Interconnections are physical media and are of point-to-point type or of bus type. Two interconnections are only considered redundant if:
- they both physically connect the same nodes, wherein nodes are any components performing processing or control functionality (examples: computers, bridges, storage controllers, communication switches, counter-example: physical repeater has neither processing nor control logic), and
- are configured to perform the same data transmissions.
Only documents fulfilling these criteria are classified here.
This group covers as well redundant dedicated interconnection media for I/O functionality as long as it does not use general purpose communication interconnection media (like LAN or USB cables).
This place covers:
E.g. multiple IBM channels between controller and disk
This place covers:
All cases where memory access, memory control or I/O control functionality is redundant. An example would be redundant configurations having an active and a passive graphics adapter.
Redundant dedicated interconnection media for such I/O functionality are to be classified in G06F 11/2002 as long as it does not use general purpose communication interconnection media (like LAN or USB cables).
This place covers:
All subject-matter where the redundancy resides in components that perform processing, i.e. components the runtime functionality of which is controlled by software (or firmware), except for ones dedicated to storage control or communication control (see the precedence rule).
For subject-matter to be classified in this group, it is enough that a fault masking is tried when a failure occurs. It is not necessary to have a guarantee that resources will be available to successfully fail over.
Two types of subgroups can be identified
- "architectural groups", i.e. groups that specify the actual redundancy arrangement (i.e. G06F 11/2035-G06F 11/2048)
- "functional groups", i.e. groups that define a particular functionality (i.e. G06F 11/2023, G06F 11/2051). This functionality is independent of the particular redundancy arrangement used.
This group has 4 types of subgroups. A class in each of the types should be given (as far as disclosed in the document) systematically. Thus, a document classified in these subgroups will normally have 3 or 4 symbols (invention or additional). The four types are :
- G06F 11/2023 and subgroups
This place covers:
Details of the failover mechanism
Also includes documents describing failback, i.e. reverting to the original or replacement primary processing unit when it becomes operational again. Currently this also covers documents dealing with the determination/selection of the spare to be used for replacing the failing component. There is failover taking place as soon as any functionality of a processing component is taken over by another processing component, whatever the functionality is.
This place covers:
Where a single component implements the control functionality for failover. This may be a distinct hardware module or software implemented on a single one of the redundant processing components.
This place covers:
Documents describing how to ensure that a failing and formerly active processing component no longer participates in the system functionality. Similarly, documents describing how to activate a former standby processing component to replace the functionality of a failing one. Example: setting bits identifying a node as active in a configuration file.
On the contrary, eliminating a backup unit that is not active (i.e. not within a failover process) is not G06F 11/20 since this is not error correction using redundancy in hardware. This is most likely G06F 11/0793.
"Eliminating a faulty processor" needs to be understood broadly. E.g. this includes as well :
- documents describing a complete reconfiguration of the system which results in eliminating not only the faulty processor, but also some functioning components if needed to come to a fault-free system and
- documents dealing with how to determine the fault-free system configuration which eliminates the minimum number of components.
This place covers:
Transferring runtime context of processes, tasks, jobs, threads etc... from a failing processing component to a replacing one.
This place covers:
The process of placing resources (other than the redundant processing components) under control of a replacement processing unit instead of a failing one. Example: attaching a RAID or other I/O device to the spare.
This place covers:
There are no processing components left inactive in failure-free operation.
This group contains all subject-matter where the performance is degraded after a failure has occurred, since the same processing needs to be done on less hardware.
However, performance degradation is not a necessary condition for this group, since a safety margin can be used in the failure-free operation.
"Hot spare" architectures wherein the spares are maintained updated for immediate failover by performing the same processing as the primary (possibly in clock synchronisation with the latter) do not fall in this group, because such spares are considered inactive to the extent they do not perform system functionality beyond what is necessary to function as spare. The same applies to architectures where spares are not completely idle because they monitor the primary to detect whether it is failing. These examples would rather be classified in G06F 11/2038 or G06F 11/2041.
This place covers:
The spare component can be spare for a single one or for a plurality of active processing components. There may be multiple spares which, however, are each a single spare for distinct sets of active processing components.
Also covers the case where the spare component is a hot spare.
Attention is drawn to the following places, which may be of interest for search:
Without idle spare hardware |
This place covers:
A processing component has more than one spare.
Also covers the case where at least one spare component is a hot spare.
Attention is drawn to the following places, which may be of interest for search:
Without idle spare hardware |
This place covers:
Examples: symmetric multiprocessor; multicomputer with virtual shared memory based on message passing.
This place covers:
Any architecture where redundant components have (at least temporarily) access to common storage independent of whether or not the shared storage is used for or during failover.
This place does not cover:
Where the redundant components share a common memory address space |
In this place, the following terms or expressions are used with the meaning indicated:
Storage | persistent memory subsystems (typically involving disks), the contents of which are not directly physically addressable as data words by a CPU |
This place covers:
All subject-matter related to mirroring.
Mirroring means that data replication is performed solely by the storage controller(s) or corresponding drivers without the involvement of higher software layers like file systems or databases. However, information provided by such higher layers within the blocks dealt with by the controllers (like sequence numbers or time stamps) may be used within the mirroring operation.
If a higher software layer is involved, this is not considered as mirroring but as backup (if point-in-time) or replication (if continuous) and should be classified in the appropriate places.
Mirroring implies, that the time at which a piece of data is transferred is determined solely by the mirroring functionality (disk controller, disk driver, ...). In contrast, for backup a trigger is necessary from another (typically higher level) software layer.
As a counter-example (i.e. which is not mirroring, but something in G06F 11/1402):
- periodic creation of snapshots and transfer of delta between successive snapshots to update a secondary storage.
Attention is drawn to the following places, which may be of interest for search:
Arrangements for replication or mirroring the data, e.g. data synchronisation between network nodes and/or user terminals |
This place covers:
Each of the more than 2 copies is a mirrored copy, the original (primary) data itself also being considered as one mirrored copy. An intermediate volume used as a buffer but not representing a full copy (suitable for failover) would not be considered a mirrored copy.
Subject-matter combining mirroring and backup should have double classification.
This place covers:
This covers distinct types of consistency problems like write order consistency, consistency between different volumes (broken links problem), consistency groups or writes.
This place covers:
Measures aiming at reducing the amount of data being transferred in the mirror system e.g. from the primary to the mirror site, or between the Host and the primary. Examples: "write coalescing", sending record logs instead of full blocks (journaling).
This place covers:
Systems in which updates occur independently on different mirror copies and are simultaneously propagated to the respective other mirror copies.
This place covers:
This covers resynchronisation of a failed or reconnected mirror as well as initial synchronisation to start mirroring.
Attention is drawn to the following places, which may be of interest for search:
For non-mirroring related disk initialisation |
Mirroring with multiple controllers does not imply that the controllers are redundant. If one of the storage controllers would be faulty in such a system, either the host will not be able to access the storage anymore or the mirroring functionality will be lost. Thus some storage control functionality will be lost and there is no redundancy on this level.
This place covers:
This group contains the details about how the faulty storage control element is taken out of operation or how storage control functionality is transferred to other elements.
Examples are :
- changing the system configuration
- shut down of the controller concerned
Counter-example:
Eliminating a backup unit that is not active (i.e. not within a failover process) is not G06F 11/20 since this is not error correction using redundancy in hardware. This is most likely G06F 11/0793.
This place covers:
Architectures and problems involving the use of additional storage (space) intended to be used instead of failing storage (space). Typical problems involve eliminating a failing active storage unit or activating spares (possibly storing replicated data).
Also to be used when it is not clear whether an eliminated disk has its data replicated elsewhere.
In the case of failing over, this group does not cover the data initialisation of an activated spare, because this is G06F 11/1662.
Note that because of the precedence rule failover in the context of mirroring is not dealt with in this group (see G06F 11/2069).
This place covers:
This group contains details of the measures that are taken to keep the data in memory, and/or persistent storage of a spare/stand-by unit (processor or controller) current in order to be ready for take-over. This is a repetitive process (frequently involving data replication) used before the occurrence of the fault.
This group does not contain details of how a component's data is initially made ready to function as backup (this belongs to G06F 11/1658+).
Examples for the use of this group:
- replaying message log on standby node: transmission of log (before failure) is G06F 11/2097, replaying of log is failover (G06F 11/2023) if performed after the failure.
- very hot standby using running standby in lockstep without comparison. The lockstep aspect is to be classified in G06F 11/1675 (Indexing Code or EC according to importance). However, since it addresses the problem of maintaining the standby unit updated G06F 11/2097 (possibly Indexing Code) should be given.
Example: Two redundant disk controllers control a single disk. Host write requests received by one controller are transferred to the second one (including the data) for temporary buffering until the write is performed by the first one. Should the first one crash, the second one is able to perform incomplete writes. Hence, the second one is maintained updated by the first one for potential failover.
A symbol to indicate the type of redundancy in Hardware (e.g. G06F 11/2038) must be added as additional, when the type of redundancy is not otherwise classified.
This place covers:
This group and its subgroups also cover testing at system level, i.e. testing of a combination of hardware and software.
This testing occurs at a time outside of "normal operating mode", e.g. during standby, idle time or at power on.
Next to the testing per se, this group and its subgroups also cover the equipment which is used to test the hardware concerned or to interpret the test results.
Subject-matter is classified here if programmable processing logic is part of the device under test. Else, the subject-matter belongs to G01R 31/317.
Attention is drawn to the following places, which may be of interest for search:
Testing of Software | |
Verification of a hardware design | |
Testing of digital circuits, e.g. of separate computer components | |
Testing of computer memories |
General rules for G06F 11/22 and subgroups
In G06F 11/22 and subgroups, generally only 1 symbol is allocated. The symbol allocated is the most relevant one for the invention information disclosed.
Only if the component being tested and the test itself are important, should the subject-matter be classified in one of the subgroups G06F 11/2205 together with another group in G06F 11/22.
Only invention information is classified.
If the software testing part is described and is important, the document should also be sent to G06F 11/3668 for classification.
Rules specific to G06F 11/22 per se:
Documents are only classified in G06F 11/22 per se if it can not be established whether the test is marginal checking (classified in G06F 11/24), testing of logical operation (classified in G06F 11/25) or functional testing (classified in G06F 11/26).
In this place, the following terms or expressions are used with the meaning indicated:
Computer hardware | a digital circuit which has programmable processing logic incorporated. |
Testing | an execution of the computer hardware which is dedicated to the detection of faults. Thus, the execution of the hardware during the test is not part of the "useful"processing which contributes to achievement of the intended purpose |
Group no longer used for classification. See G06F 11/2289 instead.
This place covers:
Subject-matter where the testing process or test analysis process is guided by a fault dictionary. This is the case when a lookup (based on the test results) is done directly from a list of entries, without any additional processing.
Although 90% of the documents use the fault dictionary to determine where the fault is located or what actions to take; the group also covers subject-matter where information is looked up in the fault dictionary to determine the next test.
This place covers:
Subject-matter where an error message is correlated with other error messages or parameters.
Although 90% of the documents use expert systems to determine where the fault is located or what actions to take; the group also covers subject-matter where the expert system is used to determine the next test.
In this place, the following terms or expressions are used with the meaning indicated:
Expert system | A computer program that contains a knowledge base and a set of algorithms or rules that infer new facts from knowledge and from incoming data. |
This place covers:
Although 90% of the documents use the neural network to determine where the fault is located or what actions to take; the group also covers subject-matter where the neural network is used to determine the next test.
This place covers:
Subject-matter where the focus is on how the test is done instead of on what test is done or what is tested.
In general, the documents classified in this subgroup are of a more theoretical nature.
This place covers:
Subject-matter describing what tests are being done on power on. The tests concern the correct functioning of the system as a whole.
Documents describing the execution of tests are classified in G06F 11/26 and subgroups.
Attention is drawn to the following places, which may be of interest for search:
Detection of the configuration of a system |
This place covers:
All testing where the level of the logical value (e.g. 0 or 1) of the signal is tested, independent of functionality.
Attention is drawn to the following places, which may be of interest for search:
Debugging using additional hardware |
This place covers:
Subject-matter concerning the generation of test inputs, where this generation is done externally to the system being tested. It covers as well arrangements where both test input generation and test result processing are done externally to the system being tested.
This place covers:
All adaptations to the hardware being tested to make the hardware more testable.
This place covers:
Those tests which are incorporated in the hardware component itself which is being tested.
This place does not cover:
G06F 11/263 takes precedence.
Group no longer used for classification.
This place covers:
Checking the correct order of processing. the word "order" implies the consideration of a sequence. It can be for example the sequence of instructions in a computer program, the sequence of steps to perform when installing a software on a computer, etc. Typically documents dealing with the verification of a system that is specified in terms of state machine (states and transitions between states) based on reachability analysis can be found in the group. Also documents dealing with the verification that a computer program is executing according to the expected sequence of instructions (i.e. there is no unexpected jump that could be the result of a malicious attack) can be found in the group. This can be done for example by computing a current signature while the program is executing and comparing it to a reference signature.
This place does not cover:
Checking the correct execution order of instructions for security purposes | |
Monitoring patterns of pulse trains |
In this place, the following terms or expressions are used with the meaning indicated:
FSM, FSA | A finite state machine (FSM) or finite state automata (FSA) is a mathematical abstraction sometimes used to design digital logic or computer programs. It is a behaviour model composed of states and transitions between the states. |
Signature | A signature is a value resulting from the application of a function to some computer data, for example a hash function. |
In patent documents, the following words/expressions are often used as synonyms:
- "sequence", "FSM (Finite State Machine)" or "FSA (Finite State Automata)"
This place covers:
Monitoring refers to an extra functionality for observing properties of a running computing system in its normal operating conditions without inputting test data.
Attention is drawn to the following places, which may be of interest for search:
Thermal management in cooling means | |
Power management | |
Monitoring for error detection | |
Verification or detection of system hardware configuration | |
Monitoring intrusion in a computer system | |
Monitoring of control systems | |
Network monitoring | |
Network security. Monitoring network traffic | |
Monitoring testing in wireless networks |
The classification process in the G06F 11/30 and its subgroups has to be carried out performing the following steps:
- 1. If the document contains interesting aspects about the observation of properties of a running computing system over time in its normal operating conditions without inputting test data, then proceed with ALL of the following steps 2, 3, 4.1, 4.2, 4.3, 4.3.1, 4.4, 4.5 and 5 in sequence, otherwise stop because the document is not to be understood to be about monitoring;
- 2. If the document contains interesting aspects about the (visual or acoustical) display of the monitored data, then classify the document in G06F 11/32 and its subgroups;
- 3. If the document contains interesting aspects about the monitoring of computer activity, then classify the document according to the FCRs of G06F 11/34 and subgroups;
- 4.1. If the document contains interesting aspects about monitoring the configuration of the computing system, then classify the document in G06F 11/3051;
- 4.2. If the document contains interesting aspects about monitoring the status of the computing system, then classify the document in G06F 11/3055;
- 4.3. If the document contains interesting aspects about the monitoring of environmental parameters of the computing system, then classify the document in G06F 11/3058 and subgroups;
- 4.3.1. If power consumption is evaluated through the monitoring of computer activity, then also classify the document in G06F 11/34 and subgroups according to the FCRs of G06F 11/34;
- 4.4. If the document contains interesting aspects about the reporting of the monitored data, then classify the document in G06F 11/3065 and its subgroups;
- 4.5. If the document contains interesting aspects about the sensing of the monitored data, then classify the document in G06F 11/3089 and its subgroups;
- 4.6. If the document has been classified at least once in G06F 11/3051, G06F 11/3055, G06F 11/3058, G06F 11/3065, G06F 11/3089 or their subgroups, then classify the document in G06F 11/3003 and its subgroups;
- 5. If none of the steps 2-4.6 apply, then classify the document in G06F 11/30.
In this place, the following terms or expressions are used with the meaning indicated:
Computer activity | For this group and its subgroups, computer activity covers the activities performed by the computer system that involve data (e.g. processing, data storage, data transfer). It also includes user activity. |
Monitoring system | A monitoring system is generally considered to be composed of observing or measuring entities (usually called monitors or observers) and interfaces/probes which link them to the system under observation. |
Interfaces/probes | The interfaces/probes sense (or access) data relative to the system under observation and report them to the observing/measuring entities. |
Probe effect | The probe effect is the undesired alteration of a system property caused by the fact that this property is being observed or measured. |
Environmental parameters | Environmental parameters of a computing system are: power, currents, temperature, humidity, position, radiation, etc. |
This place does not cover:
Drivers for digital recording or reproducing units | |
Circuits for error detection or correction within digital recording or reproducing units | |
For distributed storage of data in networks, e.g. transport arrangements for network file system [NFS], storage area networks [SAN] or network attached storage [NAS] |
This place covers:
For this group and its subgroups, computer activity covers the activities performed by the computer system that involve data (e.g. processing, data storage, data transfer). It also includes user activity.
This group also includes the modeling of the system or its behaviour, or simulating the execution of the system for observing its properties on a theoretical level.
As criterion to decide whether G06F 11/34 and subgroups applies, it needs to be considered whether computer activity or user activity is being monitored or not.
If the monitoring is done purely to detect when an error occurs, G06F 11/0703 and subgroups apply instead of G06F 11/34 and subgroups.
Recording data during software testing or debugging is classified in G06F 11/36 and subgroups.
The subgroups of G06F 11/34 fall apart in 2 blocks :
- G06F 11/3404 - G06F 11/3442 and subgroups deal with what is being monitored.
- G06F 11/3447 - G06F 11/3466 and subgroups deal with how the monitoring is done.
If both aspects are relevant, classes should be given in both ranges. E.g. performance measurement (G06F 11/3409 or subgroups) where a particular monitoring hardware is used to perform the measurement (G06F 11/3466 or subgroups) is classified in both ranges.
Documents where the monitoring relates to the monitoring of user actions must be systematically classified in G06F 11/3438 (as invention or additional information), independent of any other classification.
Following Indexing Codes must be systematically given for documents classified in G06F 11/34 and subgroups :
- G06F 2201/80 if the monitoring is specific to databases
- G06F 2201/81 if a threshold influences the monitoring behaviour
- G06F 2201/815 if the monitoring concerns the effects of virtualisation
- G06F 2201/86 for all event-based monitoring
- G06F 2201/865 if software is being monitored
- G06F 2201/87 if the monitored object is a transaction
- G06F 2201/875 if the monitored system includes the internet
- G06F 2201/88 if counts are used
- G06F 2201/885 if the monitored object includes a cache
If the document does not describe what is being monitored, its subject-matter should not be classified in G06F 11/34, but in G06F 11/30 or other subgroups of G06F 11/30.
In this place, the following terms or expressions are used with the meaning indicated:
Monitoring | Extra functionality for observing properties of a running computing system over time in its normal operating conditions without inputting test data |
This place covers:
The subject-matter of this group covers monitoring of parallel or distributed programming. Typical issues addressed are : determining the degree of parallelism, optimizing the degree of parallellism, performance of distribution algorithms.
This place covers:
monitoring the performance of the computer system or its components.
This group covers not only the monitoring of time, but usage of any (physical or other) resource as well.
This group applies whatever the component (e.g. disk, processor, scheduler,...) of which the performance is being monitored is.
Attention is drawn to the following places, which may be of interest for search:
Monitoring of user actions |
This place covers:
Only the monitoring activities to determine the load of a computer system or the distribution of the load on the different components of the computer system. However it does not cover any actions that are performed in response to the determined load.
Attention is drawn to the following places, which may be of interest for search:
Adapting or redistributing the load in a computer system | |
Adapting or planning the capacity required | |
Redistributing the load in a network by a load balancer |
If time measurement is used to be able to determine the load, documents should be classified as well in G06F 11/3419.
This place covers:
all documents where actions of the user are monitored (e.g. for productivity or allocation of billable employee time).
This includes arrangements to evaluate the usability of a system or component.
This place does not cover:
Tracking the activity of the user |
In this place, the following terms or expressions are used with the meaning indicated:
Usability | Measure of the ease of use of a specific object or set of objects or of how easy the object or set of objects is to learn to use |
This place covers:
This group covers all subject-matter where monitoring is done to come to conclusions about the capacity required. It is necessary that this goal is explicit in the document.
Capacity should be understood here as relating to how much computer resources are needed. In general these are hardware resources (such as the amount of processing power, memory or storage space). However this can also be software resources emulating such hardware (such as an amount of virtual memory, a number of virtual machines, etc.).
In contrast to G06F 11/3433, here the load is taken as a given and the goal is to come to conclusions about the resources that need to be available. The actions taken in response will change the configuration of the system.
The actions per se performed to adapt the capacity are not classified here, but rather in G06F 9/00.
In this place, the following terms or expressions are used with the meaning indicated:
Measures to allocate resources |
This place covers:
This group deals with subject-matter where a model of the system to be monitored (or part of it) is made or modified. This group does not cover the use of the model as monitoring tool (which should be classified according to what is being monitored).
E.g. :
- This group covers the construction of a model to determine monitoring points in the system. However, it does not cover a concrete implementation of the monitoring points (which would be in G06F 11/3466).
- This group covers the construction of a model to be used in a simulation. However, the use of the model in a simulation is not covered (this would be in G06F 11/3457).
In this place, the following terms or expressions are used with the meaning indicated:
Model | description of a system using mathematical concepts and language. It may help to explain a system and to study the effects of different components or parameters, and to make predictions about system behaviour |
This place covers:
Performance evaluation by statistical analysis means that statistics are used to come to a conclusion regarding a system parameter. This may be to evaluate system parameters or predict the future behaviour of the system.
It covers as well subject-matter where a relation between different parameter is modelled, based on measured values documenting the relationship (e.g. curve-fitting)
Typically, this would involve multiple executions or the analysis of time series observed.
Attention is drawn to the following places, which may be of interest for search:
Stochastic model development of the system for monitoring |
This place covers:
Simulation means that execution characteristics of the system or component to be monitored are observed without actually executing the real system or without executing the system or component under real conditions.
Examples are:
- Monitoring the execution of the real system but with a fictive workload
- Applying a real workload to a model or a mockup of the system
This place covers:
The title of this groups should be read as "by tracing". This group and its subgroups are also relevant if the tracing is not explicitly done to evaluate the performance (for instance if no specific purpose is stated for the tracing).
This group covers arrangements that describe how monitored data of the physical system is being collected or made available. These arrangements can be internal in the system (i.e. tracing) or external to the system (general monitoring arrangements used for monitoring computer activity).
Tracing for software testing or debugging purposes is classified in G06F 11/36 and subgroups.
In this place, the following terms or expressions are used with the meaning indicated:
Tracing | Observing or making available monitored data using additional hardware or software functionality in the monitored system or component |
This place covers:
Examples are:
- Observing the addresses circulating on a computer bus
- Monitoring memory accesses for certain address ranges
This place covers:
The scope of this group is not restricted to logging of monitoring data per se. It covers as well the determination of what monitoring data should be logged and how it should be logged (e.g. condensing the logged data, logging statistics, ...) and analysis of logged monitoring data.
Documents describing the monitoring of channels should additionally be classified in G06F 11/349.
In this place, the following terms or expressions are used with the meaning indicated:
Channel | An independent hardware component that coordinates all I/O to a set of controllers or devices |
Documents describing the monitoring of channels should additionally be classified in G06F 11/3485.
In this place, the following terms or expressions are used with the meaning indicated:
Channel | An independent hardware component that coordinates all I/O to a set of controllers or devices |
This place covers:
Applies when communication or interaction between the processing components influences the assessed properties of the whole system.
Thus, it is a necessary condition to have a communication medium involved, however not a sufficient condition. If the system which is observed is limited to the communicaiton medium, it should not be classified here (but in H04L if the medium is a network or in G06F 11/349 if the medium is a bus).
Examples are:
- Monitoring arrangements for distributed systems
- Arrangements for application level response time measurement of web servers
- Monitoring arrangements in a multiprocessor system
If the communication protocol or the hardware characteristics of the network are relevant for the monitoring, this should be (additionally) classified in H04L.
This place covers:
Evaluating a program's functionality to find and fix bugs or abnormalities with the intent to check the program against its specifications and identify any inconsistencies using a variety of techniques, such as unit testing, integration testing and system testing.
Tools frequently used to identify the source of problems and ensure the software functions as intended are as follows (non-exhaustive):
- debuggers;
- profilers; and
- log analysers.
Tracing for performing performance analysis; G06F 11/3466
Emulators and simulators used for testing computer hardware; G06F 11/261
User interface programs; G06F 9/451
Generating or modifying source code; G06F 8/30
CASE, software engineering tools; G06F 8/30
Compiling; G06F 8/41
Concurrent instruction execution; G06F 9/38
Attention is drawn to the following places, which may be of interest for search:
Arrangements for software engineering | |
Program code verification | |
Fault-tolerant software | |
Detection or location of defective computer hardware by testing during standby operation or during idle time | |
Checking correct execution order of instructions | |
Recording or statistical evaluation of computer activity | |
Security arrangements for protecting computers, components thereof, programs or data against unauthorised activity | |
Computer aided design |
In this place, the following terms or expressions are used with the meaning indicated:
bug | a bug in a program results from a faulty implementation and produces an incorrect or unexpected result or causes the program to behave in unintended ways. |
software analysis | software analysis aims at verifying that a program or its specification satisfies certain properties without involving testing (no test inputs are provided to the program under analysis). It can involve for example scanning the source code and analysing the dependencies between the various components, or the use of certain variables, etc. It can consist in the use of formal methods, like model checking or theorem proving which aim at formally guaranteeing certain properties, for example that the program is well-typed, or deadlock free etc. In principle software analysis does not require the program to execute (static analysis), but in some cases it does, for example to verify runtime properties. |
software testing | software testing is the process of executing a program, or a discrete program unit, with the intent of finding errors. Tests can only reveal the presence of errors, but cannot ensure the absence of errors. When errors are detected in a program, one might want to start debugging it, i.e. locating precisely the error and correcting it. In both cases (testing and debugging), the program is executed. |
software debugging | software debugging refers to the activity of locating an error. |
This place covers:
Analysis of software, i.e. verifying that a program or its specification satisfies certain properties without involving testing, i.e. no test inputs are provided to the program under analysis. For example, it may involve scanning the source code and analysing the dependencies between the various components, or the use of certain variables. It may involve the use of formal methods, like model checking or theorem proving which aim to formally guarantee certain properties, for example that the program is well-typed or deadlock free. In principle, analysis of software does not require the program to be executed (static analysis), but in some cases the program is executed, for example, to verify runtime properties (dynamic analysis).
