| CPC G16H 30/40 (2018.01) [G06F 18/213 (2023.01); G06F 18/214 (2023.01); G06F 18/24 (2023.01); G06N 3/08 (2013.01); G06V 10/454 (2022.01); G06V 10/764 (2022.01); G06V 10/82 (2022.01); G16H 30/20 (2018.01); G16H 50/20 (2018.01)] | 20 Claims |
|
13. A terminal device, comprising a processor and a storage medium, the processor being configured to implement instructions; and
the storage medium being configured to store a plurality of instructions, the instructions being loaded by the processor to perform:
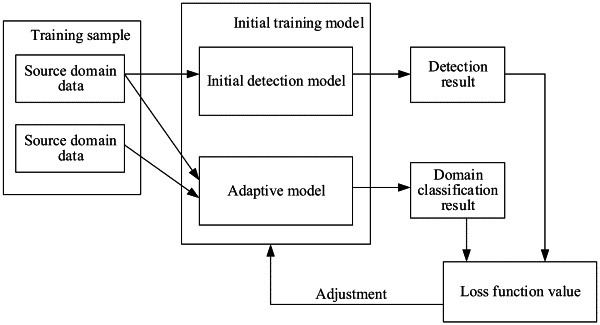
determining an initial training model, the initial training model comprising an initial detection model and an adaptive model;
obtaining a training sample, the training sample comprising source domain data and target domain data, the source domain data comprising a plurality of first images, a first image comprising: a first identifier indicating whether a target object is present, and a second identifier indicating a domain that the first image belongs to; the target domain data comprising: a plurality of second images, and a second image comprising a third identifier indicating a domain that the second image belongs to;
determining whether a target object is present in a first image through the initial detection model according to a feature of the first image, to obtain a detection result; and determining a domain that an image in the training sample belongs to through the adaptive model according to a feature of the image, to obtain a domain classification result;
calculating a loss function value related to the initial training model according to the detection result, the domain classification result, the first identifier, the second identifier, and the third identifier; and
adjusting a parameter value in the initial training model according to the loss function value, to obtain a final detection model.
|