| CPC G10L 15/22 (2013.01) [G10L 2015/223 (2013.01); G10L 2015/228 (2013.01)] | 18 Claims |
|
1. A computer-implemented method for processing a user spoken utterance, the method comprising:
training a machine-learning algorithm (MLA) to determine an action in response to the user spoken utterance, the training comprising:
generating a training set of data including a plurality of training digital objects, a given one of which includes: (i) an indication of a given training user spoken utterance received by a given training electronic device; (ii) a first training scenario hypothesis and a second training scenario hypothesis generated by a first scenario model and a second scenario model, respectively, based on the given training user utterance, the first trained scenario model and the second trained scenario model having been trained using at least partially different corpora of texts; (iii) a label assigned to each one of the first and second scenario hypothesis, the label being indicative of a respective training action to be executed by the given training electronic device in response to the given training user spoken utterance;
feeding the plurality of training digital objects to the MLA, thereby training the MLA for determining, for in-use scenario hypotheses associated with the user spoken utterance, a respective confidence level indicative of whether a given in-use scenario hypothesis is responsive to the user spoken utterance, the determining comprising:
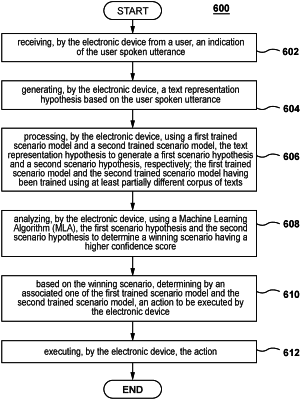
receiving, from a user, an indication of the user spoken utterance;
generating a text representation hypothesis based on the user spoken utterance;
processing using the first trained scenario model and the second trained scenario model, the text representation hypothesis to generate a first scenario hypothesis and a second scenario hypothesis, respectively;
executing the MLA to generate a first confidence score for the first scenario hypothesis and a second confidence score for the second scenario hypothesis;
determining a winning scenario as being one of the first and second scenario hypotheses having a higher confidence score;
based on the winning scenario, determining an action to be executed by an electronic device associated with the user; and
causing the electronic device to execute the action.
|