This place does not cover:
Testing of software |
This place covers:
Mathematically-based techniques (model checking, abstract interpretation, formal proof) for the verification of a program.
This place covers:
Analysing runtime behaviour to detect errors (e.g. performance bug or infinite loops).
This place covers:
A software metric is a measure of some property of a piece of software or its specifications, e.g. number of lines in the code, cyclomatic complexity (number of linearly independent paths through a program's source code), or any measure which aims at evaluating the properties of a program.
This place does not cover:
Software metrics used during software generation |
This place covers:
The activity of identifying, evaluating and fixing bugs that are found during runtime execution or testing.
This place covers:
Manual or compiler assisted instrumentation or by any automatic tool of the source code according to an instrumentation policy.
This place covers:
Usually the debugging process is performed on an un-optimised version of a program, and the program is optimised (by the compiler) when fully debugged. However, in some cases one wants to debug the optimised version of a program: for example, some bugs might occur in the optimised version of the code only. An obvious problem that an optimised code will create is when a developer sets a breakpoint in a part of code that has been eliminated by the compiler during optimisation.
This place covers:
- Methods and arrangements for dealing with the synchronisation issues involved with debugging operations (e.g. when inserting a breakpoint in a multithreaded or distributed program).
- Method and arrangements for investigating synchronisation problems in distributed or multithreaded programs.
This place covers:
Methods and arrangements for generating or analysing traces of a program execution.
This place covers:
Methods and arrangements for gathering or analysing data exchanged on a computer bus (e.g. data bus, memory bus) during the execution of a program.
This place covers:
- Instrumenting operations performed on a compiled program directly before execution (e.g. Valgrind).
- Runtime injection: the code is modified at runtime.
This place does not cover:
Instrumention of Bytecodes |
This place covers:
Hardware arrangements contributing to the debugging process
This place covers:
The term "In-Circuit Emulator" in this group only refers to a device replacing the target microprocessor. The code under debug is not executed on the real target processor but rather on a specific hardware that emulates the target processor and that comprises debug facilities for setting breakpoints or watchpoints.
Nowadays, the term "In-Circuit Emulator" refers also to a JTAG or BDM based device which provides access to the internal registers of the target microprocessor. Said device can take control of the target microprocessor, start, stop or resume the code execution. The code under debug is executed on the real target microprocessor, in that case. If the technical contribution of a document refers to such a JTAG/BDM based device, this document should be classified in G06F 11/3656 group (Debug interfaces).
This place covers:
Aspects related to communication between a host and a target (e.g. JTAG/BDM based "In-Circuit Emulator").
In this place, the following terms or expressions are used with the meaning indicated:
JTAG | Joint Test Action Group (JTAG) is the common name for what was later standardized as the IEEE 1149.1 Standard Test Access Port and Boundary-Scan Architecture. JTAG refers nowadays to a bus for transferring debug commands from a host to a target and debug data from the target to the host. |
BDM | Background Debug Mode (BDM) interface is an electronic interface that allows debugging of embedded systems. BDM interface allows a Host to manage and query a target. |
This place covers:
Subject matter related to software bugs after the software development phase. For example, a system crash during operation might be caused by a software bug. The system is diagnosed after the crash (or the failure) to find out where the bug was.
This place does not cover:
Error or fault processing not based on redundancy, i.e. by taking additional measures to deal with the error or fault not making use of redundancy in operation, in hardware or in data representation |
This place covers:
The process of executing a program or a discrete program unit, using test inputs with the intent of finding errors.
Attention is drawn to the following places, which may be of interest for search:
Detection or location of defective computer hardware by testing during standby operation or during idle time | |
Software testing in telephone exchanges |
This place covers:
The different activities of software testing:
- test case/script/scenario design (G06F 11/3684)
- test coverage analysis (G06F 11/3676)
- execution of the test cases/scripts/scenarii (G06F 11/3688)
- analysis of the test results (G06F 11/3692)
- maintenance and updates of the test cases/scripts/scenarii in parallel to the software evolution during software development (G06F 11/368)
The document should be classified according to the most relevant information concerning one activity of the software testing.
- if it is possible to identify one relevant piece of information related to one of the identified software testing activities, the document should be in classified in one of the corresponding subgroups:G06F 11/3676, G06F 11/368, G06F 11/3684, G06F 11/3688, G06F 11/3692.
- If it is not possible to extract any relevant information concerning any of the identified software testing activities, the document should be classified in the test management subgroup (G06F 11/3672)
This place covers:
Coverage analysis is concerned with the degree to which test cases exercise or cover the logic of the program. Because testing is a time consuming activity that cannot be exhaustive, the key issue is to apply a subset of all possible test cases which has the highest probability of detecting errors. Coverage analysis is therefore an issue at the design stage (strategy for generating test inputs that are effective in terms of coverage) as well as at the execution stage (how to measure coverage).
Test coverage can refer to different aspects:
- path coverage
- data coverage
- line coverage
This place covers:
Maintenance and updates of test scripts in parallel to the evolution of the software during software development.
This place does not cover:
Version control; configuration management for creation of software |
This place covers:
Generation or updates of test cases, scenarios, scripts. Specific languages for writing tests.
This place covers:
Scheduling of the tests; recording of test results; regression testing; mutation testing.
This place covers:
Comparing the results of the tests with an oracle (assertions, mathematical models, simulations and the like).
This place covers:
Arrangements for facilitating the testing of a software unit:
- Arrangement can be an interface to provide test inputs.
- Arrangement for simulating missing part of software or hardware that are necessary for performing the execution and the testing of the software unit.
- Arrangement for performing a time compression in order to simulate a long term execution of a software program in a short time frame
- Arrangement for performing the test execution on a different platform
This place covers:
Environments, frameworks, graphical user interfaces [GUI] or simulators that aim at supporting or facilitating the task of a user during the various phases of analysing, testing or debugging of software, e.g. to navigate into the code, to add or remove breakpoints, to visualise execution traces or to edit/maintain/archive test suites.
The environment may be comparable to a software development environment [SDE], but it contains features that are specific to the phases of analysing, testing or debugging of software.
This place does not cover:
Accessing, addressing or allocation of record carriers, e.g. disk storage |
Attention is drawn to the following places, which may be of interest for search:
Any classification rules applicable to a specific group also apply to any sub-groups thereof unless overruled by more specific rules.
When one or more sub-group definitions are listed in the definition statement of a group no further description of these sub-groups are provided in this FCR.
The group G06F 12/00 contains no material and should not be used for classification.
Use of Indexing Codes:
All groups have corresponding G06F 12/00 Indexing Code-codes, which should be used for secondary aspects (non-invention information).
Indexing Scheme G06F 2212/00:
In November 2011 a new indexing scheme relating to G06F 12/00 has been introduced. The Indexing Codes from the range G06F 2212/20- G06F 2212/7211 are mandatory when applicable. The code range G06F 2212/10- G06F 2212/178 is not mandatory but should preferably be used for documents characterized by specific technical effects or applications.
Warning: The G06F 2212/00 indexing scheme is new and has not yet been systematically applied to the existing documentation except when explicitly indicated in this document.
This place does not cover:
G06F 12/02 should be used only for material not provided for in any of the sub-groups.
This place covers:
Addressing or accessing memory in two or more dimensions, e.g. for transposing of data.
Addressing of rectangular blocks of data.
This place covers:
Page mode addressing of DRAM.
Speculative addressing of a memory in general.
This place does not cover:
Prefetching to cache memory or use of dedicated prefetch buffers |
Attention is drawn to the following places, which may be of interest for search:
Memory controllers |
This place does not cover:
Module addressing |
Attention is drawn to the following places, which may be of interest for search:
Resource allocation |
This place covers:
Dynamic memory allocation.
Explicit memory de-allocation.
Free space management.
This place covers:
Memory management in non-volatile memory that is not specific to flash memory, e.g. in emerging memory types such as resistive RAM or ferroelectric memory.
This place covers:
Addressing of flash memory, e.g. logical to physical address mapping;
Allocation within flash memory;
Management, e.g. cleaning, compacting, erasing, wear levelling;
Temporary storage of data, e.g. within volatile buffers or in buffer blocks.
Attention is drawn to the following places, which may be of interest for search:
Details of block management in an interface arrangement to a storage system | |
Details of file management in an interface arrangement to a storage system | |
Details of the controller in an interface arrangement to a storage system making use of vertical data movement | |
Details of the protocol conversion in an interface arrangement to a storage system making use of vertical data movement | |
Interface arrangements for single solid-state devices | |
Interface arrangements for hybrid storage devices, e.g. magnetic and semiconductor mediums sharing the same controller | |
Interface arrangements for storage system comprising multiple controllers and multiple storage medium types, e.g. SSD, HDD and tapes combined | |
Interface arrangements for storage system comprising multiple controllers and multiple semiconductor storage devices, e.g. Hybrid storage array | |
Write caching | |
Non-volatile memories |
Indexing Codes G06F 2212/7201- G06F 2212/7211 are used in this group. The coding of the existing documentation is mostly complete.
In this place, the following terms or expressions are used with the meaning indicated:
Page | The smallest data unit of read or write access in a NAND flash memory. |
This place covers:
Automatic reclamation of heap-allocated memory after last use by a program, i.e. where the allocated memory is not explicitly freed by the program.
This place does not cover:
Explicit freeing of memory | |
Compaction and cleaning within flash memory |
The Indexing Code G06F 2212/702 should be used for conservative garbage collection. The coding of the existing documentation is mostly complete.
This place covers:
Multi-user or multiprocessor address space allocation.
Mapping arrangements therefore, e.g. local to global address space mapping.
Attention is drawn to the following places, which may be of interest for search:
Virtual address translation | |
Interprocessor communication |
This place does not cover:
Free address space management | |
Multiple user address space allocation | |
Virtual memory address translation. |
This place covers:
Addressing variable length words.
Addressing parts of a word, e.g. bit fields.
Addressing unaligned words.
This place does not cover:
Address generation within processors |
Attention is drawn to the following places, which may be of interest for search:
Information transfer on a bus |
This place covers:
Addressing or allocation of physical memory modules or banks.
Module selection, e.g. using chip selects.
This place does not cover:
Addressing or allocation within a memory module. | |
Hierarchical memory arrangements |
Attention is drawn to the following places, which may be of interest for search:
Memory controller. | |
Bank or array addressing within individual memory devices. |
This place covers:
Hierarchical memory systems.
Virtual memory.
Paging.
Attention is drawn to the following places, which may be of interest for search:
Hierarchically organised storage systems | |
Virtual address translation | |
Replacement control |
This place covers:
Cache memories being part of a memory hierarchy. Information not provided for in the sub-groups is classified in this group, e.g. aspects relating to cache configuration, error handling or testing.
Attention is drawn to the following places, which may be of interest for search:
Register cache (for register file). | |
Branch history / target cache. | |
Caching of dynamically generated content, e.g. database query cache, web cache. |
Indexing Code groups G06F 2212/27, G06F 2212/30, G06F 2212/45, G06F 2212/60 are mandatory in this group when applicable.
This place covers:
Write-back of dirty data to main memory.
Saving or preservation of dirty data in case of errors or power failure
Write-back policies, e.g. selective write-through / write-back.
This place does not cover:
Multiuser, multiprocessor, multiprocessing cache systems e.g. write-back due to coherency protocol transactions. |
Attention is drawn to the following places, which may be of interest for search:
Data backup to prevent data loss. | |
Replacement policies |
Indexing Codes G06F 2212/62 are mandatory in this group.
This place covers:
Cache coherency protocols, e.g. snooping, directory based or software controlled.Further details of subgroups
G06F 12/0833: this group is not used for classification of new material, use G06F 12/0831.
Attention is drawn to the following places, which may be of interest for search:
The group G06F 12/0815 should only be used for material not provided for in any of the subgroups G06F 12/0817-G06F 12/0837.
This place covers:
Simultaneous processing of two or more accesses.
Attention is drawn to the following places, which may be of interest for search:
Pipeline techniques within processors | |
Module addressing in general |
This place covers:
Prefetching in cache memory using fixed or adaptive prefetch strategies.
Software controlled prefetching using prefetch instructions.
Use of dedicated prefetch buffer or prefetch cache.
Attention is drawn to the following places, which may be of interest for search:
Compiling techniques to reduce cache misses | |
Instruction or operand prefetching within processors |
For prefetching in disk caches this class should be combined with Indexing Code G06F 12/0866.
Indexing Code group G06F 2212/602 is mandatory in this group. The coding of the existing documentation is mostly complete.
Attention is drawn to the following places, which may be of interest for search:
Page mode accessing of cache |
Indexing Code G06F 2212/6032 is mandatory for material dealing with way prediction. The coding of the existing documentation is mostly complete.
This place covers:
Dedicated cache memory within storage controller or storage device;
Caching of network attached storage or remote server content;
Disk caching in main memory of host computer, e.g. by operating system.
Attention is drawn to the following places, which may be of interest for search:
Storage adapters, disk storage management | |
Data buffering arrangements for data transfers within storage systems | |
Caching of dynamically generated data content, e.g. web caching, database query results | |
Temporary data storage in networks |
Indexing Code groups G06F 2212/21, G06F 2212/22, G06F 2212/26, G06F 2212/28, G06F 2212/31 and G06F 2212/46 are mandatory in this group.
If the invention information can be fully classified in other group(s) it is recommended to add only Indexing Code G06F 12/0866.
This place covers:
Data transfer control within the cache system, between the cache and the storage devices or between the cache and the host system.
E.g. concurrent transfers, internal buffering arrangements, pipelining.
Attention is drawn to the following places, which may be of interest for search:
Write back control | |
Replacement control |
This place covers:
Allocation of cache space.
Organisation of cache data, data structures therefore.
Free space management within cache.
Attention is drawn to the following places, which may be of interest for search:
Replacement control |
This place covers:
Selective allocation of (parts of) cache memory space to specific storage devices or parts of such devices.
This group is limited to large granularity mapping of cache areas to portions of a storage system, e.g. allocating cache partitions to individual storage devices.
Attention is drawn to the following places, which may be of interest for search:
Set-associative or similar mappings of individual cache entries to storage device locations. |
This place covers:
Cache memories adapted for particular applications or specific types of data, e.g. stack caches, instruction caches, caches for graphics information.
Attention is drawn to the following places, which may be of interest for search:
Branch history cache, branch target cache |
Indexing Code group G06F 2212/45 is used in this group.
Warning: Except for G06F 2212/451 these codes have not yet been allocated to the existing documentation.
This place covers:
Special access modes to cache memory, e.g. burst mode access, partial line accessing.
This place covers:
Selective or conditional caching of data, e.g. based on expected usefulness of caching;
Bypassing of cache.
This place covers:
Invalidation of the entire cache memory content or parts of the cache memory content, e.g. upon initialization or task switching;
Hardware techniques for cache memory invalidation.
Attention is drawn to the following places, which may be of interest for search:
Main memory updating, e.g. flushing of cache content | |
Invalidation forming part of a cache coherency protocol | |
Initialisation circuits for static stores |
This place covers:
Cache topology;
Cache structurally integrated within a memory device, e.g. DRAM row cache;
Cache employing DRAM or other technology than SRAM.
Attention is drawn to the following places, which may be of interest for search:
Static stores in general |
Indexing Code G06F 2212/305 is mandatory for memory with integrated cache memory, e.g. cache DRAM. The coding of the existing documentation is mostly complete.
Indexing Code groups G06F 2212/22 and G06F 2212/27 are used in this group.
This place covers:
Virtual to physical address translation;
Translation fault handling;
Virtual address space management, see provisionally also G06F 12/0284.
Attention is drawn to the following places, which may be of interest for search:
Virtual machines. | |
Logical partitioning | |
Address mapping within flash memory | |
Multi-user or multiprocessor address space allocation | |
Address mapping or translation in general, not specific to virtual memory |
Indexing Codes G06F 2212/65- G06F 2212/657 are used in this group. The coding of the existing documentation is mostly complete.
In this place, the following terms or expressions are used with the meaning indicated:
Page | The unit of paging in virtual memory |
This place covers:
Caching of address translations;
TLB miss handling.
Indexing Code group G06F 2212/681-G06F 2212/684 is used in this group. The coding of the existing documentation is mostly complete.
Replacement control for TLB's is classified in G06F 12/12-G06F 12/128. An Indexing Code G06F 12/1027 should be allocated in such cases.
In patent documents, the following abbreviations are often used:
TLB | Translation Look-aside Buffer |
MMU | Memory Management Unit |
This place covers:
Address translation for peripheral devices, channels, I/O adapters, network adapters, DMA controllers etc.
Memory management units within such devices or interfaces.
This place covers:
Translation for multiple virtual address spaces, e.g. identified by an address space identifier;
Segmentation based on a segment identifier;
Guest address space to host address space translation.
Indexing Codes G06F 2212/656 and G06F 2212/657 are particularly relevant in this group.
This place covers:
Replacement control in virtual memory, cache memory or TLB.
Replacement algorithms.
Attention is drawn to the following places, which may be of interest for search:
Write back control in cache |
In patent documents, the following abbreviations are often used:
LFU | Least Frequently Used |
LRU | Least Recently Used |
MRU | Most Recently Used |
FIFO | First In First Out |
This place covers:
Preventing unauthorized access to memory content.
Virtual memory access control.
Attention is drawn to the following places, which may be of interest for search:
Multiprogramming arrangements | |
Program synchronization, e.g. using locks; mutual exclusion | |
Security arrangements in computers | |
Coded identity card or credit card | |
Secure communication |
This place covers:
Address scrambling;
Data encryption within a memory, e.g. being dependent on the memory location.
This place does not cover:
Data encryption being independent of the memory location |
Attention is drawn to the following places, which may be of interest for search:
Secure communication |
This place covers:
Memory protection being independent of the subject identity, e.g. physical write protection of a memory.
This place does not cover:
By checking the subject access rights |
This place covers:
Memory protection in which the protection depends on the subject identity, e.g. using an access list.
Attention is drawn to the following places, which may be of interest for search:
Access list protection in general |
This group is not used for classification and contains no material. Documents relating to protection against loss of memory content are classified within main group G06F 11/00, in particular in the groups G06F 11/14 or G06F 11/16.
This place does not cover:
Protection against loss of memory contents |
This place covers:
Interconnection of, or transfer of information or other signals between, memories, input/output devices or central processing units.
This place does not cover:
Interface circuits for specific input/output devices | |
Multiprogram control therefor | |
Multi-processor systems |
Attention is drawn to the following places, which may be of interest for search:
Transmission of digital information in general | |
Synchronisation in transmission of digital information in general | |
Bus networks | |
Selecting |
This place covers:
Handling requests for interconnection or transfer using burst mode transfer, e.g. direct memory access.
This place does not cover:
Access to input/output bus using combination of interrupt and burst mode transfer |
Attention is drawn to the following places, which may be of interest for search:
Remote DMA |
This place does not cover:
Handling requests for interconnection or transfer |
Attention is drawn to the following places, which may be of interest for search:
Bus networks |
This place covers:
Information transfer, e.g. on bus using universal interface adapter.
Attention is drawn to the following places, which may be of interest for search:
Digital I/O from or to direct access storage devices | |
Wireless network data management |
The information transfer is between components in a computer. Therefore, documents classified in this subgroup should relate to a data transfer in, to or from a computer.
This place does not cover:
Network bridges |
Documents classified in this subgroup can also be related to some pins configuration, and more also to system configuration.
Attention is drawn to the following places, which may be of interest for search:
Booting configuration |
This place covers:
Bus structure electrical coupling between device and bus; Live connection to bus, e.g. hot plugging.
This place does not cover:
Current or voltage limitation during live insertion |
Documents related to detection of presence and/or type of connected peripheral can be classified in this subgroup.
This place covers:
Bus structure based on a mechanical coupling between device and bus.
This place does not cover:
Back panels |
Attention is drawn to the following places, which may be of interest for search:
Computer enclosure | |
Electrical connector |
Documents related to mechanical coupling between a computer component and a bus can be classified in this subgroup, e.g. coupling of connectors or boards to a computer bus.
Attention is drawn to the following places, which may be of interest for search:
Cryptographic protocols; Financial cryptography | |
Network security protocols | |
Protocols for real-time services in data packet switching networks | |
Network protocols for data switching network services |
This place does not cover:
Details of digital computers | |
Neural networks for image data processing |
This place covers:
Pocket calculators, e-books, PDA.
Attention is drawn to the following places, which may be of interest for search:
Constructional details or arrangements for portable computers | |
Input arrangements or combined input and output arrangements for interaction between user and computer |
When a document qualifies for one of the groups below, G06F 15/02 should not be assigned:
For combination with other devices having a different main function, e.g. watches, pens: G06F 15/0208
Constructional details or arrangements: G06F 15/0216
User interface arrangements, e.g. keyboard, display; Interfaces to other computer systems: G06F 15/0225
With printing provisions: G06F 15/0233
Of the IC-card-like type: G06F 15/0241
Adapted to a specific application: G06F 15/025
For unit conversion: G06F 15/0258
For time management, e.g. calendars, diaries: G06F 15/0266
For measuring: G06F 15/0275
For data storage and retrieval: G06F 15/0283
For reading: G06F 15/0291
This place covers:
MIMD, SPMD Architectures.
Documents classified in this subgroup can also be related to digital computers for regulating and control system (G05B).
This place does not cover:
Attention is drawn to the following places, which may be of interest for search:
Constructional details on portable computers, PDAs | |
Initialization of multiprocessor systems. | |
Partitioning or combining resources in a multiprogramming arrangement. | |
Intertask communication | |
Fault-tolerance | |
Memory protection | |
Memory access priority | |
Coupling between busses | |
Multicore processors | |
Network on chip | |
Digital computing or data processing equipment or methods, specially adapted for data retrieval. | |
Control area networks (CAN) | |
Multiprocessor for program-control systems | |
Information and communication technology [ICT] specially adapted for administrative, commercial, financial, managerial or supervisory purposes; systems or methods specially adapted for administrative, commercial, financial, managerial or supervisory purposes, not otherwise provided for | |
Computer aided management of electronic mail | |
Cryptographic protocols; Financial cryptography | |
Stored and forward switching systems | |
Routing of packets in a LAN/WAN | |
Flow Control in a LAN/WAN | |
Queue Scheduling in a LAN/WAN | |
Packet switches for a LAN/WAN | |
Electronic mail systems | |
Network security protocols | |
Protocols for real-time services in data packet switching networks | |
Network protocols for data switching network services | |
Casings, cabinets, racks, chassis, drawers for data centers |
When a document qualifies for one of the groups below, none of the groups above should be assigned:
Computing Infrastructure, e.g. cluster racks: G06F 15/161
Inter-processor communication: G06F 15/163
Using a common memory e.g. mailbox, dual port memory, UMA, NUMA architectures: G06F 15/167
Using an interconnection network e.g. message passing architectures: G06F 15/173
Direct connection machines e.g. point to point topologies, buses, (partial) crossbars: G06F 15/17337
Being dynamically configurable e.g. loosely coupled nearest neighbour architecture: G06F 15/17343
Indirect interconnection networks (one or several nodes are traversed before reaching destination): G06F 15/17356
Hierarchical e.g. trees, pyramids : G06F 15/17362
Non-hierarchical: G06F 15/17368
On one dimension e.g. linear arrays,rings: G06F 15/17375
On two dimensions e.g. mesh, torus:G06F 15/17381
Topologies not covered by groups G06F 15/17375 or G06F 15/17381: G06F 15/17387
Intercommunication techniques specific to parallel machines: G06F 15/17306
Routing: G06F 15/17312
Collective communications e.g. gather/scatter, broadcast, multicast, all to all: G06F 15/17318
Synchronization, hardware support therefore: G06F 15/17325
Distributed shared memory, hardware support therefore e.g. RDMA: G06F 15/17331
Details on network interfaces: G06F 15/1735
Initialisation or configuration control: G06F 15/177
Attention is drawn to the following places, which may be of interest for search:
Interconnection of, or transfer of information or other signals between, memories, input/output devices or central processing units |
This place does not cover:
Protocol engines |
This place covers:
System on Board, System on Chip, Reconfigurable Architectures, Data-Parallel Architectures (Vector Architectures, SIMD, Systolic Arrays), Dataflow Architectures, Demand Driven Architectures.
Documents classified in this subgroup can also be related to general purpose image data processing (G06T).
This place does not cover:
Digital computers with program plugboard | |
Multicomputers |
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
Processor architectures; Processor configuration forimage data processing |
Comprising a single central processing unit: G06F 15/78
System on Board: computer system on one or more PCB e.g. motherboards, daughterboards, blades: G06F 15/7803
System on Chip: computer system on a single chip: G06F 15/7807
System in Package: computer system on a number of chips in a single package: G06F 15/7807
On-chip cache, off-chip memory: G06F 15/781
Specially adapted for real time processing e.g. comprising hardware timers :G06F 15/7814
Specially adapted for signal processing e.g. Harvard Architectures: G06F 15/7817
Tightly coupled to memory e.g. computational memory, smart memory, processor in memory: G06F 15/7821
Globally asynchronous , locally synchronous e.g. Network on Chip: G06F 15/7825
Reconfigurable architectures: G06F 15/7867
Reconfiguration support e.g. configuration loading, configuration switching (hardware OS): G06F 15/7871
Self reconfiguration:G06F 15/7882
Multiple Contexts: G06F 15/7875
Pipeline reconfiguration: G06F 15/7878
Runtime Interface e.g. data exchange, runtime control: G06F 15/7885
Embedded in CPU as a functional unit:G06F 15/7892
As a coprocessor. G06F 15/7889
Modular architectures e.g. assembled from a number of identical packages: G06F 15/7896
Comprising an array of processing units with common control, e.g. single instruction multiple data processors: G06F 15/80
SIMD multiprocessors: G06F 15/8007
One dimensional arrays e.g. rings, linear arrays, buses:G06F 15/8015
Two dimensional arrays. i.e. mesh, torus:G06F 15/8023
Other topologies.e.g. hypercubes: G06F 15/803
Associative processors: G06F 15/8038
Systolic arrays: G06F 15/8046
Vector Processors: G06F 15/8053
Details on exchanging data with memory:G06F 15/8061
Using a cache:G06F 15/8069
Details on exchanging data with registers: G06F 15/8076
Special arrangements thereof.e.g. mask, switch: G06F 15/8084
Array of vector units:G06F 15/8092
Data or demand driven: G06F 15/82
Dataflow computers: G06F 15/825
Here are specified the places which could be assigned in addition to the places above to cover further technical details:
Indexing Code G06F 3/0604 finite state machines: controlled by or implementing FSM
This place covers:
- Systems and methods for retrieving digital information stored in databases, data repositories or file systems, locally or remotely.
