| CPC G06F 16/906 (2019.01) [G06F 16/93 (2019.01); G06N 5/04 (2013.01); G06N 20/00 (2019.01)] | 12 Claims |
|
1. A method for classifying an unlabeled document into one of a plurality of available classes, the method implemented by an information handling system that includes a memory and a processor, the method comprising:
determining a first set of word frequencies of a first set of unique terms in the unlabeled document;
calculating a plurality of weighting factors based on analyzing the first set of word frequencies against a second set of word frequencies corresponding to a set of labeled documents, wherein the calculating comprises:
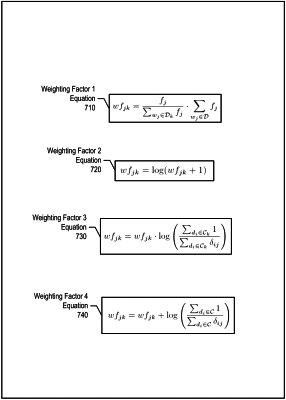
computing a first weighting factor, wherein the first weighting factor normalizes the first set of word frequencies;
computing a second weighting factor, wherein the second weighting factor applies a logarithm function over the first weighting factor to compute a set of term frequencies of the normalized first set of word frequencies;
computing a third weighting factor by multiplying the second weighting factor by an inverse document frequency corresponding to a partitioned set of labeled documents included in the set of labeled documents of each one of the plurality of available classes; and
computing a fourth weighting factor by adding an inverse document frequency transformation corresponding to the set of labeled documents to the third weighting factor;
computing an a posteriori classification probability of the unlabeled document based on the first weighting factor, the second weighting factor, the third weighting factor, and the fourth weighting factor, wherein the a posteriori classification probability corresponds to one of a plurality of probabilities that the unlabeled document belongs to a corresponding one of the plurality of available classes;
creating an inferred classifier based on the a posteriori classification probability;
classifying the unlabeled document using the inferred classifier; and
updating the second set of word frequencies based on the computed a posteriori classification probability of the unlabeled document.
|