| CPC G10L 15/00 (2013.01) [G06F 3/04842 (2013.01); G06F 3/04883 (2013.01); G10L 25/51 (2013.01)] | 11 Claims |
|
1. A method performed by one or more processors of a client device, the method comprising:
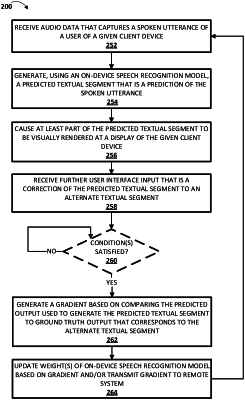
receiving, via one or more microphones of the client device, audio data that captures a spoken utterance of a user of the client device;
processing the audio data to generate a predicted textual segment that is a prediction of the spoken utterance, wherein processing the audio data to generate the predicted textual segment comprises:
processing, using a speech recognition model stored locally at the client device, the audio data to generate a predicted output, and
determining the predicted textual segment based on the predicted output;
causing at least part of the predicted textual segment to be visually rendered at a display of the client device, wherein the display is a touch-display;
receiving, responsive to the at least part of the predicted textual segment being visually rendered, further user interface input that is a correction of the predicted textual segment to an alternate textual segment, wherein the further user interface input comprises one or more touch inputs, directed at the touch-display, to modify a term of the predicted textual segment to create a modified term and/or to replace a term of the predicted textual segment with a replacement term, and wherein the alternate textual segment includes the modified term or the replacement term;
determining, based on the further user interface input, whether the correction of the predicted textual segment is directed to performance of the speech recognition model that is stored locally at the client device, wherein determining, based on the further user interface input, whether the correction of the predicted textual segment is directed to performance of the speech recognition model that is stored locally at the client device comprises:
determining a measure of similarity between the term of the predicted textual segment and the modified term or the replacement term of the alternate textual segment; and
determining that the correction is directed to performance of the speech recognition model that is stored locally at the client device based on the measure of similarity satisfying a threshold; and
responsive to the further user interface input being the correction of the predicted textual segment to the alternate textual segment and responsive to determining that the correction of the predicted textual segment is directed to performance of the speech recognition model that is stored locally at the client device:
generating a gradient based on comparing at least part of the predicted output to ground truth output that corresponds to the alternate textual segment, and
updating one or more weights of the speech recognition model based on the generated gradient.
|