- Details of the organisation and preparation of information for use during the retrieving of digital information, e.g. generation of indexing information or query formulation.
- Details of data structures used for information retrieval, such as trees, lists or hashing.
- Details of query processing and the presentation of query results, e.g. in textual or graphical form on graphical user interfaces [GUIs].
- Details of browsing digital information.
- Details of architectures of databases, data repositories or file systems, e.g. physical, logical, virtual, central or distributed architectures.
- Details of managing data stored in databases, data repositories or file systems, e.g. tuning, replication, archiving, synchronisation, concurrency control and interfaces therefor such as GUIs.
- Details of optimising the storage and retrieval of digital information, e.g. de-duplication of stored data, application-specific caching and pre-fetching in file systems, (distributed) databases or web browsers.
- Systems and methods for retrieving data from structured databases and for their management. Examples of such structured databases are relational, object-oriented, multidimensional, spatial, temporal and geographical databases.
- Systems and methods for retrieving semi-structured data, e.g. XML formatted data or comma separated values.
- Systems and methods for retrieving text, audio, image, video or multimedia data from databases or for managing document libraries.
- Systems and methods for information retrieval from and browsing in the World Wide Web.
- Content-based information retrieval in databases storing media data, e.g. audio, image or video data, involves the comparison of a search query with a corresponding representation of the data. The generation of the search query and the representation of the data can involve the analysis of the data and the subsequent low-level and high-level feature extraction. G06F 16/00 covers aspects of the actual process of comparison, e.g. similarity matching. The analysis and feature extraction is covered by G06F 18/00, G06T 7/00, G10H and G10L, depending on the type of data.
- Distributed repositories involve the use of networks for data transmission. Specific protocols for information interchange, including on the application layer, are found generally under H04L.
- The mere use of databases in specific application fields (e.g. administrative or financial processing systems) is covered by the respective application field, e.g. G06Q.
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
Version control, e.g. searching in source database; configuration management, in particular source code databases | |
Error recovery, backup, mirroring | |
Pattern recognition | |
Access control or security in information retrieval systems and repositories; anonymising queries and database content | |
CAD database applications | |
Business, financial and administrative related applications | |
Image analysis | |
Musical instruments; music analysis | |
Speech analysis | |
Biological and chemical applications | |
Medical applications | |
Code conversion and compression | |
Cryptographic mechanisms or cryptographic; arrangements for secret or secure communications; Network security protocols | |
Network architectures or network communication protocols for network security | |
Network arrangements, protocols or services for supporting real-time applications in data packet communication | |
Network protocols, addressing and routing | |
Network arrangements or protocols for supporting network services or applications | |
Telephone directories in telephonic communication systems | |
Digital picture intermediate information storage | |
TV guides, electronic programming guides, video distribution, interactive television, VOD (video on demand) |
1. For documents dealing with how a given type of data is retrieved or how the database or repository for this particular type of data is organised, classification should generally take place in the indicated subgroup for the data type as follows:
- In multimedia databases - G06F 16/40
- Geographical information - G06F 16/29
- Still images - G06F 16/50
- Structured information, records - G06F 16/20
- Unstructured text - G06F 16/30
- Audio information (e.g. music, speech) - G06F 16/60
- Video information - G06F 16/70
- Semi-structured information (e.g. XML, CSV) - G06F 16/80
2. If, however, more than one particular data type is described in some detail, classification under each of the corresponding subgroups should be considered.
3. If no specific data type is indicated at all, or an explicit hint is given that the disclosed mechanism can be used for retrieval of arbitrary data types, e.g. a list of alternative data types, then for "generic" data type, use subgroups under G06F 16/90.
4. In the case of annotated data/metadata-based retrieval, the type of data used for the retrieval is sometimes different from the data type to be finally retrieved (e.g. associated images are used to retrieve text documents).
In this case, the classification should be decided according to the level of disclosed details concerning each aspect:
- According to the data type retrieved if the use of that metadata of different type is only casually described, and
- According to the data type used for retrieval, e.g. type of the metadata if specific details of this use are disclosed.
In the cases where both aspects are well-covered, double classification can be warranted.
Note: Many problems with generic data types, such as under rule 3, arise for documents describing querying systems/methods using metadata wherein the data type of the data finally retrieved is arbitrary or does not really matter. Using the above approach, these documents simply can be classified under the data type used for the retrieval and in the metadata subgroup under the generic data type subgroup. A similar approach can be applied in case of browsing a data type using a different data type.
- For example: browsing a set of audio files by browsing through the titles of the files or through images representing the audio files is to be classified under ''browsing of audio data''. In case some interesting aspects also merit a classification under text, respectively image browsing, this should be covered by double classification. Again, classification under ''browsing of generic data'' has to be considered.
5. In this technical field, one does not distinguish between invention and additional information in the sense of the IPC Guide § 77-80. Thus, symbols are allocated only as "invention information" (INV) type, irrespective of the true nature of the information: invention or additional.
This place covers:
Details of file systems and file servers. In particular, this group covers all aspects of generating, accessing and managing files.
Relationship of G06F 16/10 with its subgroups:
- For a proper functioning of the file system, management services are used by file system administrators to ensure that the file system provides the expected services; see the definitions below for the subgroup G06F 16/10. A file is an abstract data container used in file systems to manage a set of data. The internal structure of a file normally is not known by the file system, i.e. the file is opaque from the viewpoint of the file system. The internal structure and size of a file is defined by the application generating and using the file but is independent of the underlying physical storage system used to store the file. Access of user or applications to a file is granted by a file system via its file system interface providing services to create, use and manage files. These user or application oriented services are implemented via file system functionality which is referred to in this group as basic file system functionality; see the definitions below for subgroups G06F 16/13, G06F 16/14 and G06F 16/16.
In addition to this basic file system functionality, many file systems provide further functionalities, e.g. to reduce the consumption of resources, to improve the response time or to adapt the file system to individual user needs; see the definitions below for the subgroup G06F 16/17. File systems are used in many different environments and for different purposes. As a consequence, different file system types have evolved having different capabilities adapted to the specific requirements of the individual use scenarios; see the definitions below for the subgroup G06F 16/17.
- Subgroups G06F 16/13, G06F 16/14 and G06F 16/16 cover user related aspects of file systems of basic file system functionality, namely file storage and access structures, file search and file and folder operations. These aspects may be found in all types of file systems.
- Subgroup G06F 16/17 covers aspects of further file system functionalities by extending the basic functionality of the file systems e.g. to personalise file systems, to reduce the response time or to minimise required resources such as storage space. These aspects may be found in many types of file systems.
- Subgroup G06F 16/18 covers additional aspects of specific types of file systems. These aspects may be found only in one or few types of file systems.
Relationship of G06F 16/10 with G06F 3/0601:
G06F 16/10 covers all aspects related to files where the internal structure and size of a file is independent of the underlying physical storage system used to store the file. This characteristic distinguishes this group from the technical field G06F 3/0601 which covers all aspects of storing and managing data in physical storage systems where the used storage containers, e.g. volumes, LUNs, blocks, sectors, etc., depend on the individual physical storage system. Thus, G06F 3/0601 covers the use of storage oriented or storage dependent data containers, whereas G06F 16/10 covers the use of application oriented and storage independent data containers. In other words, files and directories provide a logical storage organisation on top of a physical storage layout.
Attention is drawn to the following places, which may be of interest for search:
Details of block level storage systems | |
Details of error detection and correction | |
Addressing of a memory level in which the access to the desired data or data block requires associative addressing means, e.g. caches | |
Protecting data against unauthorised access or modification |
The classification system of G06F 16/10 is organised in two dimensions. Subgroups G06F 16/11 - G06F 16/17 define different functional aspects of a standard file system. These functional aspects define the first dimension. The subgroup G06F 16/18 defines additional aspects of different file system types. These file system types represent the second dimension. Double classification for functional aspects according to the first dimension and for additional aspects of different file system types according to the second dimension may be considered if a contribution in both dimensions is present.
In this place, the following terms or expressions are used with the meaning indicated:
Data backup | A copy of data created by replicating persistent data from a given storage medium (not from a volatile memory) at a particular point in time for the purpose of potentially later recovering said data in the state it was at said particular point in time. The recovery can either occur through restoration of said replicated data onto a storage medium or memory or by using the memory/medium onto which the copy was created. A backup of data typically is used to at least partially correct or restore lost or corrupted data, although it is accepted that the restored state usually is not identical to the state when the data loss occurred, i.e. some data may be unrecoverable. |
File | A file is an abstract data container used in file systems to manage a set of data. The internal structure of a file normally is not known by the file system, i.e. the file is opaque from the viewpoint of the file system. The internal structure and size of a file is defined by the application generating and using the file but is independent of the underlying physical storage system used to store the file. |
File system | A file system (or filesystem) is a means to organise data expected to be retained after a program terminates by providing procedures to store, retrieve and update data. |
Hierarchical Storage Management (HSM) | A particular case of data migration wherein the target medium is lower in a hierarchical storage system and is used for less frequently used data or for data that is no longer actively used. The target medium is suitable for longer-term storage, is slower and has lower cost per unit of data. In contrast to backup, HSM systems do not provide an additional instance of the data. |
Data migration | Moving data from one memory or storage medium to another without effectively replicating it since ultimately only one copy persists. Examples: transferring data from a disk to another one having different reliability, performance or cost properties. |
Data replication | The act of creating several instances of the same data of which at least two are available in the absence of errors and modifications of the original data. The different instances may be stored on different locations of a given storage medium or memory or they may be stored on physically distinct media or memories. The concept of replication is independent of the purpose for which it is used, e.g. replication may be used for potential restoration of data, for load balancing and performance improvement, for fault tolerance, or for increasing the availability of data, etc. Data replication can occur at different levels of abstraction, e.g. at database level, at file system level, at the level of disk/storage I/O operations or at the level of (main) memory pages or even individual memory write instructions. |
This place covers:
Long-term storage or digital preservation of historical data object versions whereas the fact that files are stored in an archive is generally known to the user in contrast to Hierarchical Storage Management (HSM) systems in which the actual storage location is NOT known to the user. Whenever a file has been stored in the archive, the original file in the file system will be deleted, normally to free storage space in the file system.
This place does not cover:
Lifecycle management in storage systems | |
Backup systems |
Attention is drawn to the following places, which may be of interest for search:
Hierarchical storage management (HSM) systems |
This place covers:
- Conversion of a file system from a first to a second type or format.
- Upgrade from an older to a newer file system version or vice versa.
Attention is drawn to the following places, which may be of interest for search:
File system format conversion of restoring backed-up files |
This place covers:
Migration of complete file systems from a first to a second environment, e.g. for replacing old server systems.
This place does not cover:
Migration mechanisms in storage systems, e.g. volume migration |
This place covers:
- Policy-based management of file systems, e.g. in combination with archiving, allowing automatic management of file systems.
- Quota management.
- Allocation policies.
This place does not cover:
Backup policies | |
File migration policies for HSM systems |
This place covers:
Policy-based management of file systems characterised by the use of retention policies for managing the lifetime of files (lifecycle management of files).
This place does not cover:
Retention policies for HSM systems |
This place covers:
Management of snapshots of file systems, e.g. snapshot creation, deletion.
This place does not cover:
The use of snapshots for specific applications, e.g. backup or recovery should be classified in the application fields |
This place covers:
- File indexing methods used in file systems and their management, e.g. using directories, trees (e.g. Comprising inodes, vnodes) for indexing and organising files in the file system.
- File indexing methods used in distributed file systems, e.g. the use of a centralised or distributed index in a distributed file system.
This place does not cover:
Arrangements of input from, or output to, record carriers |
This place covers:
Use of distributed indices in file systems, e.g. Distributed Hash Tables (DHT).
This place covers:
Use of hashing or hash functions for indexing files in file systems wherein hashing values are calculated from the file content or file metadata, e.g. file name, file path, wherein the internal file structure or the data type of the file content is not relevant for the calculation of the hash-values.
This place does not cover:
Content-based indexing of textual data |
This place covers:
Techniques and architectures for searching files in a file system based on file metadata, e.g. such as file name, associated keywords, time and owner information, creation date, file signatures or dependencies between files.
Attention is drawn to the following places, which may be of interest for search:
Content-based searching of textual data | |
Content-based searching of multimedia data | |
Content-based searching of image data | |
Content-based searching of audio data | |
Content-based searching of video data | |
Content-based searching of HTML documents |
This place covers:
Specific techniques for generating file search queries.
This place covers:
Techniques for processing search queries for files in a file system.
Specific techniques for processing search queries for files having specific contents, e.g. image files, audio files, video files, multimedia files, semi-structured files or text files.
Such specific file search processing methods must be classified in the file type specific groups.
This place covers:
Techniques for searching files based on file content signatures such as hash values generated from the file content. The calculation of the file content signature does neither take into account internal structures of the file nor the data type of the file content.
Specific methods for searching files having specific contents or data types, e.g. image files, audio files, video files, multimedia files, semi-structured files or text files. Such specific file search methods must be classified in the file type specific groups.
This place covers:
Specific methods for the presentation of file search/query results.
This place covers:
- Details of operations performed on files and folders, in particular at the user level, e.g. file copy, file delete, (automatic) classification of files.
- Generation of file meta data, such as file names.
- Details of user-interfaces specifically adapted to file systems.
This place covers:
Erase or delete operations on files and folders, e.g. secure or efficient erase/delete.
This place does not cover:
Erasing in storage systems |
This place covers:
- Methods for generating metadata for files and folders.
- Methods for generating (content based) names of files and folders.
This place covers:
Methods for converting file and folder names, e.g. for adapting the file names to different OS.
Attention is drawn to the following places, which may be of interest for search:
File name conversion of backed up files |
This place covers:
Aspects of user-interfaces used for accessing or managing files and folders.
This place does not cover:
Presentations of file search/query results |
Attention is drawn to the following places, which may be of interest for search:
Generic interaction techniques for graphical user interfaces |
This place covers:
General optimisations which apply to more than one file system type, e.g. customisation, caching, prefetching, redundancy elimination, support for shared file access, synchronisation, etc.
Attention is drawn to the following places, which may be of interest for search:
Specific optimisations which apply only to exactly one file system type |
This place covers:
- Details of using local or remote file caches, such as file caches in clients, servers or proxies.
- Details of using methods of prefetching or hoarding of remotely stored files, e.g. for supporting disconnected operations of mobile devices.
- File caching policies, e.g. selection of files to be cached.
G06F 16/172 covers the application of caching in file systems, namely all aspects of using caches for caching files in file systems whereas G06F 12/0866 covers all aspects and details of implementing caches in storage systems.
Attention is drawn to the following places, which may be of interest for search:
Caching for peripheral storage systems, e.g. disk cache; all aspects of caching, applied to file caching, which are not specific to files or file systems, e.g. details of cache management, caching architectures | |
Caching used in the WWW for retrieving HTML pages | |
Network-specific arrangements or communication protocols for caching |
This place covers:
Details of file system defragmentation techniques where file system knowledge is used to reduce the number of file fragments stored on the underlying storage system. These techniques typically are performed by the file system so that the underlying storage system is not aware that a defragmentation operation is executed.
Details of storage system defragmentation techniques performed by the underlying storage systems without using file system knowledge, particularly in management of blocks in storage devices, is classified in G06F 3/064. In this case, the defragmentation is performed by the storage system but not by a file system.
This place does not cover:
Saving storage space on storage systems | |
Details of storage system defragmentation techniques performed by the underlying storage systems without using file system knowledge |
This place covers:
Details of file system free space management where file system knowledge is used to manage the free space on the underlying storage system. These techniques typically are performed by the file system so that the underlying storage system is not aware that free space management is performed.
Details of storage system free space management performed by the underlying storage systems without using file system knowledge, particularly in management of blocks in storage devices, is classified in G06F 3/064. In this case, the free space management is performed by the storage system but not by a file system.
This place does not cover:
Saving storage space on storage systems | |
Details of storage system free space management performed by the underlying storage systems without using file system knowledge |
This place covers:
- Means and methods for the customisation of file systems.
- Support for localisation (multi-language support).
- Personalisation of the file system to users of the file system.
This place covers:
- Monitoring events, such as changes or updates to files or file metadata and file system metadata.
- Logging changes or updates to files or file metadata and file system metadata.
If the techniques of monitoring file system events are used in a specific application domain, e.g. for synchronisation, indexing, backup, etc., classification in the specific application domain must also be considered.
This place covers:
- Specific adaptations of the file system to reduce the power consumption, e.g. in mobile devices.
- Specific adaptations of the file system for copying with limited storage space, e.g. by deleting (policy-based) selected files.
This place does not cover:
Saving storage space on storage devices | |
Power saving in storage systems |
This place covers:
Techniques for eliminating redundancies in file systems, e.g. by copy on write, sparse files or deduplication.
This place does not cover:
Elimination of redundancy for the purpose of backup |
This place covers:
Elimination of redundancies in file systems by using compression methods, e.g. sparse files.
Attention is drawn to the following places, which may be of interest for search:
Details of compression | |
Protocols for data compression |
This place covers:
Elimination of redundancies in file systems by deduplication based on segments of a file when the structure of the file is known. The individual segments of the file may have different lengths.
This place does not cover:
Deduplication techniques in storage systems for the management of data blocks |
This place covers:
Redundancies in file systems that are eliminated by deduplication based on typically equally sized chunks of a file when the structure of the file is unknown.
This place covers:
Redundancies in file systems that are eliminated by using delta-files, e.g. for storing multiple versions of files whereas only the modifications between subsequent versions of a file are stored in the delta-file.
This place covers:
Techniques for supporting shared access to files, i.e. more than one application is allowed to access the same file.
This place covers:
File systems providing support for concurrency control to serialise access to files (pessimistic methods like locking) or provide for conflict resolution methods to resolve file system states where conflicting writes to a file have taken place (optimistic methods).
This place covers:
Locking methods for file systems allowing shared and concurrent access to files.
This place covers:
- Details of synchronisation in file systems, e.g. synchronisation architectures, conflict resolution, administration of synchronisation by using synchronisation policies.
- Techniques for transparent or automatic synchronisation of files in file systems whereas no user interaction is necessary to perform the synchronisation, e.g. transparently keeping replicated file copies consistent with each other, e.g. by propagation of changes to all file replicas.
Attention is drawn to the following places, which may be of interest for search:
File management policies in general | |
Change detection in file systems | |
Distributed file systems | |
Synchronisation of structured data | |
Protocols for data synchronisation between network nodes |
In this place, the following terms or expressions are used with the meaning indicated:
Synchronisation | Synchronisation is a service provided by file systems to synchronise two or more independent file systems or to synchronise replicas in a distributed file system. |
This place covers:
The non-transparent synchronisation of files in file systems whereas user interactions are necessary to perform the synchronisation, e.g. user-based file selection, conflict resolution with user support.
This place covers:
Details of file format conversion during synchronisation, e.g. synchronisation between heterogeneous file systems.
This place covers:
Details of specific file system types that are specific to the individual file system types, e.g. details of file systems allowing only read-only access to files.
Attention is drawn to the following places, which may be of interest for search:
Generic aspects of file systems |
This place covers:
- File systems where data is only appended to existing data
- Append-only file systems using logs to store data
This place covers:
File system of type WORM (Write Once Read Many), e.g. by using WORM hardware, by using standard hard disk extended by additional functionality implementing the WORM semantic.
This place covers:
File systems using journals to store files and file metadata.
This place covers:
Aspects of distributed file systems, e.g. architectures, specific management aspects.
This place covers:
Systems and methods for storing files in a Network-Attached Storage system (NAS) which provides data access on the file level. The roles of the clients and the file server(s) are distributed over the network.
This place does not cover:
Distributed or networked storage systems which provides data access on the block level | |
Protocols for distributed storage of data in a network |
In this place, the following terms or expressions are used with the meaning indicated:
NAS | network attached storage |
SAN | storage area networks |
This place covers:
Details of management of NAS, e.g. data placement policies of file or file fragments.
This place does not cover:
Management of SAN |
This place covers:
Details of providing network file services by Network-Attached Storage (NAS) file servers accessed over a network using file access protocols, e.g. by using Network File System (NFS) or Common Internet File System (CIFS) to access files.
This place does not cover:
Network file access protocols |
This place covers:
File systems storing files in peer-to-peer like storage networks.
This place does not cover:
P2P communication protocols |
In this place, the following terms or expressions are used with the meaning indicated:
File system peer | A file system peer implements both the file server and the client role. Thus, a peer may request in its client role a file from another peer. Additionally, the same peer may provide files in its file server role to other peers. Thus, both the client and the server role are distributed over the network. |
This place covers:
Details of file management specifically adapted to peer-to-peer like storage networks, e.g. data placement of file or file fragments.
This place does not cover:
Topology management mechanisms of peer-to-peer networks |
This place covers:
Details of file systems replicating files on more than one storage place, e.g. a single file or even a complete file system is replicated.
Attention is drawn to the following places, which may be of interest for search:
Protocols for supporting replication or mirroring of data between network nodes |
In this place, the following terms or expressions are used with the meaning indicated:
Replicated file | A replicated file is a copy of an original file and stored in a different storage place as the original file. The replicated file is kept consistent, i.e. synchronised, with the original file. |
File replication | File replication is a service provided by the replicated file system whereas the fact that files are replicated is transparent to the users, such as applications, of the replicated file system. |
This place covers:
Details of management of replicated file systems, e.g. data placement policies of file replicas.
This place covers:
File systems specifically adapted to or used in flash memory, SSDs, etc. File system data structures or corresponding methods are adapted by taking constraints of the static storage into account.
Attention is drawn to the following places, which may be of interest for search:
Dedicated interfaces to non-volatile semiconductor memory device | |
Dedicated interfaces to non-volatile semiconductor memory arrays |
This place covers:
Hierarchical storage management (HSM) used in file systems, e.g. lifecycle management, whereas the fact that files are stored on different levels of the HSM system is generally NOT known to the user in contrast to archive systems in which the actual storage location is known to the user. Further, in contrast to backup system only one copy of data objects exists. Whenever a file has been migrated from one level to another level of the HSM system the file copy stored in the previous level of the HSM will be deleted, normally to free storage space in the HSM system.
This place does not cover:
Archive systems |
Attention is drawn to the following places, which may be of interest for search:
Life cycle management in storage devices | |
Hybrid storage combining heterogeneous device types | |
Backup systems (in backup systems a second, backup copy is created from the original data without deleting the original data in the primary storage) |
This place covers:
Details of parallel file systems, e.g. General Parallel File Systems (GPFS).
This place covers:
File systems supporting transactional operations, e.g. commit processing, logging and recovery of file transactions, on file system objects (e.g. files, directories, etc.).
Attention is drawn to the following places, which may be of interest for search:
Commit processing in structured data stores |
This place covers:
File system supporting different (historic) versions of e.g. files, directories, etc.
This place covers:
Virtual file systems where at least one file system component is virtualised, e.g. transparent access to compressed archives via a virtual file system e.g. DoubleSpace. Another example are virtual file systems implemented by database systems. Thus, file system requests are transparently translated into database queries.
This place covers:
Virtual file systems with virtual folders or a virtual folder structure.
This place covers:
Details of the file system for accessing devices and non-file objects, e.g. accessing CPU state information, using the standard file system access operations provided by a file system-like interface, e.g. the procfs, sysfs, usbfs, devpts or BSDs kernfs. From an application point of view the devices and non-file objects are accessed as virtual files.
This place does not cover:
Dedicated interfaces to storage systems |
This place covers:
- Structured data stores comprising all sorts of database management systems based on a particular structured data model such as hierarchical, network (CODASYL), relational, object-relational, object oriented, deductive, and semantic, entity based systems.
- Structured data, in general, means that the data has a certain predetermined structure which is typically the same for a set of managed / stored objects, for example, a set of data records which conform to a certain schema, i.e. the records have a particular number of fields of a certain data type. A schema need not be described explicitly in a document.
- A database system can be implemented on top of a file system, i.e. the records might be simply stored in files. Another indication for structured data could be a sophisticated declarative query / data manipulation language. This criterion should be used when no information about the data type or the storage technology used is available.
- Particular applications of structured data are multidimensional databases that generally are based on specific relational data models.
Unstructured data being binary data types such as image or audio data, which have merely a bit string structure (binary objects, files) or text documents including documents with mark-up such as HTML. Unstructured data is classified according to the respective data type (audio, image, video, multimedia, web, file systems). For semi-structured data, in particular XML, see G06F 16/80.
This place covers:
Aspects of defining and managing database models and systems at the logical or external levels, above the physical storage. The group is concerned only with aspects of managing a single database system. Details of tools, functions or services used to support a database administrator including data maintenance activities to support front-end applications.
Attention is drawn to the following places, which may be of interest for search:
Database storage and indexing details | |
Data updating | |
Data querying (retrieval) |
This place covers:
- Systems which support the creation and maintenance of data dictionaries in database systems.
- Details for mappings between schemas, where the mapping solution is independent of the application.
Attention is drawn to the following places, which may be of interest for search:
Uses of mappings between schemas in the relevant application group, e.g. object relational mappers and translation layers in client/server interfaces | |
Abstract models in federated databases systems | |
Replication and update of data dictionaries in distributed database systems |
This place covers:
Support for users to interactively model data dictionaries or conversions from other data models into the data model supported by the DBMS.
This place covers:
Facilities that allow the data dictionary of a database to be changed and support the continued operation of the database applications or of other interfacing systems.
This place covers:
Facilities to allow a database to be migrated between two different DBMS or between different versions of the same DBMS.
This place covers:
Facilities that promote improvements to the quality of existing data of a database.
Attention is drawn to the following places, which may be of interest for search:
Support for consistency and integrity of data during update operations |
This place covers:
Facilities to support the administration of the database operation, i.e. database tuning, not covered by specific storage tuning G06F 16/2282.
This place does not cover:
Database performance monitoring | |
Storage tuning including database reorganisation |
This place covers:
Support in a database system to keep the history of changes of records.
This place does not cover:
Querying versioned data | |
Querying temporal data |
Attention is drawn to the following places, which may be of interest for search:
Multi-version concurrency control |
This place covers:
How structured data is stored and maintained at the physical level including indexing in structured data.
