| CPC G06Q 30/0185 (2013.01) [G06F 16/27 (2019.01); G06N 3/08 (2013.01); G06N 3/084 (2013.01); G06Q 30/0201 (2013.01); G06Q 30/0242 (2013.01); G06Q 30/0269 (2013.01); G06Q 30/0276 (2013.01); G06Q 50/01 (2013.01)] | 21 Claims |
|
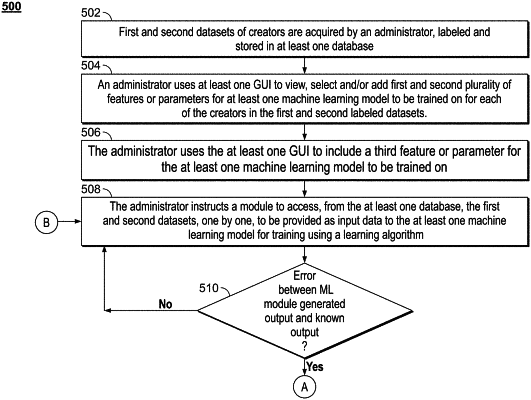
1. A method of training at least one machine learning model to classify one or more activities of a plurality of users of a social network as being fake, the method being implemented by at least one server configured to execute a plurality of programmatic instructions and comprising:
storing, in at least one database coupled to the at least one server, a first labeled dataset of a first plurality of creators and a second labeled dataset of a second plurality of creators;
identifying a first plurality of features in the first labeled dataset and a second plurality of features in the second labeled dataset;
identifying a third feature with reference to the first labeled dataset and the second labeled dataset;
providing to the at least one machine learning model data from the first labeled dataset and the second labeled dataset for training, wherein the at least one machine learning model is configured to use the first plurality of features, the second plurality of features, and the third feature to generate an output classifying said data as fake or non-fake;
determining, for each data, an error between the output generated by the at least one machine learning model and a known output, wherein the output corresponds to classifying at least one of the first plurality of creators in one of low risk, average risk, high risk or very high risk group based on a percentage of posts associated with the at least one of the first plurality of creators identified as fake;
performing back propagation, by the at least one machine learning model, based on the error to correct one or more parameters of the at least one machine learning model;
determining a first metric, a second metric and a third metric to validate a quality of the output generated by the at least one machine learning model; and
stopping the training if the first metric, the second metric and the third metric achieve a first predefined value, a second predefined value and a third predefined value, respectively.
|