| CPC G06N 5/04 (2013.01) [G06F 16/35 (2019.01); G06F 18/22 (2023.01); G06F 18/2415 (2023.01); G06N 3/044 (2023.01); G06N 3/045 (2023.01); G06N 3/08 (2013.01)] | 9 Claims |
|
1. A processor implemented method, comprising:
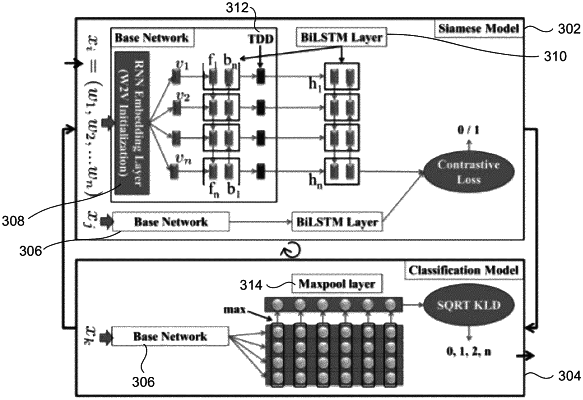
obtaining by a Bidirectional Long-Short Term Memory (BiLSTM)-Siamese network based classifier, via one or more hardware processors, one or more user queries, wherein the one or more user queries comprises of a sequence of words, wherein the BiLSTM-Siamese network based classifier comprises a Siamese model and a classification model, and wherein each of the Siamese model and the classification model comprise a common base network that includes an embedding layer, a single BiLSTM layer and a Time Distributed Dense (TDD) Layer;
iteratively performing:
representing in the embedding layer of the common base network, the one or more user queries as a sequence of vector representation of each word learnt using a word to vector model, wherein the sequence of words is replaced by corresponding vectors initialized using the word to vector model, wherein the corresponding vectors are continually updated during training of the BiLSTM-Siamese network based classifier, wherein the word to vector model is used to initialize weights of the embedding layer which takes the one or more user queries as a sequence of 1-hot encoded word vectors and outputs encoded sequence of the corresponding vectors and wherein the weights of the embedding layer are updated through back-propagation;
inputting, to the single BiLSTM layer of the common base network, the sequence of vector representation of each word to generate ‘t’ hidden states at every timestep, wherein the vector representation of each word is inputted in at least one of a forward order and a reverse order and wherein the vector representation retains context of other words both on a left hand side and a right hand side as a result at each word in the one or more user queries, and an output of a LSTM unit is controlled by a set of gates as a function of previous hidden state and input at a current timestep, and computing an internal memory as a function to decide how much information from an old memory cell is going to be forgotten along with control on how much new information is going to be stored in a current memory cell, and controls output based on the internal memory;
determining, during training of the BiLSTM-Siamese network based classifier, one or more errors pertaining to the one or more user queries, wherein the one or more errors comprise one or more target classes being determined for the one or more user queries;
generating a set of misclassified query-query pairs based on the one or more errors;
iteratively training, the Siamese model using the set of misclassified query-query pairs along with one or more correct pairs, wherein one or more weights of the common base network are shared with the Siamese model and the classification model during the training of the BiLSTM-Siamese network based classifier;
processing through the Time Distributed Dense (TDD) Layer of the common base network, an output obtained from the BiLSTM layer to obtain a sequence of vector;
obtaining, using a maxpool layer of the classification model, dimension-wise maximum value of the sequence of vector to form a final vector; and
determining by a softmax layer of the classification model, at least one target class of the one or more queries based on the final vector and outputting a response to the one or more queries based on the determined target class, wherein a Square root Kullback—Leibler divergence (KLD) Loss Function is applied to the sequence of vector to optimize the classification model by computing a cross entropy loss function between probability distribution of the sequence of vector and a target distribution of the sequence of vector, wherein the probability distribution is obtained by performing square root and normalization of predicted discrete probability distribution of the sequence of vector and wherein the target distribution is an indicator function with a value of one for the target class and zero otherwise.
|