An index of a structured database is updated periodically.
This place covers:
Details to support databases with storage oriented by columns.
This place covers:
Details of storing and interfacing with Large Objects in databases, e.g. Binary Large OBjects (BLOBs).
This place covers:
Creation and/or assembly of index structures.
Attention is drawn to the following places, which may be of interest for search:
Indexing structures for textual data |
This place covers:
Bitmap indices and other array oriented indexing structures.
This place covers:
- Hierarchical indexes and functions therefor, e.g. merging of new data entries into the hierarchical index
This place covers:
Details of hash table implementations used for indexing in structured databases.
This place covers:
Any kind of multidimensional indexes for database systems belong in this group. Double classification with the further groups in G06F 16/2228 should be done when needed.
Dimensionality reduction is used for index generation of a multidimensional database.
This place covers:
Automatic or manual management of an already existing index comprising only the organisation but not the modification or updating of index entries. This means that normal adjustments of the index as a consequence of an update operation in a database (insert, delete, update) are not classified here, but reorganisations of the index (e.g. as consequence of degradation due to many updates in the database) are classified here.
Facets: The amount of clustering of an index in a relational database is analysed in order to optimise the index.
This place covers:
Aspects of storing and managing tablespace structures in secondary memory, including partitioning of tables over multiple storage areas, e.g., disks, and reorganisation of databases.
This place covers:
Support for user defined types or abstract data types.
This place covers:
Updating a database based on update requests to modify database records; the update requests are made by users or front-end applications.
This place does not cover:
Transaction processing |
Attention is drawn to the following places, which may be of interest for search:
Concurrency control in file systems |
This place covers:
Optimistic approaches for concurrency control, i.e. conflicting accesses are not prevented but resolved later.
This place covers:
Timestamp based concurrency schemes.
This place covers:
Version based concurrency schemes.
This place covers:
Pessimistic approaches (avoiding conflicts) for concurrency control, e.g. locking, multiple versions without time stamps, others.
This place covers:
Locking methods for concurrency control, e.g. multi-granularity/hierarchical/range locking, lock escalation, pre-claiming of locks/consistency levels/predicate locks, distributed locking, locking implementation details, e.g. locking table.
This place covers:
Facilitating the definition of requests for updating data.
This place covers:
Details of implementing logging of database update operations; detecting changes for the purpose of notifying users or other systems.
This place does not cover:
Use of logging for replication or synchronisation |
This place covers:
Ensuring database consistency and other ACID (Atomicity, Consistency, Isolation, Durability) properties. Use of triggers and stored procedures to support update operations and related impact in the database.
Attention is drawn to the following places, which may be of interest for search:
Online updates |
This place covers:
Handling record operations for inserts, edit, deletion, and undo. The operations occur on an individual basis, on batches or in the context of transaction processing.
Attention is drawn to the following places, which may be of interest for search:
Aspects of transaction processing regarding CPU programming |
This place covers:
Handling bulk updates during operation of the database, e.g. to minimise impact on the performance for users.
This place does not cover:
Data conversion details |
This place covers:
Aspects of ensuring that materialised views, or persistent queries, are kept up to date during update operations.
Attention is drawn to the following places, which may be of interest for search:
Query processing | |
Use of materialised views for optimisation |
This place covers:
Processing retrieval requests, i.e. finding records matching a query.
Attention is drawn to the following places, which may be of interest for search:
Using cached query results | |
Caching (including caching in Client/Server database systems): for database cache management | |
Plan operators for distributed queries such as join-algorithms adapted to distributed query processing | |
Processing of distributed queries |
This place covers:
- All aspects of query formulation; textual, graphical, explicit or implicit formulation of database queries.
- User interfaces therefor (including help systems therefor).
Attention is drawn to the following places, which may be of interest for search:
Interaction techniques for graphical user interfaces | |
Conversion of a query to an internal format |
This place covers:
- Query wizards such as in MS access for constructing queries.
- Query construction based on database schema or entity relationship diagram of database.
Note: Often the user can see the query statement, which allows the user to learn the syntax of the query language.
- ntelligent help systems for the formulation of queries.
Further examples:
- A query assistant that permits the user to enter valid SQL queries; use of dialog boxes.
- Context sensitive help system for formulation of SQL queries; e.g. lists table names.
Attention is drawn to the following places, which may be of interest for search:
Interfaces for the formulation of natural language queries |
This place covers:
- All iterative approaches to querying; typically the user interacts with a display of the results of a preceding query in order to (re)formulate a new query; for example more restrictive query predicates might be formulated to narrow the focus of the query.
- Feedback on cardinality of qualifying result set.
This place covers:
- Graphical user interfaces (typically displaying charts, plots, images, maps, multi-media documents, or cubes etc.) for specifying query predicates for attribute values.
- (Hierarchical) menus and forms used for specifying query predicates for attributes.
- Menu entries that typically are generated by querying database catalog or tables; also use of menus to select predefined queries.
- Query-by-example languages where the user fills example values into a tabular scheme.
This place does not cover:
Graphical user interface is based on a visual database schema |
Attention is drawn to the following places, which may be of interest for search:
Iterative querying |
This place covers:
Queries formulated in natural language for querying structured data.
Attention is drawn to the following places, which may be of interest for search:
Natural language analysis, translation, semantics |
This place covers:
Details of query languages, e.g. SQL features.
Attention is drawn to the following places, which may be of interest for search:
Optimisation aspects | |
Implementation aspects concerning the execution of the queries |
This place covers:
Active constructs, e.g. constraints; triggers; Event-condition-action rules.
Attention is drawn to the following places, which may be of interest for search:
Implementation aspects |
This place covers:
Embedded query languages, e.g. embedded SQL; data communication structures for cursors, etc.
This place covers:
Grouping and aggregation, e.g. GROUP-BY (and Having), SUM, MIN, STDDEV, Percentiles etc.
Examples:
Data Cube: A Relational Aggregation Operator Generalizing Group-By, Cross-Tab, and Sub Totals.
Attention is drawn to the following places, which may be of interest for search:
Implementation aspects |
This place covers:
Definition, processing and use of stored procedures.
This place covers:
Data retrieval commands and view definitions, e.g. in SQL, the command SELECT (including all features of select statements, unless there are particular classes for them) and VIEWs including view definitions.
This place covers:
Query languages designed to support particular applications; commands for extensible query languages for adding user-defined/foreign functions etc.
This place covers:
Query processing comprises all processing steps that need to be done in order to process a received formulated query: parsing, translation, execution and delivery of the results (or an execution error).
For Translating queries between clients (applications) and servers (data sources) see G06F 16/23 and G06F 16/27; for parsing see G06F 8/427.
This place covers:
- Translation of the expression in user natural language, e.g. spoken language, of the information to be retrieved, into database queries, e.g. the mapping from natural language (e.g. English) to SQL;
- Question/answering systems;
Attention is drawn to the following places, which may be of interest for search:
Natural language analysis, translation, and semantics |
This place covers:
- Generation of code for given access plan;
- Invalidation of access plans when database objects / indexes etc. are dropped.
This place covers:
Translations into an internal format such as query graph models, algebra, parse trees.
This place covers:
Standardisation (conjunctive/disjunctive normal form) and Simplification (general logical transformations like De Morgan etc.).
Note: The standardisation and simplification steps also could be viewed first as simple query optimisation steps, but they have been put under query translation because these steps are often independent of the actual optimiser used; the technical aim is to provide a standardised input format for the query optimiser.
This place covers:
- Rewriting and plan optimisation
- Optimization of application programs by modifying code etc.
This place covers:
Optimisation of queries for parallel database systems with respect to best use of parallel execution possibilities;
Double classification could be necessary; for example, when the join order is optimised to enable bushy trees for parallel join processing and additional classification in G06F 16/24544 is needed.
This place covers:
- Transformations of the internal representation of the query: transformations (by means of rewriting rules) between different internal representations on a logical level (e.g. query graph model) and transformations from a logical representation to a physical representation having physical plan operators (i.e. hash join or index-nested-loops-join).
- Transforming a (rewritten) logical internal representation into a physical execution plan with concrete plan operators; typically involves selection of plan operators and their execution order based on estimated execution costs.
- Manual rewriting of query statement; includes also logical tests such as for deciding query containment (for query folding etc.); rewriting one query into several queries.
This place covers:
View integration and subquery decorrelation.
This place covers:
Rules for restrictions, joins, group-bys, aggregations, sorting, etc.
This place covers:
Query folding where a query is mapped to existing results including partial mapping; special case: reuse of cached results of a particular query.
Attention is drawn to the following places, which may be of interest for search:
Maintenance of materialised views (updating, replication) | |
Database cache management in general |
This place covers:
Common subtree recognition and optimisation, also for multi-query optimisation.
Attention is drawn to the following places, which may be of interest for search:
Query folding (mapping a query to cached results or materialised views) |
This place covers:
- Enumeration algorithms for plan generation and search strategy;
- Selectivity and cost estimation including learning based techniques for these estimations.
Attention is drawn to the following places, which may be of interest for search:
Selectivity estimation or determination for joins | |
Sampling/generation of statistics |
This place covers:
Join enumeration algorithms for determining the join order, e.g. left deep plans vs. bushy plans etc.
This place covers:
- Estimation of the selectivity of query predicates: e.g. estimating the selectivity of the predicate ''AGE=40'' on a table means estimating which percentage of the records in this table has the value 40 in attribute AGE.
- Other aspects of query cost estimation.
This place covers:
- Extensibility;
- Particular query types, etc. optimiser hints;
- Query modifications to implement security control (e.g. by adding predicates to a query according to a security policy in order to mask data).
Attention is drawn to the following places, which may be of interest for search:
Security, Access control |
This place covers:
- Query optimisation at run time of the query.
- Using execution time statistics for re-optimisation.
- Progress estimation during query execution.
This place covers:
- Actual execution of a single query with a given query execution plan;
- Execution of multiple queries;
- Database hardware, e.g. parallel database machines.
This place covers:
- Cache management at the database server itself, at the client/workstation or at the application server.
- Cache management strategies such as cache granularity management.
- Semantic cache management.
- Determining what data to cache.
Attention is drawn to the following places, which may be of interest for search:
Query optimisation exploiting the cache |
This place covers:
- Physical operators used to execute operators in a query execution plan; includes particular execution strategies such as returning only the top N rows or delayed delivery of full query results.
- Non-standard query processing operations.
This place covers:
- Algorithms for unary operations (which have only one table/data stream as input), such as aggregations/groupings, sorts or scans.
- Data partitioning operators.
- Hash, random, range, window partitioning, etc.
- Can also include (partial) replication.
This place covers:
For example, including algorithms implementing SQL clauses such as having, groupby, cube, rollup, etc.
Attention is drawn to the following places, which may be of interest for search:
Corresponding query language aspects |
This place covers:
Scan operators, index access.
This place covers:
All operators except joins which have two tables (data streams) as input, such as: universal quantification, division, intersection, union, etc.
Attention is drawn to the following places, which may be of interest for search:
Joins |
This place covers:
Algorithms for joins such as index nested loops join, sort merge join, hash join, etc.
This place covers:
Compression, bit vectors, surrogate processing, main memory algorithms, etc.
This place covers:
- Pointer-based join operations.
- Fast pointer dereferencing.
- Pointer swizzling.
Double classification under G06F 16/289 (OODBMS) should be considered.
This place covers:
- Rules including rule constructs in SQL and active databases;
- Deductive databases in general e.g. datalog; fixpoint semantics; deductive database techniques, in general.
Attention is drawn to the following places, which may be of interest for search:
Inference methods or devices |
This place covers:
- Trigger and integrity constraints as commonly used in the context of relational or similar database systems; see example in the third version of the Structured Query Language, SQL3.
- Execution models for determining the correct execution order for multiple constraints/triggers that need to be executed.
- Semantical aspects such as relation to statement/transaction atomicity.
Attention is drawn to the following places, which may be of interest for search:
Query language aspects |
This place covers:
Operators for computing recursive queries, e.g. in the version of the Structured Query Language adhering to the 1999 standard, SQL1999.
This place covers:
- Query processing for data streams: continuous queries over a data set; the queries are executed continuously over a database, which means that the query must be executed against newly inserted and updated data.
- Event subscription processing where the event filters (= subscription requests or profiles) are seen as continuous queries.
This place covers:
Specific properties of the hardware environment, e.g. GPU, SSDs, on which the query is executed being taken into account.
This place covers:
Query processing based on:
- User profiles.
- Weighting of query attributes specifying preferences of users, e.g. for ranking/relevance.
- User context such as location or user's information needs.
Learning aspects for adapting to user needs, e.g. learning user preferences.
This place covers:
- Query processing using user-defined meta-data / annotations to the data, whereas the user-provided metadata is added to the database.
- Manual classification of data contents for query processing.
This place covers:
Using the context of a user or client application as query criteria; context can be diverse, e.g. user's mood or location.
This place covers:
Sorted output of query results in order of relevance; can use weights, etc., to specify relevance. Using this relevance for ranking and cut-off of results after returning the top-N hits.
Similarity queries for structured data could be classified in this group or for example in G06F 16/24558 (binary matching operations, if the document concerns the implementation of the similarity matching); for sorted result output by relevance, see G06F 16/24578.
This place covers:
Approximate query processing which is based on sampling, models or statistical techniques and creates fast, but imprecise answers to queries such as:
- Queries for the generation of statistics about the database, e.g. attribute value distributions.
- Database sampling.
This place covers:
Specific support for data mining such as database operators for that purpose or optimisations.
Attention is drawn to the following places, which may be of interest for search:
Clustering and classification in relational databases |
This place covers:
Query processing based on fuzzy functions or imprecise query predicates. Text related search predicates (using phonetic searches, etc.) should be further classified in the specific text class for this aspect.
This place covers:
- Mapping of queries for distribution transparency.
- Optimizing the execution order of the plan fragments (subqueries) which need to be executed at the various sites.
This place covers:
- Querying sequence data, such as time sequences like, for example, stock price sequences, which typically supports operations such as aggregations or window queries on the sequence data.
- Implementation techniques such as indexing and optimisation therefor.
- Querying versioned data.
Attention is drawn to the following places, which may be of interest for search:
Processing data streams |
This place covers:
Querying
- Specifically adapted to deal with temporal data such as T-SQL or bitemporal models;
- Referring to points in absolute time such as timestamps.
Attention is drawn to the following places, which may be of interest for search:
Use of timestamps for internal purposes such as concurrency control | |
Documents where time or date attributes are treated as ordinary attributes without specific support | |
Time sequences which refer to a relative sequence of points in time |
This place covers:
- Display of the results of a query, e.g. in tabular form, with interface to modify display formats.
- Complex visualisations such as displaying results on a geographical map.
Attention is drawn to the following places, which may be of interest for search:
Browsing techniques (e.g. navigating in database) |
Generating/modifying the layout of business reports etc. is not classified in G06F 16/00.
This place covers:
Interfaces between systems involving at least a database supporting ad-hoc interaction, systematic integration or some type of co-operation.
Attention is drawn to the following places, which may be of interest for search:
Organised distribution or systematic replication of data between databases or database systems |
This place covers:
Solutions specific for the interfaces between clients and a database system.
This place covers:
Details for implementation of data workflows transferring data from a plurality of databases into a common data store, in particular, the Extract, Transform, Load (ETL) operations to create and maintain data warehouses.
This place covers:
Systems providing a data abstraction layer on top of a set of heterogeneous database systems to convey the concept of a single virtual database to the end users or client systems.
Attention is drawn to the following places, which may be of interest for search:
Distributed queries |
This place covers:
- Specific details of exchanging data between database systems involving a conversion of the data.
- Export and import operations involving some conversion.
This place covers:
- Visualisation of data sets from a database in order to allow a user to discover interesting data properties without formulating an explicit query.
- Using the meta data (schema information) for visualisation of attribute values.
- Browsing a database including navigating between data items.
- Adaptation of the browsing process to the specifics of a database, e.g. displaying database schema information for browsing.
Examples:
- Organising large (structured) data sets by grouping to make them conveniently accessible on a small display device.
- Visualising structured data such as: interactions between customers and merchants and interactions associated with a time value, e.g. hits per hour on a web server.
Attention is drawn to the following places, which may be of interest for search:
Query formulation aspects | |
Query result display |
This place covers:
Systems that distribute or replicate data between themselves; descriptions of architectures thereof; details in relevant subgroups.
This place covers:
Implementation details of asynchronous replication and in particular for reconciliation procedures.
Attention is drawn to the following places, which may be of interest for search:
Concurrency control for distributed databases |
This place covers:
Implementation details for data partitioning between databases that fully or partially distributed the data between themselves.
This place covers:
Implementation details of specialised database models which are not already covered by subgroups G06F 16/21 - G06F 16/27.
In general, double classification in at least one of the functional subgroups G06F 16/21 - G06F 16/27 and one of the subgroups of G06F 16/28 should be considered.
This place covers:
Implementation details of supporting the storage and management of hierarchical data.
This place covers:
Assembly or functionality of multi-dimensional databases or data warehouses [MDDB].
Double classification with regard to subgroups G06F 16/22, G06F 16/24, and G06F 16/26 should be considered.
This place covers:
Implementation details specific to relational databases not - covered by any of the subgroups G06F 16/21 - G06F 16/27.
This place covers:
Clustering or classification of structured data. Classes / clusters may already exist or can be created during the classification / clustering process. Documents disclosing class / cluster management of classification or clustering systems also can be found in this group.
Attention is drawn to the following places, which may be of interest for search:
Clustering or classifying textual data |
This place covers:
- Cluster or class visualization or browsing.
- Graphical presentation of clusters or classes as result of a clustering or classification process. Additional data can be displayed with the clusters or classes. Typically, when a mouse pointer is brought over them, additional data about the clusters is displayed (interactive cluster display device).
Attention is drawn to the following places, which may be of interest for search:
Visualisation or browsing of textual data |
This place covers:
Implementation details specific to entity-relationship models not covered by any of the subgroups G06F 16/21- G06F 16/27.
In general, double classification in at least one of the functional subgroups G06F 16/21- G06F 16/27 and subgroup G06F 16/288 should be considered.
This place covers:
- Implementation details specific to object-oriented databases not covered by any of the subgroups G06F 16/21- G06F 16/27.
- Hybrid Object-Relational database models.
In general, double classification in at least one of the functional subgroups G06F 16/21 - G06F 16/27 and subgroup G06F 16/289 should be considered.
This place covers:
Data structures and retrieval of geographical or spatial information, e.g. digital maps.
Attention is drawn to the following places, which may be of interest for search:
Location-dependent Web search services | |
Instruments for geographical navigation | |
Geographical navigation systems, route searching | |
Retrieval, searching and output of Points of Interest (POI) information | |
Three dimensional geographic models |
This place covers:
Retrieval of unstructured or raw text data in databases and/or employing metadata of the text type for retrieving other information, possibly of a different type.
This place does not cover:
Document management systems |
Attention is drawn to the following places, which may be of interest for search:
Image retrieval using shape and object relationship, including layout-based retrieval of text documents | |
Retrieval from the web, e.g. using search engines | |
Text processing, parsing or translation of natural language |
This place covers:
- Details about the creation or structure of an index.
- Updating or maintenance of indexes.
This place covers:
- Extraction of strings from a text for indexing purposes.
- Identification or extraction of important information (special words, regions, relations between words in the text, etc.) from text content using mathematical calculations or dictionaries. The weight value indicating the importance of the information may be attached to it.
Facets:
- Automatically extracting information for annotating a document;
- A text is stemmed, stop words are removed and the remaining words are weighted according to their frequency of occurrence;
- Segmentation and topic identification of texts. Weight values may be used to express semantics;
- Extracting relevant information for indexing from natural language texts by parsing the text into components and extracting elements of information from the respective components;
- Transforming unstructured text into structured data (using criterion-value pairs, e.g. model, year, colour as criterions for text relating to automobiles); expansion of indexing terms, e.g. with synonyms or spelling variants.
Attention is drawn to the following places, which may be of interest for search:
Extraction or weighting of terms for query translation | |
Extraction or weighting of terms for text summarization |
This place covers:
Creation or structuring of a physical index storing the information to be indexed together with a physical location.
Attention is drawn to the following places, which may be of interest for search:
Indexing structures for structured data |
Inverted lists often are used to index terms in a database. When these terms consist of text, these documents should be classified here and not in the G06F 16/22 (Database / building index) groups.
This place covers:
Documents disclosing hierarchical indexes.
Facets: Character strings in a text are stored hierarchically as keywords in an index file.
This place covers:
Implementation details of hash tables used for indexing textual documents.
This place covers:
Documents focussing on the automatic or manual management of an already existing index. This only comprises the organisation and not the modification or updating of index entries.
Facets:
- Compression of a text index
- Using a GUI to manage an index
This place covers:
Processing of retrieval requests for finding unstructured textual data matching a query.
This place covers:
- Aspects of query formulation for the retrieval of unstructured or raw text data, such as query recommendation.
- User interfaces for query formulation (including help systems therefor).
This place covers:
- Query formulation based on system suggestions, e.g. by using keywords, categories, etc. The user can decide whether to make use of these suggestions or not.
- Using (parts of) previous queries as suggestions for new queries.
- Using pre-stored categories for making system suggestions.
This place does not cover:
Query reformulation based on results of preceding query |
Attention is drawn to the following places, which may be of interest for search:
Natural language query formulation in dialogue systems | |
Automatic query expansion with no user interaction | |
Reuse of stored results of previous queries |
This place covers:
Interactive interfaces for formulating queries using a category hierarchy.
Attention is drawn to the following places, which may be of interest for search:
(Categorized) browsing without generating a query |
This place covers:
The user informing the system about the relevance (or non-relevance) of (some of) the results. This relevance information is used in reformulating the query.
Facets:
- Explicit feedback by the user.
- Evaluating implicit feedback, e.g. click through data.
- Pseudo-feedback (where no real relevance feedback from the user is received but the top-ranking documents are considered as being highly relevant).
This place covers:
Iterative refinement or modification of the query formulation based on a graphical display of the results.
Facets: Limiting the next query to certain documents by graphically selecting these documents in the result set (e.g. using a rectangle or lasso tool).
Example:
Text content: Making a standard keyword query and presenting the results in a 2D map by building feature vectors, mapping each information item to a point in the 2D map based on similarity. Choosing a query area in the 2D map, displaying the items belonging to the query area
This place covers:
Formulation of queries in natural language for querying unstructured data.
Attention is drawn to the following places, which may be of interest for search:
Character input using prediction techniques | |
Suggesting modifications to executable queries |
This place covers:
- Formulation of queries in natural language for querying unstructured data in dialogue systems, e.g. Q&A systems.
- Using a dialogue between the system and the user to establish an executable query.
- Natural language question-answering systems and methods wherein prefabricated answers are retrieved.
Q&A systems constructing an answer by mining knowledge from e.g. a text corpus are covered by G06N 5/00.
This place covers:
General aspects of processing queries.
This place covers:
Pre-processing the query to make it more suitable for query execution; it is typically done internally with no user interaction.
Attention is drawn to the following places, which may be of interest for search:
Modification of queries with user interaction |
This place covers:
Identifying or extracting important information (for the purpose of querying) from an input (query) text or a query.
Facets:
- Identifying keywords in a text (e.g. an SMS), a query is generated therefrom for retrieving a set of images illustrating the text.
- Identifying (spoken) keywords in a phone conversation used for querying a knowledge base.
- A user inputs a plurality of search terms, e.g. by copy and paste from a text. The system extracts the search terms that occur infrequently in the set of documents.
Attention is drawn to the following places, which may be of interest for search:
Feature extraction for indexing purposes |
This place covers:
Basic pre-processing steps like eliminating words useless for purposes of retrieval (stop word elimination) and reducing variants of the same root word to a common stem (stemming).
Attention is drawn to the following places, which may be of interest for search:
Lexical analysis |
This place covers:
- Translating queries in the native language of the user (e.g. Chinese) to the query language of the respective search engine (e.g. English).
- Translating English queries into Spanish equivalent for querying a Spanish index.
Attention is drawn to the following places, which may be of interest for search:
Language translation |
This place covers:
Automatically adding query terms to a given query/automatically reformulating the query.
Facets:
- Query expansion/reformulation based on semantic information stored in thesauri and/or ontologies; use of synonyms/hypernyms/hyponyms for query expansion/reformulation.
- Concept-based querying of a document database.
- Expanding a query using different spelling variants of query terms.
- A set of text documents is queried not only using the most recent user query but also using keywords extracted from the queries received since the last switch of query topic was detected.
Attention is drawn to the following places, which may be of interest for search:
Query expansion by the user based on system suggestions |
This place covers:
Methods used to calculate the degree of similarity between two entities (typically documents) or an entity and a query. These methods normally are used to rank query results.
Example: Degree-of-similarity score is calculated and reorganised into heap form to select the highest score.
This place does not cover:
Filtering based on additional data, e.g. user or group profiles |
This place covers:
Similarity calculated or estimated with boolean or extended boolean models.
This place covers:
Matching phoneme lattices of a query with phonemes of information annotated to the information to be retrieved.
This place covers:
Similarity that is estimated based on the semantic meaning of the query and the semantic meaning of every sentence in a document collection. For this purpose, the relation and associated sense of different parts of sentences (sub sentences, words or suffixes) to each other are analysed.
In some documents, the term ''natural language query'' that is often used for queries which are not really natural language based but a simple enumeration of query words connected by a logical AND (e.g. Google queries).
Facets:
Similarity that is calculated by creating and using a graph for every sentence where words are nodes and the relationship of the words is represented as links between the nodes.
Q&A systems constructing an answer by mining knowledge from a text corpus: G06N 5/00
Attention is drawn to the following places, which may be of interest for search:
Q&A systems matching natural language queries to prefabricated answers |
This place covers:
Ranking that is done on the probability that a retrieved document really comprises what the user is looking for. The sum of the probability that the document is important and the probability that the document is not important has to be one.
Facets:
Two content vectors are given; the probability that the first content vector is relevant to the second content vector is estimated using distributions of words.
This place covers:
Documents that are represented as content vectors in a vector space. Relevance of a query result is calculated by operations done in vector space.
Facets:
- Feature vector of a document is created comprising content vector, size of the font, date of publication and name of author.
- Document vectors that are formed from word vectors and compared to a query vector.
Feature vectors representing web pages including content vectors of the page should be double classified here and in the corresponding web group in G06F 16/95.
