| CPC G10L 13/047 (2013.01) [G10L 25/30 (2013.01)] | 7 Claims |
|
1. A GAN-based speech synthesis model, comprising
a generator, configured to be obtained by being trained based on a first discrimination loss for indicating a discrimination loss of the generator and a second discrimination loss for indicating a mean square error between the generator and a preset discriminator; and
a vocoder, configured to synthesize target audio corresponding to to-be-converted text from a target Mel-frequency spectrum,
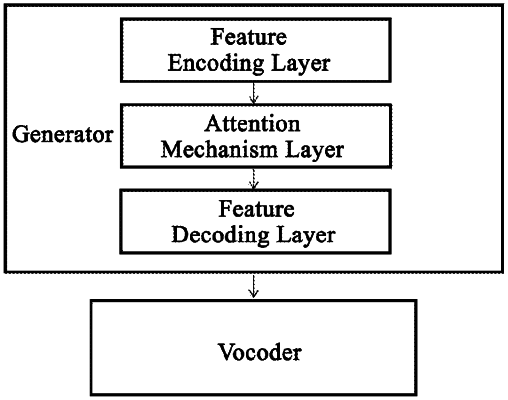
wherein the generator comprises:
a feature encoding layer, configured to obtain a text feature based on a text vector, the text vector being obtained by processing the to-be-converted text;
an attention mechanism layer, configured to calculate, based on a sequence order of the text feature, a relevance between the text feature at a current position and an audio feature within a preset range, and determine contribution values of each text feature relative to different audio features within the preset range, the audio feature being used for indicating an audio feature corresponding to a pronunciation object preset by the generator; and
a feature decoding layer, configured to match the audio feature corresponding to the text feature based on the contribution value, and output the target Mel-frequency spectrum by the audio feature.
|