| CPC G06N 3/084 (2013.01) [G06N 3/044 (2023.01); G06N 3/047 (2023.01)] | 20 Claims |
|
1. A method of training a recurrent neural network having a plurality of network parameters to determine trained values of the network parameters,
wherein the recurrent neural network is configured to receive a network input and to process the network input in accordance with the network parameters to generate a network output,
wherein the network input comprises a sequence that includes a respective time step input at each of a plurality of time steps, and
wherein the method comprises:
at each training iteration of a plurality of training iterations:
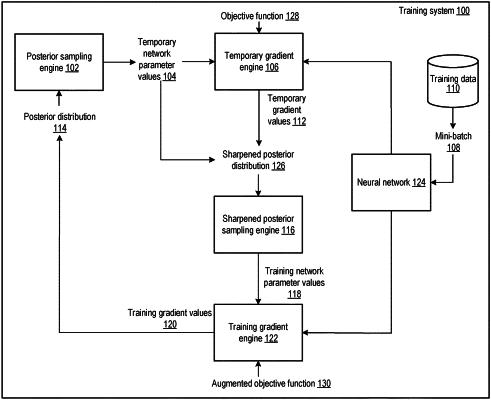
maintaining data specifying, for each of the network parameters, current values of a respective set of posterior distribution parameters that define a posterior probability distribution over possible values for the network parameter;
determining a respective temporary parameter value for each of the network parameters from the current values of the respective set of posterior distribution parameters for the network parameter;
obtaining a mini-batch comprising a plurality of training network inputs and, for each training network input, a respective training network output;
determining a respective temporary gradient value for each of the network parameters by determining a gradient of an objective function for the mini-batch and with respect to the respective temporary parameter values, comprising:
performing an iteration of a backpropagation through time training procedure on the mini-batch with the values of the network parameters set to the temporary parameter values;
updating the current values of the respective sets of posterior distribution parameters for the network parameters based at least in part on the temporary gradient values for the network parameters that are determined using the backpropagation through time training procedure comprising:
determining gradients of a measure of difference between the temporary parameter values under the posterior probability distribution and under a prior probability distribution with respect to the respective sets of posterior distribution parameters for the network parameters; and
determining an update to the current values of the respective sets of posterior distribution parameters for the network parameters as a combination of the temporary gradient values and the gradients of the measure of difference comprising:
scaling the temporary gradient values and the gradients of the measure of difference by respective scaling factors based on a product between: (i) a number of training network inputs in the mini-batch, and (ii) a number of mini-batches used during the training of the recurrent neural network; and
determining the trained values of the network parameters based on the updated current values of the respective sets of posterior distribution parameters.
|