Attention is drawn to the following places, which may be of interest for search:
Use of previous queries for suggesting formulations of new queries | |
Reformulation of queries based on results of previous queries |
This place covers:
Filtering or routing of textual data based on additional information, e.g. user profiles, preferences, learned set of abstract rules or an explicit query provided by the user.
Facets: Composing personalized online newspapers based on user interests.
This place does not cover:
Search customisation based on user profiles and personalisation | |
Search customisation based on social or collaborative filtering |
This place covers:
Generation of the user profiles, either automatically or manually, and/or learning of the user preferences.
Facets: Different user profiles are analysed and compared to expand the profile of an individual user.
This place covers:
- Highlighting of search terms in the result set of a query.
- Visualizing the relevance of the query results showing the respective contribution of the individual query terms.
Attention is drawn to the following places, which may be of interest for search:
Presentation or visualization of query results integrated with query re-formulation | |
Browsing or Visualization without relation to a query, e.g. simply visualizing a document or document space | |
Clustered display of query results |
This place covers:
Mechanisms using non-textual data (e.g. graphical data) for the visualization of collections of text documents, single text documents and concepts of text documents. These mechanisms can be used for document browsing.
Facets:
- Highlighting important sentences in a text document.
- Creating a table of contents of a text document that can be used for browsing (eBook).
- A calendar-based user interface for date-based browsing of electronically stored documents.
This place does not cover:
Browsing or visualisation for clustering or classification |
Attention is drawn to the following places, which may be of interest for search:
Document space visualisation for the purpose of query formulation | |
Visualisation of query results | |
Document space presentation for browsing in web context |
This place covers:
Summarization of text content for presenting to a human user. Normally, important text fragments are extracted and presented to the user.
Facets:
- Summarization of text based on users focus.
- Summarization of a collection of related documents.
Attention is drawn to the following places, which may be of interest for search:
Extracting text features for indexing purposes |
This place covers:
- Automatic content-based text classification or clustering.
- Management of classes or clusters (GUI or machine based).
- Overviews of different content-based clustering or classification methodologies.
Example: A GUI based system to create/modify the names of classes in an existing classification tree.
Attention is drawn to the following places, which may be of interest for search:
Manual classification of textual data |
This place covers:
Classification or clustering into predefined classes or clusters. The existing classes or clusters may not be changed.
Documents that also should be classified in this group if they do not tell whether classes are created, modified or predefined.
Facets:
- Books are classified by their genre.
- Patent documents are classified into a patent classification scheme.
- A system that reclassifies all documents in a classification tree because the class definitions were changed.
This place covers:
Creation or modification of classes or clusters during the clustering or classification process.
Facets:
- Groups which become to big are divided by the system.
- If a document does not fit in any existing group and a new group is created for it.
- Clusters of words of a text are allocated.
Attention is drawn to the following places, which may be of interest for search:
Visualisation of query results, including e.g. in ranked clusters | |
Browsing or visualisation of unstructured textual data in general |
This place covers:
Creation (NOT THE USE) of structures that help in understanding the semantics of words.
This place covers:
Creation of Ontologies (concept/term networks, graphs, trees, etc.).
This place covers:
Creation of thesauri (dictionaries, synonym lists).
This place covers:
Techniques for usage of metadata for text retrieval. The metadata can be human generated or machine made and may be extracted out of text content.
Facets:
- Manual classification systems (such as patent classification schemes) should be classified in this group.
- All kinds of metadata, e.g. citations, barcodes, keywords, etc.
- Also generation of metadata.
- Keywords extracted and stored as additional data.
- Searching a document in a library using descriptive information, e.g. author, document state, archiving status, etc.
Attention is drawn to the following places, which may be of interest for search:
Extraction of Metadata for indexing purposes | |
Layout-based retrieval of text documents |
This place does not cover:
Retrieval of web documents by barcodes etc., e.g. encoding the URL |
Attention is drawn to the following places, which may be of interest for search:
Document management |
This place covers:
Retrieval of documents where the bibliographic data (metadata) is a citation to other document or documents.
Facets:
- CiteSeer, where documents cited/citing can be retrieved following the citation chain.
This place does not cover:
Hypermedia, including creation/management of hyperlinks |
Attention is drawn to the following places, which may be of interest for search:
Details of hyperlinks in HTML documents |
This place covers:
- Retrieval of media data incorporating multiple media types, e.g. slideshows comprising image and additional audio data.
- Retrieval of media data where the retrieval algorithm is suitable for various media types.
- Automatic creation of multi-media presentations or documents as a result of a query, e.g. slide-shows, multimedia playlists, multimedia albums comprising various media types such as images, text, audio clips, video clips, etc.
- Adaptation of multimedia formats, e.g. selection of multimedia formats based on the capabilities of a client.
- Generation of multimedia documents.
- Multimedia databases index structures and management thereof.
This place does not cover:
Retrieval of image data | |
Retrieval of audio data | |
Retrieval of video data |
Attention is drawn to the following places, which may be of interest for search:
Editing or indexing of data stored based on relative movement between record carrier and transducer |
In this place, the following terms or expressions are used with the meaning indicated:
Media type | The expression media type encompasses image data, audio data, video data and text data |
This place covers:
Specific indexing aspects, data structures or storage structures for multimedia data.
Attention is drawn to the following places, which may be of interest for search:
Indexing specially adapted for contents retrieved by relative movement between record carrier and transducer | |
Indexing by using information signals detectable on the record carrier and recorded by the same method as the main recording |
This place covers:
Processing details of multimedia retrieval requests.
Attention is drawn to the following places, which may be of interest for search:
Programed access in sequence to addressed parts of tracks of operating discs |
Attention is drawn to the following places, which may be of interest for search:
Interaction techniques for graphical user interfaces |
This place covers:
Query formulation using a piece of audio data as retrieval argument, such as a selected audio file, music, which is currently playing, speech input, or environmental noises.
Attention is drawn to the following places, which may be of interest for search:
Details of audio retrieval | |
Electrophonic musical instruments | |
Speech recognition | |
Speaker recognition | |
General determination or detection of speech characteristics |
This place covers:
Query formulation using a piece of image data such as a selected image file, a photograph, which currently is captured by the camera of the user, a document, a barcode or scanned text.
This place covers:
Wherein the retrieval is taking further parameters into account, such as user or group profile data for filtering the search space or the results.
This place covers:
Using biological or physiological metrics obtainable by monitoring the human body (e.g. heartbeat, pulse, body temperature, brain waves) or biometric techniques (e.g. fingerprint, iris or retina, face, voice or gait recognition) in formulation or personalisation of queries.
This place covers:
Techniques for modelling the changing interest of a user over time including manual, semi-automatic or automatic initialisation of user profiles, their maintenance and modification by monitoring the user's history of content selection, his history of interaction with the selected content, the management of the shared profile of a group of users, e.g. profile splitting or stereotyping.
This place covers:
Where invention information is present in the visual or acoustic presentation of the query results to the user.
Attention is drawn to the following places, which may be of interest for search:
Menu, index or table of content presentation of record carriers |
This place covers:
Methods or interfaces to create, modify or manage multimedia playlists.
This place covers:
Multimedia presentations of query results, e.g. slideshow presentations, photo albums enriched with multimedia content, e-books with multimedia content, etc.
This place covers:
Wherein a visual metaphor is provided for supporting the search process of the user, and wherein the retrieval is performed through arbitrary or guided browsing.
This place covers:
Using graphical representations of geographical, urban or virtual space, e.g. 2D or 3D maps, city plans, virtual spaces, as a paradigm for browsing representations of multimedia objects.
Attention is drawn to the following places, which may be of interest for search:
Interaction with 3D GUI environments in general |
This place covers:
Using graphical representations of time, e.g. timelines, calendars, diaries, as a paradigm for browsing representations of multimedia objects.
This place covers:
Automatic content-based multimedia document classification and clustering. Management of classes or clusters (GUI or machine based), overviews of different content-based clustering or classification methodologies.
This place covers:
Retrieval or indexing of multimedia data using metadata.
Note: Group G06F 16/48 concerns the use of metadata not derived from the multimedia content, or manually generated information, such as bibliographic information (e.g. title, composer, etc.), usage information, user ratings, tags etc.
These data may be generated by automatic annotation of multimedia data, generation from existing data sources, e.g. data mining, collaborative annotation, creation of semantic ontologies, tagging.
This place covers:
Retrieval or indexing of multimedia data using metadata that automatically is derived from the multimedia content.
Attention is drawn to the following places, which may be of interest for search:
Query formulation using audio data | |
Query formulation using image data |
This place covers:
Where the feature used for retrieval or indexing is any kind of absolute, relative or fuzzy representation of location, e.g. GPS coordinates, postal address, rooms of a building, user's car.
This place covers:
Where the feature used for retrieval or indexing is of any kind absolute, relative or fuzzy representation of time, e.g. hour, date, time of the day, season of the year, rush hour, sunset or holiday.
This place covers:
Systems and methods (1) for retrieving digital still images in databases or (2) related to how metadata of the image type is used to retrieve other information, possibly of a different type.
Attention is drawn to the following places, which may be of interest for search:
Retrieval of multimedia data | |
Pattern recognition | |
Image analysis, e.g. from bitmapped to non-bitmapped | |
ICT specially adapted for handling medical images, e.g. DICOM, HL7 or PACS | |
Digital picture intermediate information storage |
This place covers:
- Data structures for images or image database organisation.
- Aspects of accessing the images in the database to deal with bandwidth problems on the network or the computer, typically using caching or image interleaving.
- Specific indexing aspects.
Attention is drawn to the following places, which may be of interest for search:
Indexing specially adapted for contents retrieved by relative movement between record carrier and transducer |
This place covers:
Processing details of still image retrieval requests.
This place covers:
Wherein the contribution is in specific query formulation aspects, in particular graphical user interface supporting the user in specifying a graphical query.
Attention is drawn to the following places, which may be of interest for search:
Interaction techniques for graphical user interfaces |
This place covers:
Wherein the retrieval is taking further parameters into account, such as user or group profile data for filtering the search space or the results.
This place covers:
Presentation of the query results to the user.
This place covers:
Wherein a visual metaphor is provided for supporting the search process of the user, and wherein the retrieval is performed through arbitrary or guided browsing.
This place covers:
Automatic image classification and clustering. Management of classes or clusters (GUI or machine based), overviews of different content-based clustering or classification methodologies.
Attention is drawn to the following places, which may be of interest for search:
Clustering techniques for pattern recognition |
This place covers:
Vectorial images, which are typically used in CAD oriented databases.
Images also can be retrieved according to colours, shapes, etc. but the data structures are completely different as are the techniques of indexing/querying.
This place covers:
Indexing and retrieval of still image data using metadata.
This place covers:
Image databases relying on feature information (previously indexed or obtained on-the-fly) derived from the image data by automatic image analysis.
Attention is drawn to the following places, which may be of interest for search:
Feature extraction |
This place covers:
Where the information extracted by analysis is related to colours present in the image, e.g. histograms.
This place covers:
Text extracted from the still images, in opposition to text added from external sources or inputs, for retrieval.
Attention is drawn to the following places, which may be of interest for search:
Character recognition, recognising digital ink or document-oriented image-based pattern recognition |
This place covers:
Using recognized shapes or spatial relationships between objects/blocks of the images for retrieval.
This place covers:
Using texture descriptors for the retrieval.
This place covers:
Wherein the metadata used for retrieval has been generated manually, for example, human labels, tags, keywords, comments or manually entered time and location data (as opposed to automatically obtained time or GPS provided data).
This place covers:
Where the feature used for retrieval or indexing is any kind of absolute, relative or fuzzy representation of location, e.g. GPS coordinates, postal address, rooms of a building, user's car.
This place covers:
Retrieval of audio data from audio databases, e.g. retrieval of songs, by using content features or bibliographical data associated with the audio data.
Attention is drawn to the following places, which may be of interest for search:
Retrieval of general multimedia | |
Retrieval of video data | |
Electrophonic musical instruments | |
Speech recognition | |
Speaker recognition | |
General determination or detection of speech characteristics | |
Editing or indexing of data stored based on relative movement between record carrier and transducer |
This place covers:
Specific indexing aspects, data structures and storage structures for audio data.
Attention is drawn to the following places, which may be of interest for search:
Indexing specially adapted for contents retrieved by relative movement between record carrier and transducer g | |
Table of contents on a record carrier |
This place covers:
Processing details of audio retrieval requests
This place covers:
Wherein the contribution is in specific query formulation aspects supporting the user in inputting a query.
This place covers:
Formulation of the query predicate as an existing/example audio content, e.g. query by humming, or using a recorded piece of audio data as example.
This place covers:
- Filtering rules.
- Retrieval personalisation.
- Generation, learning, modification and use of user profiles.
- Monitoring of user activities for profile generation (in particular generation and use of reproduction/playback histories/logs).
- Relevance feedback.
This place covers:
Using biological or physiological metrics obtainable by monitoring the human body (e.g. heartbeat, pulse, body temperature, brain waves) or biometric techniques (e.g. fingerprint, iris or retina, face, voice or gait recognition) in formulation or personalisation of audio queries.
This place covers:
Techniques for modelling the changing taste of a user over time including manual, semi-automatic or automatic initialisation of user profiles, their maintenance and modification by monitoring the user's history of audio content selection, his history of interaction with the selected content, the management of the shared profile of a group of users, e.g. profile splitting or stereotyping.
This place covers:
Visual or acoustic presentation of the query results to the user.
Attention is drawn to the following places, which may be of interest for search:
Menu, index or table of content presentation of record carriers |
This place covers:
Methods presenting the results of query for audio data in form of a list which defines an order between the audio data used during the replay of the audio data, e.g. methods or interfaces to create, modify and manage audio playlists.
This place covers:
Browsing, e.g. a list or a collection/database of song titles or images or icons representing audio data. Such lists or sets of audio data representations may be the results of a querying operation. However, the contribution is the browsing method.
This place does not cover:
The generation of the list or set of audio data |
Attention is drawn to the following places, which may be of interest for search:
Trick modes | |
Browsing through audio recorded on operating discs |
This place covers:
Automatic audio classification and clustering. Management of classes or clusters (GUI or machine based), overviews of different content-based clustering or classification methodologies.
Attention is drawn to the following places, which may be of interest for search:
Clustering techniques for pattern recognition | |
Classification techniques for pattern recognition |
This place covers:
Indexing and retrieval of audio data using metadata.
Attention is drawn to the following places, which may be of interest for search:
Metadata derived by content-analysis | |
Programmed access in sequence to addressed parts of tracks of operating discs |
This place covers:
Retrieval and/or indexing methods using features derived from the audio content. This subgroup covers the mere use of audio content features in the context of audio data retrieval. This metadata comprises, for example, descriptors, fingerprints, signatures, MEP-cepstral coefficients, musical score, tempo.
Attention is drawn to the following places, which may be of interest for search:
Analysis and extraction of content specific audio features | |
Audio watermarking, e.g. by inserting fingerprints | |
Determination or detection of speech characteristics | |
Indexing by using information signals detectable on the record carrier and recorded by the same method as the main recording |
This place covers:
Text data used to retrieve audio content, e.g. text derived from speech or music, phonetic transcript, music scores (sheet music), etc.
This place does not cover:
Speech recognition |
This place covers:
Where the retrieval and/or indexing method uses manually generated information, e.g. data created by humans and added to the audio data at a post-production phase by manual annotation/tagging, e.g. title, song writer, interpret, users' tags, comments or annotations etc.
This place covers:
Where the feature used for retrieval or indexing is any kind of absolute, relative or fuzzy representation of location, e.g. GPS coordinates, postal address, rooms of a building, user's car.
This place covers:
- Video retrieval using content features.
- Video retrieval using bibliographical data.
- Details or video query formulation and video query processing.
- Browsing videos and the internal structure of videos.
- Presenting video query results.
- Video database index structures and management thereof.
Video data model used in this group: the structure of this group relies on the following data model of video. Video content is the originally produced data comprising:
- The visual data (video frames).
- Accompanying audio track(s).
- Original textual content (typically subtitles, which can be coded and stored/transmitted either in binary/visual format or in textual format). Whatever data is added to video later, e.g. at a post-production phase, is referred to as bibliographical data or metadata.
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
Video data retrieval specially adapted for selective content distribution, e.g. interactive television or video on demand [VOD] |
Attention is drawn to the following places, which may be of interest for search:
Retrieval of multimedia | |
Image retrieval | |
Audio retrieval | |
Recognising patterns | |
Image analysis | |
Editing or indexing of data stored based on relative movement between record carrier and transducer, e.g. video data | |
Source coding or decoding of digital video signal |
This place covers:
Specific indexing aspects, data structures or storage structures for video data.
Attention is drawn to the following places, which may be of interest for search:
Indexing specially adapted for contents retrieved by relative movement between record carrier and transducer | |
Table of contents on a record carrier |
This place covers:
Processing details of video retrieval requests.
This place covers:
Query formulation and processing for the retrieval of video data.
This place covers:
Formulation of the query predicate as an existing/example of video content, e.g. a video sequence or its excerpt/clip; typically a content-based descriptor computed from said example content during query processing; if there is contribution in the usage of a particular content feature or metadata, this should be classified under a relevant G06F 16/78 subgroup, respectively; if there is a contribution in a particular content feature extraction, characterisation or analysis, this should be classified under the relevant G06F 18/00, G06V or G06T 7/00 subgroup(s).
This place does not cover:
Graphical querying |
This place covers:
Graphical user interfaces [GUIs] for specifying graphical query predicates interactively (a mere selection of an example video sequence as a query predicate shall be classified in G06F 16/7328). These GUIs may for example allow a specification of sought-for regions, to sketch a desired scene, a trajectory, or to designate a person, a face or an object as query predicate.
This place does not cover:
End-user interface involving hot spots associated with the video | |
End-user interface for selecting a Region of Interest |
Attention is drawn to the following places, which may be of interest for search:
Query by an example video sequence |
This place covers:
Query formulation using a specific query language or format of the query, e.g. SQL variants adapted for video or specific formats for expressing query parameters.
This place covers:
- Filtering rules.
- Retrieval personalisation.
- Generation, learning, modification and use of user profiles.
- Monitoring of user activities for profile generation (in particular generation and use of reproduction/playback histories/logs).
- Relevance feedback.
- Playlist-based retrieval and playlist generation.
Attention is drawn to the following places, which may be of interest for search:
Recommending movies involving learning viewer preferences | |
Creating a personalised video channel | |
Monitoring the number of times a movie has been viewed | |
Monitoring of user selections, e.g. selection of programs |
This place covers:
Presentation of query results, in particular visual presentation methods/interfaces.
Attention is drawn to the following places, which may be of interest for search:
Presentation in form of a video summary | |
Browsing a video collection | |
Two dimensional image generation |
This place covers:
- Video summarisation, also called video abstraction, which produces a shorter and/or more condensed version of the original video. For example, video skimming produces a shorter video sequence at the output, typically comprising a subset of key frames extracted from the original video or a subset of excerpts / sub-sequences of the original video.
- Composite still images (2-D or 3-D), called,for example, a video mosaic, storyboard, video poster or "movie bar", typically comprising re-sized key-frames extracted from the original video, arranged into the still image like in a comic book or like stones in a mosaic.
- Video sequences comprising artificial (synthesized) frames, e.g. with an artificial (synthesized) view not existing in any of the single frames of the original video, with a stitched panorama showing a broader view and/or more motion than any single original frame or with a view having overlaid multiple instances of the same moving object.
Attention is drawn to the following places, which may be of interest for search:
Two dimensional image generation |
This place covers:
- Browsing a plurality of video files/sequences in a video collection/database.
- Browsing the internal structure of a single video sequence.
- Systems and methods for hyperlinking in hypervideo.
This place does not cover:
End-user interface for requesting or interacting with video content, e.g. video on demand interface or electronic program guides |
Attention is drawn to the following places, which may be of interest for search:
Indicating arrangements in the context of indexing and addressing recorded information |
This place covers:
Browsing a plurality of video files/sequences in a video collection/database, e.g. using thumbnails, (moving) icons, cover art, etc.
This place covers:
Browsing the internal structure of a single video sequence, e.g. browsing by jumping between shots, scenes, objects or events in the content of the sequence.
This place covers:
- Systems and methods for hyperlinking in hypervideo.
- Computed links, including dynamically determined anchor and targets of links.
- Management of annotations linked to other documents.
This place does not cover:
Linking data to content, e.g. by linking an URL to a video object in the context of video distribution systems |
This place covers:
Automatic video classification and clustering. Management of classes or clusters (GUI or machine based), overviews of different content-based clustering or classification methodologies.
Attention is drawn to the following places, which may be of interest for search:
Clustering techniques for pattern recognition | |
Classification techniques for pattern recognition |
This place covers:
Indexing and retrieval of video data using metadata
Attention is drawn to the following places, which may be of interest for search:
Use of information derived by content analysis |
This place covers:
- Retrieval and/or indexing methods using features derived from the video content.
- Retrieval using video signatures/fingerprints based on statistical/probabilistic methods or hashing algorithms.
Attention is drawn to the following places, which may be of interest for search:
Extraction of features or characteristics for pattern recognition of the image | |
Recognising video content |
This place covers:
Using features of the audio track of the video content, e.g. where query predicate(s) are in audio format (e.g. query-by-speech, query-by-music) or where retrieval or indexing uses low-level audio features (e.g. using magnitude/energy analysis, using speaker recognition methods).
Attention is drawn to the following places, which may be of interest for search:
Contents oriented musical parameter indexing, e.g. tempo | |
Speech recognition | |
Speaker recognition | |
General determination or detection of speech characteristics |
This place covers:
Where the feature used for retrieval or indexing is a detected or recognised object.
Attention is drawn to the following places, which may be of interest for search:
Methods for image acquisition of a pattern to be recognized involving target detection |
This place covers:
Where the features used for retrieval or indexing are detected or recognised people, e.g. faces.
Attention is drawn to the following places, which may be of interest for search:
Human body recognition | |
Face recognition | |
Speaker recognition |
This place covers:
Retrieval of video data by using metadata automatically derived from the content such as:
- Textual content (part (3) of the video content according to the video data model - see note of G06F 16/70), e.g. the original subtitles (closed captions) transmitted in textual-format as part of the video stream or
- Extracted text from the video frames or from binary visually-coded subtitles (closed captions) or
- Text derived from speech or music, phonetic transcript, music scores (sheet music), etc.
Attention is drawn to the following places, which may be of interest for search:
Extraction of overlay text |
This place covers:
- Usage of low-level visual features extracted from the video content for video indexing and retrieval.
- Examples of descriptors range from a single value or a histogram of a particular low-level feature to a complex/statistical descriptor based on one or more features, e.g. video signature/fingerprint.
- Usage of particular low-level visual features should be classified in one or more of the subgroups.
Attention is drawn to the following places, which may be of interest for search:
Image processing in general | |
Methods for preprocessing an image in order to extract features of a pattern to be recognized | |
Recognising video content |
This place covers:
Using colour or luminescence as the low-level visual feature for querying.
Attention is drawn to the following places, which may be of interest for search:
Colour analysis on image data |
This place covers:
Using detected shapes as the low-level visual feature(s) for querying, e.g. based on a detected sketched shape drawn by the user.
This place does not cover:
Using objects detected or recognised in the video content |
This place covers:
Using texture as the low-level visual feature.
This place does not cover:
Using objects detected or recognised in the video content |
This place covers:
Using a motion feature, e.g. motion vector(s), as the low-level visual feature.
Attention is drawn to the following places, which may be of interest for search:
Motion analysis |
This place covers:
Using features of a specific domain transform as the low-level visual features, e.g. wavelet or Discrete+ Cosine Transform (DCT) transform coefficients; this approach is often referred to as retrieval or indexing "in compressed domain".
This place covers:
Retrieval and/or indexing methods using information not-derived from the video content, e.g. data created by humans and added to video at a post-production phase by manual annotation/tagging, e.g. title, author, director, actors' names, users' tags, comments, annotations, usage information, user ratings etc.
This place covers:
Retrieval or indexing where the features used are any kind of absolute, relative or fuzzy representations of location, e.g. GPS coordinates, postal address, rooms of a building, user's car.
This place covers:
Semi-structured data, which is a form of structured data that does not conform with the formal structure of data models associated with relational databases or other forms of data tables, but nonetheless contains tags or other markers to separate semantic elements and enforce hierarchies of records and fields within the data.
This place does not cover:
Content-based retrieval of web data |
Attention is drawn to the following places, which may be of interest for search:
Web site document structures and storage, e.g. HTML extensions | |
Use of codes for handling textual entities |
This place covers:
Creation or maintenance of an index comprising tag (structure) and content information that is used to retrieve information in semi-structured documents.
This place covers:
Assembly, generation and maintenance of semi-structured (xml) databases as well as operations performed on semi-structured (xml) databases. Querying of said databases is also encompassed (XQuery etc.).
This place covers:
Example:
- Comparative analysis of XML query languages; graphical XML query language.
This place covers:
Examples:
- Implementing an XML query language.
- Query processing in Xyleme - a native XML DBMS.
- Implementing an XML query language.
This place covers:
- Translation of a query into internal representation.
- Translation of XML specific query language into SQL as internal representation.
This place covers:
Example:
- XML query (XQuery) optimization and normalization.
This place covers:
Execution of one or more (already generated and optimized) query execution plan(s).
Examples:
- Pipelined query execution of a ranking operator for XQuery.
- Intra-document indices to improve XQuery processing over XML streams.
This place covers:
Mapping or conversion of semi-structured documents to other structures.
This place covers:
Mapping of semi-structured documents to databases (relational, object oriented, etc.).
This place covers:
Normalisation or conversion of semi-structured documents into another semi-structured scheme.
This place does not cover:
Conversion for visualization in web browsing |
This place covers:
- Retrieval of information, wherein the retrieval method is not related to any particular type of data, in particular if no specific data type is indicated or implied by the context of the document at all, or an explicit hint is given that the disclosed mechanism can be used for retrieval of arbitrary data types.
- Retrieval from the web.
This place covers:
Details about data structures for storage and indexing of generic data, independent of its type.
This place does not cover:
Storage and indexing structures for retrieval from the Web |
Attention is drawn to the following places, which may be of interest for search:
Storage and indexing structures for databases wherein the data type of the retrieved information can be identified as structured |
This place covers:
Retrieval of data by calculating a storage address, for example in a table, file or main memory from a given key, or converting somehow this key to that storage address; for example using a hashing function to map an information key to the address where that information is stored.
