| CPC G06F 11/1662 (2013.01) [G06F 3/064 (2013.01); G06F 3/0622 (2013.01); G06F 3/0679 (2013.01); G06F 11/1088 (2013.01); G06F 11/3034 (2013.01); G06F 16/27 (2019.01)] | 20 Claims |
|
1. A method comprising:
managing, by a key-value (KV) store of a first node of a plurality of nodes of a cluster of a distributed storage management system, storage of data blocks as values and corresponding block identifiers (IDs) as keys;
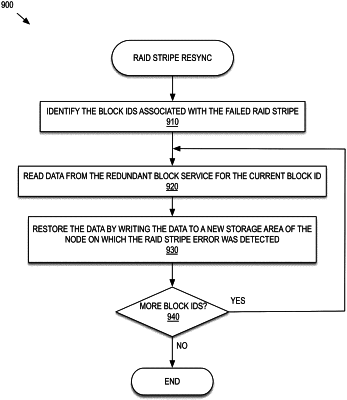
receiving, by the first node, a list of missing block identifiers (IDs) that are in use for one or more volumes but are missing from the KV store; and
causing, by the first node, a resynchronization process to be performed, including for each block ID in the list of missing block IDs:
reading a data block corresponding to the block ID from a second node of the plurality of nodes that maintains redundant information relating to the block ID; and
restoring the block ID within the KV store by writing the data block to the first node.
|