| CPC G10L 15/26 (2013.01) [G10L 15/06 (2013.01); G10L 15/187 (2013.01); G10L 15/22 (2013.01); G10L 15/32 (2013.01); G10L 2015/088 (2013.01)] | 20 Claims |
|
1. A computer implemented method of converting an audio input into a text representation associated with a user, the method comprising:
receiving, by a conversion processor, the audio input;
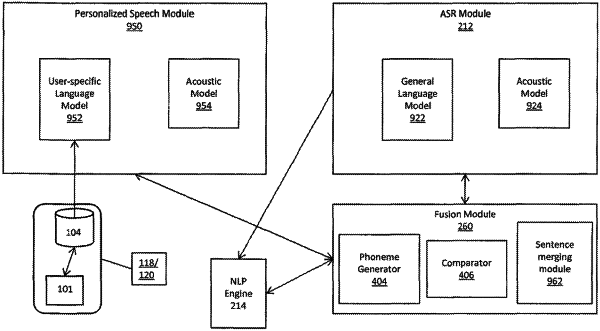
generating, by a first speech recognition processor, a first text representation of the audio input, wherein the first speech recognition processor uses a first natural language model for speech recognition of a first language;
generating, by a second speech recognition processor, a second text representation of the audio input using a second natural language model, wherein the second natural language model recognizes a word not in the first natural language model for speech recognition, the second text representation includes the word not in the first natural language model, the second text representation includes a phoneme of the word, and the second natural language model is distinct from the first natural language model;
aligning, by the conversion processor, based on a phoneme sequence associated with the first and second text representations, the first text representation and the second text representation;
generating, by the conversion processor, based at least on the aligned first and second text representations and a likelihood of the phoneme of the word being a part of the first text representation, a third text representation; and
outputting the third text representation as a personalized recognized text representation of the audio input.
|