Attention is drawn to the following places, which may be of interest for search:
Accessing data in main memory systems with address translation involving hashing techniques | |
Routing in networks, hashing functions for network address lookup |
This place covers:
Systems, methods for managing data structures such as data graphs, linked lists, being specifically adapted for accessing of index data accessible in a chained manner, e.g. including some form of pointers from one index record to one or more other index records.
This place does not cover:
Trees |
This place covers:
- Details of implementation in memory of the tree structures, compact representations.
- Techniques to re-balance trees after updates (e.g. insertions or deletions).
- Extensions to basic tree structures to offer alternative navigation paths through the trees.
Attention is drawn to the following places, which may be of interest for search:
Management of index trees for structured data stores | |
Management of index trees for unstructured text data |
This place does not cover:
Querying for retrieval from the web |
This place covers:
- While inputting a query, the system predicts the most probable next query words and displays a list for the user to choose from using the mouse.
This place covers:
- Use of Content Addressable (CAM) or Parallel Associative Memories (PAM) to match search arguments with a large number of elements in parallel.
- Architecture making use of CAM units for speeding up retrieval.
Attention is drawn to the following places, which may be of interest for search:
Internal architecture of CAM, PAM | |
Use of CAM for routing and flow control of packets in data switching networks |
In this place, the following terms or expressions are used with the meaning indicated:
CAM | Content Addressable Memory |
PAM | Parallel Associative Memory |
This place covers:
Retrieval of data by using string matching, e.g. using finite state machines or genetic algorithms.
Attention is drawn to the following places, which may be of interest for search:
Orthographic correction | |
Sequence comparison in bioinformatics | |
String matching used for packet routing in packet switching systems |
This place covers:
Searching dictionaries or (alpha-numerically) ordered lists; includes taking advantage on the ordering for binary or simple sequential access.
Attention is drawn to the following places, which may be of interest for search:
Sequence comparison in bioinformatics |
This place covers:
- Navigating/Browsing a set of generic items (consumer products, homes, wallpaper patterns) using operations like ''more of this'' and ''less of that''.
- 3D-based approach of browsing through data items corresponding to files or folders.
This place does not cover:
For navigating the web | |
Browsing optimisation for the web |
Documents describing retrieval of arbitrary data types based on a specific type of metadata in addition may be classified in the group corresponding to the data type used for the retrieval, depending on the level of disclosed details concerning the data type used for retrieval.
This place covers:
- Organisation of collections of digital documents (scanned, OCRed, semi-structured or unstructured representation) in document library databases.
- Retrieval of digital representations of documents.
- Techniques for associating physical paper documents with their digital representation as stored in a database, e.g. by attaching barcodes to documents.
Attention is drawn to the following places, which may be of interest for search:
Retrieval of unstructured textual data | |
Retrieval of image data | |
Retrieval of semi-structured data |
This place covers:
- Systems and methods for hyperlinking in documents.
- Computed links, including dynamically determined anchor and targets of links.
- Management of annotations linked to other documents.
This place does not cover:
Hyperlinking |
Attention is drawn to the following places, which may be of interest for search:
Navigation in hyperlinked Web environments |
This place covers:
- Systems and methods for browsing and retrieving information on the web.
- Aspects in subgroups that deal with search engines specifics (e.g. crawling, indexing, search personalisation), web navigation, web site management (e.g. content collection, organisation and management of web sites, publication of same) and browsing optimisations (e.g. for quicker access or adequate visualisation).
Close relationship with H04L 65/40 and H04L 67/00, especially due to particulars in OSI model's level 7: application layer.
Attention is drawn to the following places, which may be of interest for search:
Web site advertisement | |
Cryptographic protocols; Financial cryptography | |
Routing of packets, address resolution in data networks | |
Network security protocols | |
Protocols for real-time services in data packet switching networks | |
Network protocols for data switching network services | |
Implementation or adaptation of Internet protocol [IP], of transmission control protocol [TCP] or of user datagram protocol [UDP] |
This place covers:
- Systems and methods for collecting, organising or managing indexation of information originating from more than one data source in order to support keyword based searching.
- Web retrieval techniques dealing specifically with the nature of the web:
- Heterogeneity of data, users and devices.
- Large number of documents and users.
- Lack of detailed knowledge about the data sources.
- Specific web retrieval techniques such as:
- Crawling techniques to discover/navigate sites and document hyperlinks.
- Meta-search engines:
- Remote systems interactions for web retrieval purposes, e.g. distributed and remote indexing of web content.
- Handling documents in different languages.
Attention is drawn to the following places, which may be of interest for search:
Text content indexation |
Local, keyword-based search engines should be classified in the appropriate subgroups according to the retrieved type of data; for example, if dealing with: unstructured text, see G06F 16/30.
This place covers:
- Techniques to select the information conveyed to the user during his retrieval session, usually in complement to an explicit user query request.
- Personalisation of queries and/or of returned results.
Facets which include:
- Censoring by filtering documents (e.g. by keyword or objectionable images).
- Using inclusive/exclusive lists of sites/pages to define viewable content.
- Sharing user profile knowledge or identifying common interests to identify relevant information.
- Systems using a single user profile to filter information or enhance query.
- Aggregation of information (personalised online newspapers).
- User navigation monitoring to identify user interests and consequent query refinement.
Attention is drawn to the following places, which may be of interest for search:
When censoring comprises modifying the content | |
Filtering pages containing malware, virus or phishing attempts | |
Recommendation not directed at the retrieval of documents, but rather to items for sale, or "friends" (e.g. social matchmaking) | |
Personalisation for targeted marketing or advertisement |
This place covers:
- Methods and systems where the client accessing a web site conveys somehow localization or temporal information that is used then to personalise queries and/or results.
- Methods and systems where web content indexation involves localization information (spatial information).
- Integration of geographic (spatial) information in Web pages with other information.
Attention is drawn to the following places, which may be of interest for search:
Messaging using geographical location information | |
Network protocols in which the network application is adapted for the location of the user terminal | |
Services or facilities specially adapted for wireless communication network making use of the locations of the users |
This place covers:
- Interactive ways to help the user in recognising desired information in web sites/web pages.
- Methods and systems to help an interactive navigation within the document space on the web, in a search narrowing approach, including providing suggestions of pages to visit which appear relevant to the user's search path.
- Methods and systems whereby visual cues typically are provided to show existing relationships among documents or to provide a document space visualisation.
- Passive browsing, guided tours, wherein a list of web pages to visit is prepared in advance or automatically devised.
Examples:
- Methods can be based on a classification or clustering approach to organise the documents.
- Categorised browsing, portals, virtual worlds' tours or visual networks of documents.
- Using a query to select a starting point for navigation, showing how the returned documents relate to each other.
Attention is drawn to the following places, which may be of interest for search:
Document hyperlinking per se, computed links | |
Returning a document set as a result of a query |
This place covers:
Cases where the user already has an identifier for the information he wants to retrieve. Typically, the identifier is a product code or a bookmark. The general idea is that the user does not have to blindly search for the information.
This place covers:
- Use of a barcode reader (e.g. to read a UPC code or even a URL printed on a product) connected to a computer with a browser which fetches the relevant information on the Internet.
- Also systems wherein the user inputs the product code directly in a browser link field.
Facets:
- The code can be a direct URL or one that needs to be first resolved in an intermediary server.
- The code can further comprise commands or information used for personalising the search.
Attention is drawn to the following places, which may be of interest for search:
Details of bar codes and readers per se |
This place covers:
- Details of hyperlinking in hypertext.
- Computed links, including dynamically determined anchor and targets of links.
- Management of annotations linked to other hypertext.
Attention is drawn to the following places, which may be of interest for search:
Navigation in hyperlinked web environments |
This place covers:
- Methods and systems whereby the browser bookmarks are used to reference, organise, classify and access information.
- Local or central bookmark storage, managed by an individual or an organisation.
- Related management functions such as: replace in bulk, share bookmarks, detect broken links, add comments for later reference, extract from files, enhance visual aspect (e.g. icons, colours for easier recognition), automatic extraction (from pages), classification, etc.
In this place, the following terms or expressions are used with the meaning indicated:
Bookmarks | Represent information already identified as relevant for the user; they are user oriented and they represent information of interest already identified. |
Portals | Present a way for information yet to be discovered, and they are not specific to a user. |
This place covers:
- Variations of URLs in order to facilitate or simplify the access to the information (e.g. alias in non-Latin characters, tiny URLs).
- These URLs can refer to existing documents but also to virtual pages created at access-time or accessing transparently other links.
Attention is drawn to the following places, which may be of interest for search:
Address allocation to terminals or nodes connected to a network | |
Use of aliases or nicknames in arrangement for managing network naming | |
Addressing or naming in networks with short addresses |
This place covers:
Optimisations in the browsing process concerned with faster or simpler access to information.
Improvements that enhance or simplify the understanding of data or the visualization of data on the user's device. These include among others:
- Identifying changes in pages or sections of pages.
- Combined printing of web documents; for example, several web pages forming a single document.
- Combined access to CD-ROM information with internet browsing.
- Using specific data viewers (e.g. Mime dependent).
- In general, improvements with the browsing process.
Attention is drawn to the following places, which may be of interest for search:
Voice browsers, e.g. interpreting VoiceXML, for providing telephonic information services |
This place covers:
- Ways to speed up access to information on the Internet, typically, via caching and/or prefetching.
- Content dissemination systems.
- Look-ahead (Web) caching.
- Caching static and/or all of portions of dynamic data.
- Caching or hoarding of Web content on local removable storage (CDs, DVDs, USB keys) for later browsing.
Attention is drawn to the following places, which may be of interest for search:
Accessing, addressing or allocating within memory systems and caches | |
Network arrangements for storing temporarily data at an intermediate stage, e.g. caching |
The type of caching referred to in this group usually occurs at an application level; it is content aware, meaning that the system has some knowledge about the data content and will decide what and how to cache it based on this content.
This is opposed to system level caching, where the data content is transparent to the cache.
This place covers:
- Methods and systems manipulating web page content (e.g. HTML) for the purpose of changing the presentation of a page, in order to enhance the comprehension or visual rendering of its content.
- Adapting content for providing support to devices with various displays (e.g. PDA small screen).
- Reorganizing or simplifying the page layout.
- Using user profiles or templates to create or change the page presentation.
Attention is drawn to the following places, which may be of interest for search:
Web page authoring | |
Manipulation for advertisement or marketing purposes | |
Message adaptation based on network or terminal capabilities | |
Protocols for network applications adapted for terminals or networks with limited resources and for terminal portability | |
Arrangements for conversion or adaptation of application content or format |
While the manipulation of navigation items in a Web page (e.g. hyperlinks) to simplify browsing (for example associating a visible numerical code to links on a page and allowing keying in the code instead of activating the link with a pointer device) pertains to this group, document navigation techniques themselves should be classified in G06F 16/954.
May also include simple cases of document summarisation (priority to G06F 16/30) as long as the goal is page visualisation and not to be used for the purpose of document indexation. Typically uses an HTML parser (for parsing techniques used in software development see G06F 8/427). Format conversions not presentation dependent or related are classified in G06F 16/1794.
In this place, the following terms or expressions are used with the meaning indicated:
Distillation | Process of reducing the amount of information before delivery, in particular to eliminate information which cannot be rendered on the end device (colour on a black and white screen or downscaling of images in a Web page for a small screen) |
This place covers:
Organisation or management of web sites: how data is collected, stored and organised in a server, and how the information is published (e.g. dynamic web page servers) and made available or sent to users such as:
- Creation of site maps
- Registration of sites/pages in search engines
- Link organisation and maintenance
- Push channels, syndication and subscription systems
- Web CMS (Content Management Systems) repositories
Attention is drawn to the following places, which may be of interest for search:
Web page authoring |
In this place, the following terms or expressions are used with the meaning indicated:
ASP | Active Server Page: Microsoft Tool for dynamically serving Web pages |
JSP | Java Server Page: Java tools for dynamically serving Web pages |
This place covers:
- Documents concerned with technologies to support the access to data in proprietary or legacy systems from the Internet.
- Systems and methods to translate, offline or on the fly, proprietary formats to the open standards of the Internet.
- Dynamic page creation from legacy system.
Attention is drawn to the following places, which may be of interest for search:
File format conversion | |
Tree transformation in markup documents, XSLT |
This place covers:
- The way documents are represented and their structures are used.
- Extensions to or special uses of the HTML coding language.
This place covers:
Algorithms for:
- performing complex mathematical operations (e.g. matrix-vector multiplication G06F 17/16, discrete Fourier transform G06F 17/141);
- solving generic mathematical problems (e.g. system of linear equations G06F 17/12);
- manipulating mathematical objects (e.g. matrix factorization G06F 17/16);
evaluating complex mathematical functions (e.g. by interpolation of known function values G06F 17/17);
- computing statistical descriptions of data sets (e.g. histogram computation G06F 17/18)
- mathematical analysis of data not provided elsewhere (e.g. mathematical spectral analysis algorithms based on the discrete Fourier transform G06F 17/141)and the implementation of such algorithms
- as computer programs (for general-purpose digital processors), eventually with specially adapted data structures for storing the mathematical objects upon which the operations are performed (e.g. specific matrix storage formats), or
- as dedicated digital hardware circuits, described on the level of adders, subtractors, multiplexers, etc.
The groups in G06F 17/10 are function-oriented and are intended to cover mathematical methods and devices which are in principle not tied to a particular application field.
To be classified in G06F 17/10 and subgroups, a document should not merely disclose how a (technical) problem in an application field is reduced to a particular mathematical problem (e.g. a particular set of equations) but it must also disclose details of the mathematical algorithm used to solve this particular mathematical problem. Furthermore, the mathematical problem and/or the mathematical algorithm used to solve it should also be sufficiently generic in the sense that they may be relevant outside the particular application field (even if this fact is not mentioned in the document itself).
Subject-matter classified in group G06F 17/10 itself (because it does not fall in any of the subgroups) includes among others:
- Numerical computation of the derivative of a function;
- Numerical integration of a function, e.g. Using monte-carlo methodology;
- Methods enabling symbolic mathematical calculations, e.g. In computer algebra systems;
- Graph algorithms not classified elsewhere.
When a document discloses a mathematical algorithm applied in a particular application field, classification in the relevant application-related group(s) should also be considered.
This place does not cover:
Function generation working, at least partially, by table look-up | |
Computational arithmetic, e.g.number representation systems (e.g. conversion between number formats, rounding issues in fixed-point / floating-point arithmetic)implementation of arithmetic operations (addition, subtraction, multiplication, division), also for complex numbers (e.g. using CORDIC) | |
Evaluation of elementary functions (e.g. trigonometric functions, power, roots, logarithmic and exponential functions) by calculation | |
Arithmetic circuits for sum of products per se, e.g. multiply-accumulators (MACs) | |
Arithmetic logic units (ALUs) | |
Generation of random or pseudo-random numbers | |
Digital differential analysers | |
Computational residue arithmetic, e.g. modular inversion or exponentiation;computational elliptic curve arithmetic | |
Basic logic circuits (e.g. AND, NAND, OR) |
Attention is drawn to the following places, which may be of interest for search:
Pattern recognition | |
Computer-aided design and simulation | |
Reservoir modelling | |
Geophysics, seismic data analysis | |
Neural networks | |
Genetic algorithms | |
Computer systems using knowledge base models | |
Computer systems based on specific mathematical models | |
Probabilistic networks, e.g. Bayesian networks | |
Using fuzzy logic | |
Image processing | |
Digital filters | |
Data compression in general | |
Coding/decoding in general | |
Decoding based on Viterbi algorithm |
A document disclosing a device which is configurable to perform several complex mathematical operations (e.g. a circuit configurable to perform either a DFT or a convolution operation) is to be classified in the relevant groups (G06F 17/141 and G06F 17/15) if the document discloses details of the computations which are specific to the different mathematical operations. However, if no such details are provided, the document is to be classified only in the broadest group covering these operations. For example, a document disclosing a circuit able to perform any linear transform, including DFT and DCT, without providing details specific to the DFT or DCT computations, is to be classified only in G06F 17/14.
This place covers:
- Solving non-linear equations (e.g. By iterative methods)
- Mathematical algorithms for solving general mathematical optimization problems (e.g. Linear, non-linear, mixed-integer or combinatorial optimization problems)
The use of mathematical optimization to solve a problem in an administrative, business or logistic context is usually classified in G06Q 10/04. However, if the document provides also details regarding the mathematical algorithm used for solving the resulting mathematical optimization problem and if the mathematical optimization problem and/or the mathematical algorithm are sufficiently generic (i.e. if they may be relevant outside the particular application context), the document should also be classified in G06F 17/11.
Attention is drawn to the following places, which may be of interest for search:
Computer-aided design, e.g. circuit design, network design | |
Dynamic search techniques, heuristics, branch-and-bound used in computer systems utilising knowledge based models | |
Optimization specially adapted for a specific administrative, business or logistic context |
This place covers:
Methods for solving systems of linear equations Ax=b, e.g. by direct or iterative methods.
Details of matrix factorization algorithms or matrix storage formats used in the context of a specific method for solving a system of linear equations are additionally classified in G06F 17/16 if they are per se relevant.
This place covers:
- Solving ordinary or partial differential equations.
- Qualitative analysis of dynamical systems, e.g. Determining attractors.
This place does not cover:
Solving differential equations using digital differential analysers |
Attention is drawn to the following places, which may be of interest for search:
Computer-aided design | |
Simulation using finite difference or finite element methods | |
Adaptive control systems | |
Creation and adaptation of a mathematical model used to control a system |
This place covers:
- Efficient computation of domain transforms
- By extension, G06F 17/14 and its subgroups (in particular G06F 17/141 and G06F 17/148) do also include
- General mathematical algorithms for spectral analysis based on a domain transform (e.g. a method for DFT resolution enhancement by zero-padding is classified in G06F 17/141)
- Domain transforms not covered by its subgroups, e.g. Laplace, Hilbert or Karhunen-Loève transforms. It does also cover devices enabling computation of broad classes of domain transforms.
This place does not cover:
Correlation function computation using a domain transform | |
Spectral and Fourier analysis devices, e.g. digital spectrum analysers, in which the focus is on the electrical signal measurement apparatus and not on a mathematical spectral analysis algorithm | |
Frequency selective networks using specific transformation algorithms |
This place covers:
- Discrete Fourier Transform (DFT) computation, e.g. partial DFT, Goerzel method, recursive DFT computation, short-time DFT
Fast Fourier Transform (FFT) and Prime Factor algorithms for computing the DFT and corresponding devices are classified in subgroups.
By extension, G06F 17/141 also includes:
- general mathematical algorithms for spectral analysis based on the DFT, e.g. DFT resolution enhancement by zero-padding
Attention is drawn to the following places, which may be of interest for search:
Multi-carrier modulation systems | |
Inverse Fourier transform modulators | |
IFFT/IDFT in combination with other circuits for modulation | |
Fourier transform demodulators |
This place covers:
- DFT computation by means of a Fast Fourier Transform (FFT) algorithm, e.g. Cooley-Tukey or mixed-radix type
- processing elements specially adapted for FFT butterfly operations
- memory addressing schemes specially adapted for FFT computation
This place covers:
- prime factor algorithm (PFA) or Good-Thomas algorithm
- Winograd Fourier transform algorithm (WFTA)
Attention is drawn to the following places, which may be of interest for search:
Direct-sequence spread-spectrum techniques, e.g. CDMA |
This place covers:
- Discrete Cosine Transform (DCT)
- Discrete Sine Transform (DST)
- Modified Discrete Cosine Transform (MDCT)
- Integer transforms approximating the DCT, e.g. IntDCT
This place does not cover:
Square transforms, e.g. Hadamard transform |
Attention is drawn to the following places, which may be of interest for search:
Coding or decoding of speech or audio signals | |
Discrete cosine transform modulators in multi-carrier modulation systems | |
Transform-based video coding | |
The transform being DCT |
This place covers:
- Fast Wavelet Transform.
- Integer Wavelet Transform.
Attention is drawn to the following places, which may be of interest for search:
Transform-based video coding, the transform being sub-band based, e.g. wavelets |
This place covers:
- Correlation computations, e.g. Sliding correlation, cross-correlation, auto-correlation
- Convolution operations
This place does not cover:
Arithmetic circuits for sum of products per se, e.g. multiply-accumulators (MACs) |
Attention is drawn to the following places, which may be of interest for search:
Pattern recognition | |
Convolution neural network | |
Digital filters, e.g. FIR, IIR, adaptive filters | |
Direct-sequence spread-spectrum techniques, e.g. CDMA |
This place covers:
FFT-based correlation and convolution.
This place covers:
- Matrix-matrix multiplication
- Matrix-vector multiplication
- Vector product, dot product computation
- Matrix inversion
- Matrix factorization, e.g. Svd, lu, qr, cholesky decompositions
- Matrix storage formats, e.g. For sparse matrices
- Software and hardware implementations thereof, e.g. a systolic array specially adapted for QR decomposition.
This place does not cover:
Matrix transposition |
Attention is drawn to the following places, which may be of interest for search:
Arrangements for executing machine-instructions | |
To perform operations on data operands, e.g. arithmetic instructions | |
Concurrent instruction execution using a plurality of independent parallel functional units, e.g. SIMD, MIMD | |
Architecture of general-purpose stored program computer | |
Reconfigurable architectures | |
Architectures comprising an array of processing units, e.g. single instruction multiple data (SIMD) processors | |
Systolic arrays | |
Vector processors | |
Solving simultaneous equations, e.g. systems of linear equations |
This place does not cover:
Evaluating statistical data, e.g. function fitting based on least-mean squares method | |
Interpolation for numerical control |
Attention is drawn to the following places, which may be of interest for search:
Digital function generation working, at least partially, by table look-up; reduction of look-up table size |
Attention is drawn to the following places, which may be of interest for search:
Geometric Image transformation, e.g. interpolation-based scaling |
This place covers:
- Computing the (running) average of a set of data.
- Computation of confidence intervals.
- Computing a probability density function, e.g. An histogram, for a set of data.
- Regression analysis, e.g. Least-mean square methods for fitting a function to statistical data.
- General statistical analysis methods not covered elsewhere.
This place does not cover:
Computing the maximum, minimum or median value of a set of data |
Attention is drawn to the following places, which may be of interest for search:
Pattern recognition using clustering techniques | |
Forecasting specially adapted for a specific administrative, business or logistic context | |
Bioinformatics | |
Healthcare informatics |
This place covers:
Logging and acquisition of digital data.
Data logging, the act of storing and possibly organising collected data in such a way that some (temporal) ordering between the data is kept.
Log processing that is independent of the semantics of the log content.
In case the representation of the data is changed during the act of storing, this change process is considered data conversion. Data conversion in general, i.e. whereby the same information is represented with a different sequence or number of digits is classified in H03M 7/00.
This place does not cover:
Input arrangements for transferring data to be processed into a form capable of being handled by the computer |
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
Error or fault reporting or storing in computer systems | |
Logging of test results | |
Monitoring of computer systems | |
Flight recorders and related data acquisition | |
Storage of video surveillance data | |
Arrangements monitoring consumption of a utility or use of an appliance which consumes a utility to detect unsafe condition, e.g. metering of water, gas or electricity, use of taps, toilet flush, gas stove or electric kettle | |
Data acquisition and logging in alarm systems | |
Management of faults or events or alarms in packet switching networks involving network fault data acquisition and logging | |
Arrangements for monitoring packet switching networks involving capturing and processing of network packets | |
Scanning of documents | |
Arrangements in telecontrol or telemetry systems for selectively calling a substation from a main station, in which substation desired apparatus is selected for obtaining measured values therefrom |
Attention is drawn to the following places, which may be of interest for search:
Digital input using the sampling of an analogue quantity at regular intervals of time | |
Reading record carriers | |
Record carriers as such | |
Conversion of a code in general, e.g. compression of data |
Data acquisition normally always is linked to a particular application in the form of specifying what data is being acquired or from what entity data is being acquired and must be classified with those applications.
This place covers:
Pattern recognition techniques in general.
These include in particular:
- Pre-processing, data cleansing;
- Analysing;
- Post-processing;
- Software arrangements specially adapted for pattern recognition;
- Pattern recognition of signals other than images or video.
Note:
Pattern recognition refers to the automated recognition of patterns and regularities in data and includes using statistical or machine learning techniques to solve problems such as authentication, identification, classification or clustering.
Systems and methods for retrieving digital information stored in databases, data repositories or file systems, locally or remotely, retrieving structured data, semi-structured data, text, audio, image, video or multimedia data from databases, or for managing document libraries are classified in group G06F 16/00.
Higher-level interpretation and recognition of images or videos, which includes pattern recognition, pattern learning and semantic interpretation as fundamental aspects, are classified in subclass G06V. These aspects involve the detection, categorisation, identification and authentication of image or video patterns by acquiring, pre-processing, extracting distinctive features or matching, supervised or unsupervised clustering or classification of these features or representations derived from them leading to one or several decisions, related confidence values (e.g. probabilities) or classification/clustering labels, for explanatory purposes or to derive a certain meaning.
Computing systems where the computation is not based on a traditional mathematical model or computer, for example neural network architectures, are classified in subclass G06N. In particular, techniques for machine learning are covered by group G06N 20/00.
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
Attention is drawn to the following places, which may be of interest for search:
Content-based image retrieval | |
Fourier, Walsh or analogous domain transformations | |
Matrix or vector computation | |
Security arrangements for protecting computer systems against unauthorised activity | |
Authentication of user input in security arrangements for computers | |
Computer-aided design | |
Handling natural language data | |
Control or regulating systems in general | |
Speech recognition | |
Speaker recognition | |
Secret or secure communication |
This main group covers functional aspects of pattern recognition, i.e. algorithms or computer systems specifically designed therefor, regardless of a particular application and, therefore, of any particular type of data. In this group, it is desirable to add the indexing codes of group G06F 2123/00.
