| CPC G10L 25/84 (2013.01) [G10L 15/063 (2013.01); G10L 15/07 (2013.01); G10L 15/16 (2013.01); G10L 25/51 (2013.01); G10L 2025/783 (2013.01)] | 20 Claims |
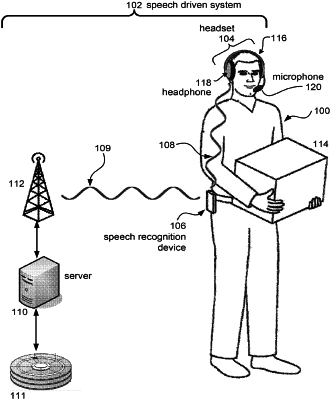
|
1. A method of speech recognition, the method comprising:
generating a normalized audio input based on an accessed audio input;
determining if the normalized audio input matches a standardized user voice, the standardized user voice based on a plurality of training samples, wherein a single training word is selected from the plurality of training samples and normalized to generate the standardized user voice;
categorizing the received audio input as a user speech originating from an operator of the SRD in an instance in which it is determined that the normalized audio input matches the standardized user voice;
comparing the received audio input against a template comprising a plurality of samples of user speech in an instance in which it is determined that the normalized audio input does not match the standardized user voice; and
categorizing the received audio input as a background sound in an instance in which it is determined that the received audio input does not match a sample of user speech.
|