| CPC G06F 16/284 (2019.01) [G06F 16/2379 (2019.01); G06N 3/08 (2013.01)] | 12 Claims |
|
1. A system comprising:
at least one processor; and a memory storing instructions that cause the processor to:
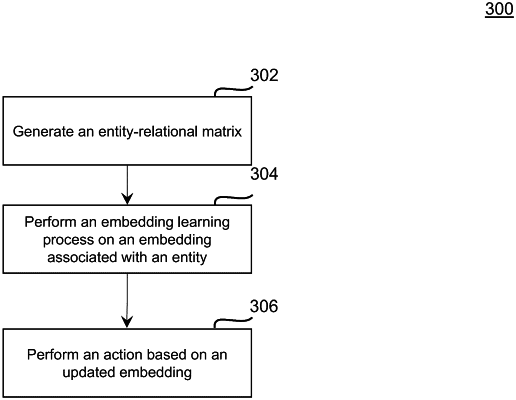
generate a plurality of entity-relation matrices from a relational database;
normalize each entity-relation matrix of the plurality of entity-relation matrices based on a term frequency-inverse document frequency (tf-idf) technique; and
perform, for each normalized entity-relation matrix of the plurality of entity-relation matrices, an embedding learning process on an embedding associated with a first entity;
wherein, when performing the embedding learning process on the embedding associated with the first entity, the at least one processor is programmed or configured to:
initialize the embedding;
perform a positive sampling process on a normalized first entity-relation matrix to provide a first sample result, wherein, when performing the positive sampling process on the normalized first entity-relation matrix, the at least one processor is programmed or configured to:
sample a pair of entities from the first entity-relation matrix based on a strength of a relationship between the pair of entities according to values of the normalized first entity-relation matrix, wherein the pair of entities comprises the first entity and a second entity, and wherein the first sample result comprises the pair of entities;
determine an entity type of the first entity included in the first sample result;
perform a negative sampling process on the relational database based on the entity type of the first entity included in the first sample result to provide a second sample result, wherein, when performing the negative sampling process on the relational database, the at least one processor is programmed or configured to:
determine a number of entities included in the relational database that have a same entity type as the entity type of the first entity included in the first sample result, wherein the second sample result comprises the number of entities;
generate an updated embedding associated with the first entity based on the first sample result and the second sample result; and
perform an action based on the updated embedding, wherein, when performing the action based on the updated embedding, the at least one processor is further programmed or configured to:
generate a machine learning model based on the updated embedding associated with the first entity, wherein, when generating the machine learning model, the at least one processor is further programmed or configured to:
use the updated embedding to provide an embedding layer of a neural network of the machine learning model.
|