In this place, the following terms or expressions are used with the meaning indicated:
Authentication | Verifying the identity of a sample using a test of genuineness. It generally involves a one-to-one comparison with the genuine (authentic) sample. |
Categorisation | Assigning a data sample to a class according to certain distinguishing properties (or characteristics) of that class, and it generally involves a one-to-many test in which one data sample is compared with the characteristics of several classes. |
Classification | Assigning labels to patterns. |
Clustering | Grouping data samples in groups or classes based on their properties (or characteristics) and it generally involves a many-to-many (dis)similarity test. Grouping or separating patterns according to their closeness or dissimilarity. |
Feature extraction | Deriving descriptive or quantitative measures from data. |
Identification | In the context of collecting of data samples, identification means selecting a particular sample having a (predefined) characteristic which distinguishes it from the others. Several data samples are generally matched against the characteristic sample in a many-to-one process. |
Pattern patterns | Data having characteristic regularity, or a representation derived from it, having some explanatory value or being able to provide an interpretation. |
This place covers:
Removing bad data or interpolating missing values, finding hidden correlations in the data, identifying sources of data that are the most accurate and determining which data items are the most appropriate for use in analysis.
Attention is drawn to the following places, which may be of interest for search:
Improving data quality; Data cleansing, e.g. de-duplication, removing invalid entries or correcting typographical errors | |
Complex mathematical operations for evaluating statistical data | |
Single-class perspective, e.g. one-against-all classification; Novelty detection; Outlier detection |
This place covers:
Extraction of features.
Matching criteria.
Clustering techniques.
Classification techniques.
Fusion techniques.
Discovering frequent patterns.
Regression.
Determining representative reference patterns.
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
Arrangements for image or video recognition or understanding | |
ICT specially adapted for biostatistics; ICT specially adapted for bioinformatics-related machine learning or data mining, e.g. knowledge discovery or pattern finding | |
Machine learning, data mining or chemometrics for chemoinformatics | |
ICT specially adapted for computer-aided diagnosis, e.g. based on medical expert systems |
Attention is drawn to the following places, which may be of interest for search:
Image analysis |
This place covers:
Feature selection by using evolutionary computational techniques, e.g. genetic algorithms.
Feature selection by ranking or filtering the set of features, e.g. using a measure of variance or of feature cross-correlation.
Feature selection by evaluating class separability based on distance or (dis)similarity measures between (sub)sets of data samples. The intention for adopting distance metrics defined on features is to embed objects belonging to the same class, i.e. small intraclass distances, while embedding objects of different classes far away from each other in different classes, i.e. large interclass distances.
The processing can be iterative and, starting with no samples, it can successively include data samples by evaluating a model fit criterion, i.e. "forward" selection, or starting with all the samples and successively delete samples by evaluating a model fit criterion, i.e. backward elimination.
This place covers:
Finding a set of features that are effective for classification, and determining whether the resulting features or feature dimensions are the most powerful for classification, e.g. such as class separability.
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
Organisation of the matching processes | |
Organisation of the matching processes for character recognition or recognising digital ink or document-oriented image-based pattern recognition |
This place covers:
The matrix factorisation to ensure the non-negativity of the elements in the obtained matrix factors and, at the same time, nonlinear dimensionality reduction, i.e. non-negative factorisation, in order to prevent the negative elements of the selected feature subset from being contrary to the physical reality.
Attention is drawn to the following places, which may be of interest for search:
Complex mathematical operations for evaluating statistical data |
This place covers:
Techniques for generating training patterns which are generally intended to improve the performance of a pattern recognition system in cases where the data representative of a certain observation/event is scarce. This can be achieved by generating new training sets by sampling the original data set, replacement of some of its data or creation of new data, as in bootstrapping.
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
Generating sets of training patterns; Bootstrap methods, e.g. bagging or boosting |
Attention is drawn to the following places, which may be of interest for search:
Ensemble learning |
This place covers:
Matching which involves comparison of data values, combinations thereof or features derived from them, in which one entity is considered as a template pattern and the other is the input pattern (template matching). The matching process might involve transforming the patterns to accommodate for distortions.
The proximity measures used during matching may include classical distances, such as Euclidian distances, or more involved distances, divergences or other measures between probability density functions [PDF] or other statistical representations (e.g. mean, standard deviation, moments, kurtosis or Chi-square distance), for instance:
- Kullback-Leibler divergence;
- Mutual Information;
- Bhattacharyya distance;
- Hamming distance;
- Earth mover, Wasserstein distance
- Chi-square distance;
- Hellinger distance.
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
Image or video pattern matching; Proximity measures in feature spaces | |
Organisation of the matching processes | |
Organisation of the matching processes for character recognition or recognising digital ink or document-oriented image-based pattern recognition |
This place covers:
Techniques of grouping patterns together in order to reveal a certain structure or a meaning. These techniques aim at identifying different groups of similar entities by assigning them to a group (cluster) according to a measure of their similarity or, on the opposite, identify dissimilar items to split them into different groups. Separability is determined by measuring the similarity/dissimilarity, mostly to minimise the intra-cluster variations while maximising the inter-cluster ones. This is usually performed in a high-dimensional feature space constructed by extracting features, but can also be performed in the original domain.
Any pattern may belong exclusively to a single cluster (hard clustering) or it may belong simultaneously to more than one cluster up to a certain degree (fuzzy clustering) according to a proximity measure that may determine similarity or dissimilarity. Depending on the clustering method used, proximity may be defined (a) between vectors, (b) between a vector and a set of vectors (or a cluster), and (c) between sets of vectors (or different clusters).
Examples of proximity measures are: dissimilarity measures (based on l1, l2, and l∞ norms), similarity measures (inner product, cosine, Pearson's correlation coefficient, Tanimoto distance, etc.).
Different clustering algorithms include:
a) clustering based on statistical measures (which mainly employ numerical data) which adopt a cost function J related to possible groupings which is subject to a global or local optimisation criterion, and return a clustering that optimises J. Examples of algorithms are:
- Hard clustering algorithms, where a vector belongs exclusively to a specific cluster, e.g. k-means, k-medoids, Linde-Buzo-Gray, ISODATA, DBSCAN or Neural Gas;
- Fuzzy clustering algorithms, where a vector belongs to a specific cluster up to a certain degree, e.g. fuzzy c-means, Adaptive Fuzzy C-Shells [AFCS], Fuzzy C Quadric Shells [FCQS] or Modified Fuzzy C Quadric Shells [MFCQS];
- Probabilistic clustering algorithms, which follow Bayesian classification arguments and in which each vector is assigned to the cluster according to a probabilistic set-up, e.g. Expectation-Maximization [EM], Gaussian Mixture Model [GMM] or Mean-Shift;
b) graph-based clustering, e.g. minimum spanning tree [MST] clustering, clustering based on directed trees, spectral clustering or graph-cut optimisation;
c) Competitive learning algorithms for clustering in which a set of representatives is selected and the goal is to move each of them to regions of the vector space that are "dense" in terms of other vectors. Examples are leaky learning algorithm, Self-Organizing Maps [SOM] or Learning Vector Quantization [LVQ].
Hierarchical clustering is one of the popular techniques from the class of graph-based clustering, with its agglomerative or divisive variants. Various criteria can be used for determining the groupings, such as those based on matrix theory involving dissimilarity matrices. Algorithms included in this scheme are:
- Single link algorithm;
- Complete link algorithm;
- Weighted Pair Group Method Average [WPGMA];
- Unweighted Pair Group Method Average [UPGMA];
- Weighted Pair Group Method Centroid [WPGMC];
- Ward or minimum variance algorithm.
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
Information retrieval of still images; Clustering; Classification | |
Information retrieval of video data; Clustering; Classification | |
Image or video recognition or understanding using clustering, e.g. of similar faces in social networks |
In this place, the following terms or expressions are used with the meaning indicated:
AFC | Adaptive Fuzzy Clustering |
AO | Alternative Optimisation |
CCM | Compatible Cluster Merging |
DBSCAN | Density-Based Spatial Clustering of Applications with Noise, a non-parametric clustering algorithm which does not require specifying the number of clusters in advance. |
FCSS | Fuzzy C-Spherical Shells |
FCV | Fuzzy C-Varieties |
FHV | Fuzzy Hyper Volume |
KNN | k-Nearest Neighbour; a classification algorithm which, for a given data sample, chooses the k most similar samples from a training set, retrieves their respective class labels, and assigns a class label to the data sample by majority decision; variant: 1NN, which is KNN for k=1. |
LVQ | Learning Vector Quantisation |
This place covers:
Classification in general, namely identifying to which category or which set of categories (classes) a new data or some other representation originating from it belongs, on the basis of a training set of data containing observations (or instances) whose category membership is known. Often, the individual observations are analysed into a set of quantifiable properties, known as explanatory variables or features. These properties may be categorical, ordinal, integer-valued, real-valued, etc. Other classifiers perform a class assignment by comparing current observations to previous observations by means of a similarity or distance function.
A classifier can be parametric or non-parametric depending on the type of model adopted for the observations.
Classification algorithms include those:
- based on the distance between a decision surface and training patterns, e.g. support vector machines [SVM];
- based on the distance between the pattern to be recognised and some reference, where the reference can be a prototype, a centroid of samples of the same class or the closest patterns from the same class or different classes, e.g. nearest-neighbour classification;
- based on a parametric, probabilistic model, where the model uses the Neyman-Pearson lemma, likelihood ratios, Receiver Operating Characteristics [ROC], plotting the False Acceptance Rate [FAR] versus the False Rejection Rate [FRR], Bayesian classification, etc.;
- based on a graph-like or tree-like model, e.g. decision trees, random forests, etc. Examples are the Classification and Regression Trees [CART], ID3 [Iterative Dichotomiser 3], C4.5, etc.
When the decision surface of the classifier is considered, this can be a linear classifier or non-linear classifier. Linear classifiers model the boundaries between different classes in the feature space as hyperplanes. Non-linear classifiers use e.g. quadratic, polynomial, or hyperbolic functions instead.
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
Information retrieval of still images; Clustering; Classification | |
Information retrieval of video data; Clustering; Classification | |
Image or video recognition or understanding using classification |
In this place, the following terms or expressions are used with the meaning indicated:
CART | Classification and Regression Tree |
C4.5 | Classification algorithm using a decision tree |
FAR | False Acceptance Rate |
FRR | False Rejection Rate |
Gini impurity | A measure of how often a randomly chosen element from the set would be incorrectly labeled if it was randomly labeled according to the distribution of labels in the subset; usually used at the level of the nodes of tree-based classifiers. |
ID3 | Iterative Dichotomiser 3, a precursor of C4.5 |
ROC | Receiver Operating Characteristics |
This place covers:
Combining the information from several sources in order to form a unified data representation.
A simple fusion process combines raw data from several sources or different modalities (e.g. fusing spatial and temporal data). Besides fusing the raw data, it is also possible to first process the sensor data to extract features and then combine the extracted features into a joint feature vector. Alternatively, it is possible to fuse classification results, e.g. inputting the features from different sensor modalities to separate classifiers, receiving respective classification scores from each classifier, and combining the individual scores into a final classification result.
Examples are probabilistic fusion, statistic fusion, fuzzy reasoning fusion, fusion based on evidence and belief theory, e.g. Dempster-Shafer or fusion by voting.
Fusion can also be applied at different stages of a recognition system for different purposes, e.g. for dimensionality reduction, computing robustness, improving precision and certainty in the classification decisions, etc.
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
Image or video recognition or understanding using fusion, i.e. combining data from various sources at the sensor level, preprocessing level, feature extraction level or classification level |
In this place, the following terms or expressions are used with the meaning indicated:
Dempster-Shafer | General framework for reasoning with uncertainty which combines evidence from different sources and arrives at a degree of belief (represented by a mathematical object called belief function) that takes into account all the available evidence. |
This place covers:
Pattern recognition techniques based on regression, i.e. statistical techniques for estimating the relationships between a dependent variable (often called the "outcome" or "response" variable) and one or more independent variables (often called "predictors", "covariates" or "explanatory variables"), where the variables model the underlying data.
Common forms of regression are:
- Linear regression - the model specification is that the dependent variables are a linear combination of the parameters (but need not be linear in the independent variables). The goal is to find a line (or a more complex linear combination) that most closely fits the data according to a specific mathematical criterion (e.g. by minimising the least-mean-squares criterion). For example, the method of ordinary least squares computes the unique line (or hyperplane) that minimises the sum of squared differences between the true data and that line (or hyperplane);
- Non-linear regression, e.g. polynomial, binomial, binary, logistic, multinomial logistic, etc.
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
Image or video recognition or understanding using regression, e.g. by projecting features on hyperplanes |
Attention is drawn to the following places, which may be of interest for search:
Complex mathematical operations for evaluating statistical data |
In this place, the following terms or expressions are used with the meaning indicated:
LMS | Least Mean Squares |
RANSAC | RANdom SAmple Consensus – an iterative algorithm for fitting a linear mathematical model such as a line or a plane through a set of points by eliminating the influence of outliers |
This place covers:
Details of software arrangements specifically adapted for pattern recognition or pattern recognition of signals. These include specifically designed user interfaces or toolboxes for solving pattern recognition problems.
Attention is drawn to the following places, which may be of interest for search:
Interaction techniques based on graphical user interfaces [GUI] | |
Execution arrangements for user interfaces | |
GUI for database retrieval, e.g. presentation of query results, browsing or visualisation therefor | |
ICT specially adapted for bioinformatics-related data visualisation, e.g. displaying of maps or networks | |
Data visualisation for chemoinformatics |
This place covers:
Security arrangements for protecting computers or their components, programs and data against unauthorised activity, e.g. intrusion into a computer, computer malware detection and handling, authentication, unauthorised use of data, dishonest alteration of data, theft of secret data.
In particular, the following subjects are covered:
- Protecting specific internal or peripheral components in which the protection of a component leads to protection of the entire computer;
- Monitoring users, programs or devices to maintain the integrity of platforms;
- Authenticating users, programs or devices;
- Protecting distributed programs or content, e.g. vending or licensing of copyright material;
- Protecting data used within a computer.
This group covers security arrangements for local platforms.
Classification should be directed to groups H04L 9/00 - H04L 9/32 when the subject is secret or secure communication involving the use of encryption.
Furthermore, classification should be directed to group when cryptographic protocols are of relevance H04L 9/00, H04L 63/00 when network security protocols are of relevance, H04L 65/60 when Media handling, encoding, streaming or conversion are of relevance, H04L 67/01 when network protocols for data switching network services are of relevance.
Finally, classification should be directed to group H04W 12/00 when security or authentication arrangements in wireless communication networks are of relevance.
Attention is drawn to the following places, which may be of interest for search:
Program control, executing machine-instructions, program loading or initiating in general, task interaction, specific resource access rights | |
Multiprogramming | |
Error detection, error correction, monitoring | |
Electric safety arrangements in control or regulating systems | |
Electric program-control in control or regulating systems | |
Record carriers for use with machines and with at least a part designed to carry digital markings | |
Protecting identification code in record carriers | |
Systems or methods specially adapted for administrative, commercial, financial, managerial or supervisory purposes | |
Complete banking systems | |
Alarms or alarm systems | |
Equipment anti-theft monitoring by a central station | |
Ciphering apparatus | |
Information storage based on relative movement between record carrier and transducer | |
Arrangements for conditional access to broadcast information using cryptography | |
Secret or secure communication, e.g. including authentication means | |
Key distribution in cryptographic systems | |
Algorithms, certificates, signatures, hash functions, encryption | |
Data switching networks | |
Scanning, transmission or reproduction of documents | |
Selective content distribution, e.g. interactive television, video on demand | |
Security arrangements, e.g. access security or fraud detection; authentication in wireless communication networks |
The general rule is to limit to the best-suited group but there could be a plurality of groups for a document if that document discloses many relevant aspects when taken separately (e.g. a document having isolated disclosures) or in combination, in particular when a combination of groups is more suited to reflect the disclosure.
In this place, the following terms or expressions are used with the meaning indicated:
Content | means any intellectually created work whose copyright is to be safeguarded |
This place covers:
Protecting software against unauthorised usage in a vending or licensing environment, e.g. protecting the software provider's copyright. The protection is generic, i.e. not specific to the type of content.
Protecting data in an environment substantially outside the data owner's control (or in a hostile environment). The term "hostile environment" means data and operational environment of the data are controlled by different entities.
Example: hostile environment: Financial Times [FT] has a server where users who pay get a key that enables locally stored encrypted FT-newspaper-articles to be decrypted and read. The articles are in a hostile environment, the computer of the user, where FT has limited or no influence, therefore the article needs to be protected from the user, in this case by encryption.
This place does not cover:
Protection in video systems or pay television |
Attention is drawn to the following places, which may be of interest for search:
If protection is restricted to techniques specific to executables | |
Protecting data in an environment substantially within the data owner's control (or in a non-hostile environment) | |
Games systems, i.e. specific solutions for security of games | |
Chip on media | |
Preventing unauthorized non-electronic copying | |
Commerce, e.g. marketing, shopping, billing, auctions or e-commerce | |
Business processing related to protecting distributed files or licensing | |
Image watermarking when the watermarking itself is concerned | |
Preventing of unauthorized reproduction or copying of media | |
Preventing unauthorized electronic reproduction of physical documents | |
Digital watermarking on images when the watermarking itself is concerned | |
Protecting content in television systems |
This place covers:
Different protection for each instance of software or content, e.g. creating hardware or user specific versions, binding software or content to specific terminals or devices.
This place covers:
Binding licenses to one rendering device the user uses, e.g. mp3-player, computer or mobile phone.
This place covers:
Binding licenses to a group or type of rendering devices the user uses, e.g. list, type or capabilities of devices, something the device belongs to.
This place covers:
Binding licenses to something the user possesses, e.g. tokens, mobile phones, recording media or USB-sticks. The content can be transferred from one device to another.
In this place, the following terms or expressions are used with the meaning indicated:
Token | not rendering the content |
This place covers:
Binding the content to a user.
Binding licenses to characteristics of the user, e.g. biometrics, fingerprint, iris or behaviour.
Binding licenses to a group the user belongs to, e.g. domain, family, friends, university, library or company.
Binding licenses to something the user knows, e.g. a password.
This place covers:
Examples: Managing floating licenses to protect against unauthorized usage of distributed programs or content.
This place covers:
Editing or modifying the content by the user.
Modifying or creating licenses for e.g. re-distributing rights, adjustment to user-needs, license changes, also including shareware where the license is updated.
Attention is drawn to the following places, which may be of interest for search:
Personalisation of content | |
Superdistribution of content |
This place covers:
Converting content for different system requirements, e.g. different digital right management systems, less powerful devices, interoperability or compatibility.
User defined content, specifically created on user or business request.
Watermark identifying e.g. content, user or device.
Same copy for demo version or product version.
This place covers:
Usage restrictions implemented at operating system level to prevent e.g. access to registers, clipboard or APIs.
This place covers:
Hiding content, licenses or keys, e.g. inside the content, file systems, at operating system level or by obfuscating.
This place covers:
Techniques of key generation specifically designed for digital right management implementation.
Techniques of key distribution specifically designed for digital right management implementation.
Attention is drawn to the following places, which may be of interest for search:
Key distribution or management, e.g. generation, sharing or updating, of cryptographic keys or passwords |
This place covers:
Converting a license for e.g. different digital right management systems, languages, versions, user needs, less powerful devices, interoperability or compatibility.
Grace period, e.g. in offline systems the user should be able to continue for some time even if a license is expired.
Definition of rights, e.g. rights definition languages, grammar, syntax, semantics, graphical representations of rights, parsers or right consistency.
This place covers:
Methods for revoking licenses, e.g. preventing licenses to be restored again from backup or looking after copies of the license to delete all instances of the license.
This place covers:
Performing recurrent authorisation checks, not just at installation or loading time.
This place covers:
Logging, metering or counting, e.g. copy, usage, play, transfer, move, delete, modification or time.
Note:
License logging also falls under this definition, because for logging a license is considered as content.
This place covers:
The content or license is given back from the user or client, e.g. for floating licenses, check-in/check-out, or renting.
Attention is drawn to the following places, which may be of interest for search:
Arrangements for software licence management or administration |
This place covers:
Techniques for allowing, supporting or preventing backup or restore specifically designed for DRM.
This place covers:
Transferring fragments of content/license for:
- Payment: shareware, part of the content/license is sent after payment.
- Optimisation: incremental, differential or update. The fragment alone is not sufficient for rendering.
Attention is drawn to the following places, which may be of interest for search:
Payment processing for DRM |
This place covers:
Third party with special digital right management aspects, e.g. third party generates and stores part of the key. The third party is not only transferring data.
This place covers:
Digital right management systems especially adapted for content sharing, e.g. peer-to-peer solutions.
Attention is drawn to the following places, which may be of interest for search:
Cryptographic mechanisms or cryptographic; Arrangements for secret or secure communications; Network security protocols | |
Network architectures or network communication protocols for network security | |
Network arrangements, protocols or services for supporting real-time applications in data packet communication | |
Network arrangements or protocols for supporting network services or applications |
This place covers:
Permitting further distribution of digital content, e.g. from user to user, but still maintaining some control over re-distributed copies.
Attention is drawn to the following places, which may be of interest for search:
License editing |
This place covers:
Synchronisation between:
- (License) servers: master/slave
- Local and distant licenses
Comprises also offline usage.
This place covers:
Atomic transaction in which a series of operations either all occur, or all do not occur (wish of content owners).
Attention is drawn to the following places, which may be of interest for search:
Restricting unauthorised execution of programs by using dedicated hardware |
This place covers:
Protection is restricted to techniques specific to executables.
This place covers:
Dedicated hardware is used for authorizing access to an executable program using techniques specific to executable programs (e.g. manipulation of the code, manipulation of the instruction flow or data flow, security routine in the program to verify a code in a dongle).
Attention is drawn to the following places, which may be of interest for search:
Authenticating in combination with an additional device | |
If the program contains security routines acting after initial authorization | |
Location-sensitive |
This place covers:
Be aware that the software generally stays unlocked. Obfuscation is primarily used to prevent reverse engineering but not to prevent copying.
Examples: Program code is altered at each execution, program flow is changed to mask calls to sensitive routines, data flow is changed, compiling techniques normally performed by code optimizers rolled back.
Attention is drawn to the following places, which may be of interest for search:
If similar techniques as the ones used for obfuscation are used to restrict unauthorized usage and thus copy protection |
Attention is drawn to the following places, which may be of interest for search:
Digital watermarking on images |
This place does not cover:
If the network plays a role, e.g. secure socket layer, IPsec, Internet Key Exchange, or Extensive Authentication Protocol |
Attention is drawn to the following places, which may be of interest for search:
Authentication using challenge-response | |
Bluffing e.g. pretending to have connected a user to a real node when in fact the connection is to a dummy node | |
Lost password, i.e. recovery of lost of forgotten passwords | |
Verifying human interaction, e.g. Captcha | |
Metering, i.e. counting events for security purposes | |
Time limited access e.g. to a computer | |
Recurrent verification | |
Clearing memory or data when detecting an attack e.g. to prevent the data from being stolen | |
Time stamp | |
One-time-passwords | |
Time-dependent-passwords, e.g. periodically changing passwords |
This place covers:
Authentication is not triggered by a user but imposed/initiated by a third party.
This place does not cover:
If re-authentication is triggered after an intrusion |
This place covers:
Specific authentication aspect (e.g. initial authentication, regular authentications at predetermined time intervals, or re-authentication after logout or locking) or password design.
Attention is drawn to the following places, which may be of interest for search:
Authentication mechanisms |
This place covers:
Using characteristics specific to telephone lines.
Examples: Call-back to user phone number derived from phone network provider.
Particular cases: Authentication request triggered by server (no call-back) using phone number derived from phone network provider.
This place covers:
Authentication succeeds only when secondary user-specific authorization criteria are fulfilled at login time.
Examples: An example of secondary user-specific authorization criteria is the typing speed of the user; admit user only if this typing-speed corresponds to its normal one.
Particular cases: Maximum number of login attempts for a given user, login must be at predetermined time of day, remote login is restricted to specific computers.
This place does not cover:
If the typing speed is the primary authentication criteria | |
Observing the pattern of computer usage in order to trigger alarm and detect intrusion |
This place covers:
Using physiological data intrinsic to a principal and what a principal is able to do. Examples:
- Typing/mouse clicking frequency;
- Handwritten signature.
Attention is drawn to the following places, which may be of interest for search:
Authenticating a user by observing the pattern of computer usage, e.g. typical user behaviour | |
Use of unusual or unconventional user registration | |
Authenticating a user by using biometrical features, e.g. fingerprint, retina-scan |
This place covers:
All authentication mechanisms implying use of a ticket, token or certificate issued by a third party upon initial user authentication. The ticket contains a proof of the initial authentication which is accepted by all parties. Examples: Kerberos, OSF DCE.
Attention is drawn to the following places, which may be of interest for search:
Authentication by using a single sign-on procedure provides access to a plurality of nodes | |
Verifying identity using certificates, signatures, hash functions and/or encryption | |
Authenticating by using tickets, e.g. Kerberos | |
Authenticating by using certificates |
Attention is drawn to the following places, which may be of interest for search:
Authentication by using a single sign-on procedure provides access to a plurality of nodes |
This place covers:
The additional device is used for authentication with the purpose of accessing a computer system.
Particular cases: The additional device is a cryptographic processor.
This place does not cover:
If the additional device is used to access a program | |
Using hardware token other than for authentication (e.g. storing secret data) |
Attention is drawn to the following places, which may be of interest for search:
Authenticating by using an additional device, e.g. smartcard, SIM |
This place covers:
Examples: Continuous detection of wireless authentication token carried by user.Particular cases: Wireless presence detector, logout when not present.
This place does not cover:
If the additional device is used to access a program |
Attention is drawn to the following places, which may be of interest for search:
Authenticating by using an additional device, e.g. smartcard, SIM |
This place covers:
The graphical or iconic code is generated by a local system, a remote system or a principal.
Examples: The graphical code is used to challenge a principal and check something he should know, typically by manipulation of symbols or elements of a drawing or variation of key arrangement on a virtual keyboard.
This place does not cover:
Handwritten signature |
This place covers:
Using a third party performing a mapping of the credentials of the user for a first application to credentials valid for other applications.
Examples:
The third party is a password server.
The third party is a smart card. Particular cases: The third party is the first application.
Attention is drawn to the following places, which may be of interest for search:
Authentication using certificates |
This place covers:
Examples:
- Authentication with portable phone, receive sms with password, connect via fixed telephone line using password.
- Voice call for authentication, server calls back terminal.
Attention is drawn to the following places, which may be of interest for search:
Device authentication, i.e. authenticate client device independently of the user |
Attention is drawn to the following places, which may be of interest for search:
Mutual authentication |
This place covers:
Protecting computer platforms against harmful, malicious or unexpected behaviour or activities.
This group is not strictly limited to software solutions.
Attention is drawn to the following places, which may be of interest for search:
Just-in-time application of countermeasures | |
Metering, i.e. counting events for security purposes | |
Clearing memory or data when detecting an attack e.g. to prevent the data from being stolen | |
Time stamp |
The difference between G06F 21/56+ and the others groups G06F 21/50+ (namely G06F 21/51, G06F 21/52+, G06F 21/55+ and G06F 21/57+) may be formulated as:
- G06F 21/56+: we would trust the code or system if it were not infected (we look for the infection as such)
- other groups G06F 21/50+ (see definition above): we don't trust the code or system (we make an assessment of the global code or system; we don't look for an infection as such) G06F 2221/031 (Protect user input by software means) and G06F 2221/032 (Protect user output by software means) are additionally used to distinguish documents dealing with securing user input/output, e.g. in banking systems / applications
The subclasses G06F 2221/03+ are used in combination with this group.
This place covers:
Accept / reject loading of application:
- onto platform for later execution.
- into memory for immediate execution.
from
- Loal storage
- Remove device (e.g. By downloading).
Based on static features of the application when not being executed e.g.:
- Signature or certificate provided by application creator, provider or tester
- Integrity.
- Capability list.
- capabilities of application determined by analysis.
An application is software distinct from firmware and os such as:
- Directly executable code (binary code)
- Interpretable programs (script language)
- Interpretable files such as html, word, etc. Documents
Examples:
- Verify integrity or application origin (application creator, provider, or tester) by checking a signature, certificate, etc. of application.
- Verify integrity of application or application origin by transforming and reverse transforming the application:By analyzing user content, e.g. analyse relationship of websites referred to by a web page.
- Check application capabilities versus a predefined security policy.
Attention is drawn to the following places, which may be of interest for search:
Authenticating web pages |
This place covers:
Intrusion detection at the single program level, i.e. detect intrusion of:
- A system by a single program.
- A single program.
During execution of the single program e.g. by specifically monitoring execution of the single program at the single program level
Examples:
- Transform by obfuscation means which do not add code.
- Modify code to avoid security issue when fault injection.
- Modify code to enforce security policy.
- Detect code injection
This place does not cover:
Transformation by addition of security routines or objects to the program | |
Monitoring of the whole system running many programs |
This place covers:
Intrusion detection at the environment level of the execution of the single program e.g.:
- Run program in secure, isolated environment (VM, sandbox), e.g. by modifying VM or sandbox to include special security measures
- Provide security measures in interface (library, API, OS) of program with its Environment, e.g.:
- Provide secure library or API interfacing the program
- Modify library, API or OS to include security measures
- Have OS service or library making security checks or running in protected environment
Examples: by using virtual machine, sandbox, secure library or by isolating processes at operating system level
This place covers:
- Transformation by addition of code to Source code
- Executable program to be loaded or already loaded in memory for execution to ensure proper execution of program
- Examples:
- Add / modify code to detect fault injection by enforcing proper execution sequence
- Modify code to detect improper execution flow when code error
- Add code to detect software attacks
- Modify code to enforce security policy
- Add code to detect code tampering in memory
- Add dummy instructions for obfuscation purposes
This place does not cover:
Modification of code to include some static feature (e.g. a checksum) to be checked prior to execution | |
Transformation of code not by addition, e.g. by obfuscation means |
This place covers:
Intrusion detection at the level of the system independently of execution of one single program e.g. by monitoring execution of the whole system while running many programs.
This place does not cover:
Intrusion detection at the single program level during execution of the single program |
This place covers:
Monitor the system, user actions within the system, etc., analyze the monitoring data gathered during long term and take action.
Examples:
- Determine normal user behaviour for later security issue detection
- Log security issue events for later action / risk assessment
- Collect system information and deduce security issue
This place covers:
Monitor the system, user actions on the system, etc., immediately analyze the monitoring data gathered and directly take action.
Examples: Detect abnormal user behaviour, security issue or physical attacks; and immediately react.
Attention is drawn to the following places, which may be of interest for search:
If the monitoring and direct action is based on data obtained by long-term monitoring |
This place covers:
A covert channel is defined as being a communication channel that allows a process to transfer information in a manner that violates the system's security policy.
E.g.: software measures against:
- Intended malevolent internal signalling or communication between processes on system.
- Intended malevolent external signalling or communication by process on system.
- Accidental internal leakage of data between processes on system by storage or communication
- Accidental external leakage of data of process on system by storage or communication
- Accidental internal or external leakage of system or process state or behaviour
Examples:
- Protect against physical (e.g. electromagnetic; non power consumption) monitoring to obtain information on data manipulated by the system or code executed by the system.
- Protect against fault attacks
- Data leakage between processes via common / non secure memory Secure data transfer within processes
- Hidden communication between processes by one process observing other process behaviour
- External data leakage by hidden communication
- Unwanted data leakage in programs
- Modify code to avoid information exposure in memory
This place does not cover:
Inhibiting the analysis of circuitry or operation with measures against power attack |
This place covers:
Examples:
- Protection against root kits by scanning for malwares at boot.
- Virus resistant computer by booting from authenticated read-only boot device, transfer accepted file types only.
- Determine malicious (child) processes by file generation time changes
- Remote control upon virus detection (i.e. cut communications).
- Send executable email contents to sacrificial server to verify execution for virus activity.
- Analyze file with respect to virus families, family based extraction.
- Trojans.
This place does not cover:
If for avoiding or detecting spam. If for virus detection in network (system) or at network protocol level |
- The difference between G06F 21/56 and the others subgroups under G06F 21/50 (namely G06F 21/51, G06F 21/52, G06F 21/55 and G06F 21/57) may be formulated as:
- G06F 21/56: we would trust the code or system if it were not infected (we look for the infection as such).
- Other groups under G06F 21/50 (see definition above): we don't trust the code or system (we make an assessment of the global code or system; we don't look for an infection as such).
In this place, the following terms or expressions are used with the meaning indicated:
Virus | A malicious (i.e. intended to harm) executable code or script hidden or embedded in a normally non malicious data, code or system. It need not be self-replicating |
This place covers:
Information relating to a specific type or family of viruses.
This place covers:
Detect presence of virus without executing directly or by emulation, except emulation for the purpose of higher level analysis (control code, data flow)
Examples of such detections:
- Analyse source code or scripts.
- Execute intermediate compiled code and analyse.
- Compile and analyse.
- Disassemble binary code and analyse control flow or data flow and/or match execution code patterns without simulation of execution.
- Validate file formats.
- Verify based on file type.
This place covers:
Starting point for analysis: source code, script or file type or format. The source code may be obtained by disassembly.
Attention is drawn to the following places, which may be of interest for search:
If the source code is compiled and executed or emulated for analysis |
This place covers:
Concerns virus detection by binary or source code pattern matching or the process of enhancing the signature recognition procedure.
Examples:
- By using virus binary code signature.
- By using a virus source code pattern.
This place covers:
Examples:
- Detect change of files.
- Detect change of file portions.
This place covers:
Examples:
- Execute directly or by emulation and observe effect by monitoring / limitation
- Emulation of code.
- Execution in sandbox / virtual machine.
- Monitoring / limiting Inputs/Outputs.
- Monitoring memory allocation / changes
- Encoding executable and decoding upon execution such that infection is detected at run time.
- Modifying execution such that infection is detected at run time.
Attention is drawn to the following places, which may be of interest for search:
Access rights if detection based on access right violation |
Use additionally G06F 2221/033 (Test or assess a software) if detection at the level of execution of a single program.
Use additionally G06F 2221/034 (Test or assess a computer or a system) if detection at system level (as opposed to the level of execution of a single program).
This place covers:
Use hardware specifically dealing with virus detection or removal. The hardware may be general purpose.
Examples:
- Normal boot using a general purpose external storage means (e.g. USB stick) with anti-virus software.
- Use intermediate server for virus detection.
- Use dedicated, specialized hardware means for detecting virus.
- Use dedicated, specialized hardware means for detecting suspicious activity.
- Use dedicated, specialized hardware means for alerting user upon virus detection.
- Use dedicated, specialized hardware means for avoiding virus infection by e.g. write protection.
- Use dedicated, specialized hardware means for avoiding propagation by binary transmission.
Attention is drawn to the following places, which may be of interest for search:
If carried out on a separate, remote device (third party) | |
Use of hardware tokens, smart cards or dongles |
This place covers:
Provision of software means to remove viruses or restore infected files. Examples:
- Restore system to earlier trustworthy state.
- Apply reverse behaviour of a detected virus in order to restore file/code.
- Observe potentially harmfull software on computer at runtime, remove its effects.
- Verify/scan files upon file access; replace file with clean file.
- Boot one OS to scan other OS for viruses and cleanup.
This place covers:
- Validate trusted platform configuration.
- Defeat computer security by installing software into RAM using peripheral DMA.
- Receive vulnerability alert, retrieve and install patch.
Attention is drawn to the following places, which may be of interest for search:
Non secure initialization, program loading or initiating without any security aspects |
This place covers:
Securely update, patch or load firmware or firmware modules.
Examples:
- Authenticate firmware updates, patches or modules.
- Authenticate configuration file listing updates, modules to load.
- Authenticate key to allow firmware update.
- Authenticate firmware / configuration update program / command.
This place covers:
Examples:
- Authenticate boot code(s) at start-up.
- Verify configuration at boot.
- Pre-boot authentication (user authentication or by using unlock code authentication).
- Disable boot device
- Boot read-only system.
- Security action (e.g. Malware scan) by booting safe system in dual boot system.
- Load high security barrier code.
This place covers:
Examples:
- Analyze or test a computer or a program against vulnerabilities or threats at computer level or at program level.
- Analyze or test a computer or a program for security relevant capabilities.
This place does not cover:
If assessing/evaluating the network per se |
Attention is drawn to the following places, which may be of interest for search:
Testing software |
Use additionally G06F 2221/033 (Test or assess a software) or G06F 2221/034 (Test or assess a computer or a system) to distinguish between assessment of computer or software.
This place covers:
Authorizing access to an executable program using techniques specific to executable programs (e.g. manipulation of the code, manipulation of the instruction flow or data flow, security routine in the program to verify a code in a dongle) Protecting data in an environment substantially within the data owner's control (or in a non-hostile environment). The term "hostile environment" means data and operational environment of the data are controlled by different entities.
Example: non-hostile environment: FT(Financial Times) has a server where users who pay get a username+password to access FT-newspaper-articles on the server. FT has full control over the server, the data is stored on the server, and therefore the data is not in a hostile environment.
Attention is drawn to the following places, which may be of interest for search:
Recurrent verification |
In this place, the following terms or expressions are used with the meaning indicated:
Data | Also includes programs |
Attention is drawn to the following places, which may be of interest for search:
For hardware details |
This place covers:
The protection mostly relates to the secrecy, confidentiality and integrity of printed data.
Examples:
- Ensure a printed document is authentic copy of electronic document by protecting the transmission between the host and the printer. Selected for print is encrypted at the user's computer and decrypted at the printer upon user authentication at the printer, e.g. using a password or a badge.
- Ensure document can only be printed out by the intended user, e.g. by password input at printer or authentication using a smartcard containing the private key of the user.
Attention is drawn to the following places, which may be of interest for search:
Scanning, transmission or reproduction of documents |
This place does not cover:
If the solution is achieved via the display or its driver. |
Attention is drawn to the following places, which may be of interest for search:
File encryption, i.e. use of unusual or unconventional encryption techniques | |
Time limited access e.g. to data | |
Access rights | |
inheriting rights or properties, e.g. propagation of permissions or restrictions across a hierarchy | |
Locking files | |
Restricted operating environment, e.g. creating a user-specific working environment, parental control |
This place covers:
Object access right control is performed by a dedicated application or function (separate from an optional access right control offered by the file system. Access control based on a file-system goes to G06F 21/6218 and subgroups). Access rights or keys, and a security function to apply the rights, are associated directly to an individual file.
This place does not cover:
For access control based on a file-system |
This place covers:
Examples:
- Access rights in databases provided by user capability lists.
- How the file system or the operating system enforce access rights.
This place covers:
Examples:
- The security is at the level of records in a structured file or database, there is a field for each record dedicated to protecting this record and containing for instance a security level, access rights or encryption keys.
- The structure of the database (tables, records, views, queries, stored procedures...) is the target of the security, and by doing this the data is protected.
- Particular case : if the protection is "outside" the database, e.g. rules stored outside the DB and enforced when the DB is queried, because "outside" becomes "inside" if the security is based on database-queries.
This place does not cover:
Data structures not related to security |
Attention is drawn to the following places, which may be of interest for search:
Information retrieval (from databases and internet) |
This place covers:
Problem to be solved: Maintain security when exchanging data between systems with different (heterogeneous) security architectures.
This place covers:
Problem to be solved: Confidentiality of the personal data. General protection of personal data (e.g. encrypting all data, access rules, ...).
This place does not cover:
If just the link from the data to the person is protected |
In this place, the following terms or expressions are used with the meaning indicated:
Personal data | any information relating to an identified or identifiable natural person |
This place covers:
Protecting where the data may be accessed without revealing the person's identity, e.g. by anonymising or decorrelating" Personal Data is related to a person via a link.
Without the link, the data is no longer personal private data, and needs no further protection. Decorrelating or anonymising means partly or completely removing the link.
Examples: A hospital-server with special techniques to protect the confidentiality of patient-data, where the patient data and the sickness data are stored separately.
This place covers:
Protecting functions or features provided by specific software application like a word processor, an email client, a calendar application.
Examples: Restricting the printing function in a word processor based on access rights. Restricting entry editing in a shared calendar application.
This place does not cover:
If the protection is restricted to techniques specific to executables. |
Attention is drawn to the following places, which may be of interest for search:
For access to hardware functions |
This place covers:
- Protection of the integrity of data only.
- Example: A contract between two individuals where the integrity of the contract is protected.
- Particular case : If the code is not executed but transferred for collaborative programming.
- Protection of the integrity of data only.
- Examples: A contract between two individuals where the integrity of the contract is protected.
This place does not cover:
When code integrity is at stake or if the verification takes place in the context of protecting computer platforms against harmful, malicious or unexpected behaviour or activities |
This place covers:
Example: A notary certifies that the contract (file) is the original contract (file).
This place covers:
The hardware itself of the component must be protected; Usage of dedicated hardware to secure an entire platform, authentication, a software or data is not enough to classify here; In most cases, it is particular hardware that is protected, but a hardware solution to protecting data would also be classified here; The protected asset and/or the countermeasure to be implemented in hardware.
Attention is drawn to the following places, which may be of interest for search:
Just-in-time application of countermeasures |
This place covers:
Two modes of operation at processor level.
Examples: 68020 supervisor mode / user mode.
This place does not cover:
When dual mode in not the main aspect is of the invention |
This place covers:
Examples: to counter reverse engineering; Countermeasure against analyzing microprocessor or other components to infer which instructions are ran and retrieve statistical information about the arguments of the instructions.
Attention is drawn to the following places, which may be of interest for search:
Dummy operation e.g. a processor performs dummy operations as countermeasure to differential power analysis | |
Countermeasures at the cryptographic algorithm level against power analysis attacks, e.g. modifying the S-Box layout in a DES algorithm |
This place covers:
Software and hardware measures against monitoring of power consumption to obtain information about the system such as differential power attack or simple power attack.
Examples:
- Hide boot order.
- Multiple processors to hide power consumption.
- Algorithm design for general purpose processor.
- Use special hardware logic.
- Execute dummy instructions.
- Randomize execution flow.
- Change instruction clocking.
- Hide memory / register accesses.
This place covers:
Only for protection of the smartcard as such.
This place does not cover:
Protection of disk controllers (input/output device) |
Attention is drawn to the following places, which may be of interest for search:
Chip on media |
This place does not cover:
Address-based protection against unauthorised use of memory | |
Secure firmware programming | |
Record carriers for use with machines and with at least a part designed to carry digital markings |
This place does not cover:
Preventing unauthorised reproduction or copying of disc-type recordable media | |
Usage of defectuous sectors for copy protection |
This place covers:
Examples: Access Control Lists stored in a disk controller.
This place covers:
Examples: Keyboard with password locking mechanism embedded in the keyboard.
Attention is drawn to the following places, which may be of interest for search:
Biometric input devices |
This place covers:
Examples:
Protecting data shown on a display.
Hardware solution for protecting displayed data.
This place does not cover:
Use of password or smartcard to activate session of a printer |
This place covers:
Examples:
Encryption circuit between motherboard and hard-disk.
Device between computer components allowing/banning interconnections therebetween in accordance with user IDs; user-specific hardware configuration.
This place covers:
Housing resisting tampering or housing with tamper detection means. The protection takes place at the housing level.
Examples:
- PC with housing-open detection switch.
- Tamper resistant circuit.
This place does not cover:
The protection takes place at the chip level | |
Secure enclosure, mechanical anti-theft mechanism if no computer component is protected |
Attention is drawn to the following places, which may be of interest for search:
Clearing memory, e.g. to prevent the data from being stolen |
This place covers:
The protection takes place at the chip level.
This place does not cover:
The protection takes place at the housing level |
This place covers:
Example: Hardware locks itself / is locked when outside of RF-field.
Particular cases: Send a hardware locking message to stolen device.
Attention is drawn to the following places, which may be of interest for search:
If the sent message is not to trigger hardware lock but to force authentication |
This place covers:
- Arrangements and methods specially adapted for automated execution for design of technical entities
- Simulation for design purposes of technical entities
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
Software design | |
Software simulation | |
Patterns for cutting-out; Methods of drafting or marking-out such patterns | |
Adaptive control systems involving the use of models or simulators | |
Three dimensional graphical modelling and manipulation | |
Simulation for teaching or training purposes | |
Arrangements for designing of test circuits for static stores |
In this place, the following terms or expressions are used with the meaning indicated:
Design | Description of technical parameters or a virtual model of a technical arrangement; does not cover aesthetic aspects; not to be confused with the physical object. |
Verification | Determining the correct functioning of a design; not to be confused with testing of a physical object. |
Simulation | Determining technical properties and behaviour of an entity by performing a virtual simulation of a model in a computer, possibly by using specifically adapted hardware. |
Model | A computer readable description of an entity, defining or implying technical properties. |
This place covers:
- Design of geometrical structures of technical entities, e. g. shape, dimensions, etc., using CAD
- Simulation for the design thereof
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
Generation of images and models in computer graphics |
Attention is drawn to the following places, which may be of interest for search:
Layout of circuits; design at the physical level |
This place covers:
- Software-implemented user interfaces specially adapted for geometric CAD
- Hardware input/output means such as virtual reality, specially adapted for geometric CAD
Attention is drawn to the following places, which may be of interest for search:
Input arrangements or combined input and output arrangements for interaction between user and computer | |
Interaction techniques based on graphical user interfaces [GUI] |
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
Design or layout of roads |
This place covers:
- Structural design of vehicles or components or systems thereof using CAD
- Simulation for the design thereof
Note: The term "vehicles" is to be understood broadly and covers land, air, space, naval or other types of vehicles.
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
Simulators for teaching control of vehicles or other craft |
This place covers:
CAD for the design of:
- entities comprising moving parts
- entities comprising alternative configurations
- engineering tolerances, e.g. mechanical component tolerance
Simulation for the design thereof
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
Picture mesh generation |
This place covers:
Using machine learning for the purpose of CAD.
Attention is drawn to the following places, which may be of interest for search:
Machine learning per se |
This place covers:
- Using CAD for the design of circuits
- Simulation of the design thereof
- CAD relating to superconducting circuits or circuits such as rapid single flux quantum (RSFQ) circuits or other circuits using Josephson junctions
Note: The term "circuit" is to be understood broadly and covers electric, electronic, and integrated circuits as well as circuits on a printed circuit board [PCB].
Attention is drawn to the following places, which may be of interest for search:
Functional testing | |
Testing of electronic circuits |
This place covers:
CAD tools working at the analogue level.
Note:
The nature of the designed circuit (e.g. a digital circuit) is not decisive: if the CAD tool operates over continuous values (e.g. current, voltage, frequency), the subject-matter is to be classified here.
This place covers:
CAD tools operating over the physical parameters (geometry, routing, and sizing) of the circuit, considering the electrical characteristics of said circuit.
This place does not cover:
Physical level design for reconfigurable circuits |
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
Optical proximity correction [OPC] design processes |
This place covers:
CAD tools for use during the floorplanning design stage of a circuit.
Note: The term "floorplan" is used here in the context of circuit design with its generally accepted meaning and covers an early stage in the hierarchical approach to integrated circuit design regarding optimally placing a given set of circuit modules.
Floorplanning covers taking in some of the geometrical constraints in a design such as
- bonding pads for off-chip connections
- line drivers which often have to be located as close to bonding pads as possible
- minimum chip area needed to fit in the required number of pads; predetermined area blocks such as intellectual property blocks (IP-blocks)
- limitations such as permitting no routing of signals directly above an IP block
Floorplan optimisation subject to various constraints and requirements of optimisation, e.g. block areas, aspect ratios, estimated total measure of interconnects, etc.
In this place, the following terms or expressions are used with the meaning indicated:
IP block, IP core | The terms IP block and IP core are used as synonyms and relate to reusable unit of logic, cell, or integrated circuit (commonly called a "chip") layout design that is the intellectual property of one party. The term is derived from the licensing of the patent and/or source code copyright that exist in the design. IP cores can be used as building blocks within application-specific integrated circuit (ASIC) designs or field-programmable gate array (FPGA) logic designs during the floorplanning design stage of a circuit. |
This place covers:
- Text and natural language processing,
- Natural language understanding and translation,
- Processing of markup language,
- Spreadsheets.
The mere use of XML or other markup language, e.g. as a file format for functional data such as configuration files, should not be classified here, but rather in the field in which the data is actually used.
This place does not cover:
Speech analysis or synthesis, speech recognition |
Attention is drawn to the following places, which may be of interest for search:
Input/output for Oriental characters | |
Predictive input | |
Digital ink, low-level/hardware aspects thereof | |
Printing (job control, etc.) | |
Parser generation for computer code | |
Translation, e.g. compilation, of computer code | |
Parsing of computer code | |
Multilingual user interfaces | |
Text retrieval, creation of semantic tools | |
Thesaurus (creation for retrieval) | |
Retrieval of semistructured data | |
Website content management | |
Tape/Label printers (hardware) | |
Translation to/from Braille or sign language | |
Character generators for displays | |
Compression/encoding of unstructured text |
In patent documents, the following abbreviations are often used:
XML | Extensible Markup Language |
This place covers:
Manipulation of document(s) content or structure where the visual appearance or natural-language content does not play a role.
Attention is drawn to the following places, which may be of interest for search:
Compression |
This place covers:
Processing of tree-structured text documents, where the tree structure and the textual nature are both significant.
This place does not cover:
Parsing of natural language data | |
Validation of natural language data |
Attention is drawn to the following places, which may be of interest for search:
Retrieval of semi-structured data | |
Compression |
This place covers:
CAD tools specifically adapted for using IP blocks or IP cores.
In this place, the following terms or expressions are used with the meaning indicated:
IP block, IP core | The terms IP block and IP core are used as synonyms and relate to reusable unit of logic, cell, or integrated circuit (commonly called a "chip") layout design that is the intellectual property of one party. The term is derived from the licensing of the patent and/or source code copyright that exist in the design. IP cores can be used as building blocks within application-specific integrated circuit (ASIC) designs or field-programmable gate array (FPGA) logic designs during the floorplanning design stage of a circuit. |
This place covers:
Data types on which pattern recognition is applied such as time-series data.
Examples of places where the subject matter of this place is covered when specially adapted, used for a particular purpose, or incorporated in a larger system:
Analysing medical signals, e.g. bioelectric signals or blood pressure | |
Analysis of chromatographic signals | |
Processing radar or similar signals | |
Processing seismic signals | |
Transmission systems for measured values, control or similar signals |
Attention is drawn to the following places, which may be of interest for search:
Generic software techniques for error detection or fault masking by means of middleware or OS functionality involving virtual machines |
Attention is drawn to the following places, which may be of interest for search:
Error detection using active fault masking where persistent mass storage functionality is redundant by mirroring while ensuring consistency |
Attention is drawn to the following places, which may be of interest for search:
Error detection or correction using active fault masking where processing functionality is redundant without idle spare hardware |
Attention is drawn to the following places, which may be of interest for search:
Multigauge devices, i.e. capable of handling packed numbers without unpacking them |
This group and its lower subgroups are designed for use in combination with G06F 21/50.
This place covers:
Secondary and transversal aspects to G06F 21/00.
G06F 2221/03 Secondary and transversal aspects specific to G06F 21/50+
This place covers:
Logging history of events.
This place does not cover:
When the main aspect of the invention is auditing or monitoring |
Attention is drawn to the following places, which may be of interest for search:
Authentication |
This place covers:
Computer working in two or more modes, e.g. protecting platform using secure/non secure mode, user/administrator mode.
This place does not cover:
When the main aspect of the invention relates to protecting specific internal components or peripheral devices operating in dual or compartmented mode. |
This place covers:
Use of unusual or unconventional encryption techniques.
This place covers:
Specific solutions for security of games within the context of G06F 21/00, e.g. special memory game cartridge, casino machines.
Attention is drawn to the following places, which may be of interest for search:
Coin-freed apparatus for games, toys, sports or amusements |
This place covers:
When the involvement of a third party is essential.
This place covers:
Use of unusual or unconventional user registration.
Attention is drawn to the following places, which may be of interest for search:
Protecting computer platforms against harmful, malicious and unexpected behaviours or activities at application loading time |
This place covers:
e.g. a processor performs dummy operations as countermeasure to differential power analysis.
This place covers:
e.g. pretending to have connected a user to a real node when in fact the connection is to a dummy.
This place covers:
Counting events for security purposes.
Attention is drawn to the following places, which may be of interest for search:
Long-term monitoring or reporting | |
Monitoring involving event detection and direct action | |
Auditing |
This place covers:
Periodically carrying out authorization checks after initial installation or loading.
Attention is drawn to the following places, which may be of interest for search:
Protecting data against unauthorised access or modification by protecting access to a system of files or objects |
This place covers:
Concurrent access, collaborative control, e.g. when two users with different access rights concurrently edit the same document.
Attention is drawn to the following places, which may be of interest for search:
Protecting data against unauthorised access or modification by protecting access |
This place covers:
E.g. creating a user-specific working environment, parental control.
This place covers:
Use of hardware tokens, smart cards or dongles.
This place does not cover:
When used for restricting or protecting executable software | |
When for purposes of authentication |