| CPC G06V 10/82 (2022.01) [G06F 18/213 (2023.01); G06F 18/217 (2023.01); G06F 18/28 (2023.01); G06N 3/04 (2013.01); G06N 3/084 (2013.01); G06T 3/4053 (2013.01); G06V 10/56 (2022.01); G06V 10/7715 (2022.01)] | 20 Claims |
|
1. A method of generating an output image, the output image comprising a plurality of pixels arranged in a two-dimensional map, each pixel having a respective value for each of a plurality of channels, and the method comprising:
receiving a conditioning input;
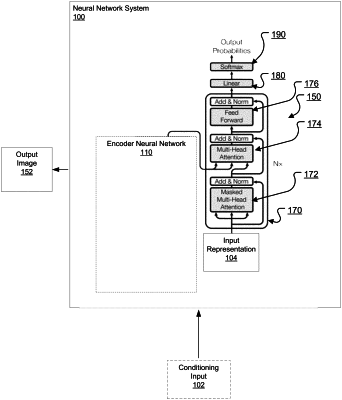
processing the conditioning input using an encoder neural network to generate a sequential conditioning representation that comprises a sequence of encoded representations;
generating a current output image representation of a current output image, wherein the current output image includes already generated values for at least a subset of the pixel channel pairs in the output image; and
processing the current output image representation using a decoder neural network to update the current output image, wherein the decoder neural network comprises a sequence of decoder subnetworks, one or more of the decoder subnetworks comprising a respective encoder-decoder attention sub-layer that is configured to receive a respective input for each of the at least the subset of the pixel channel pairs; and
generate a respective updated representation for each of the at least the subset of the pixel channel pairs by applying attention mechanism over the representations in the sequential conditioning representation using one or more queries derived from the respective inputs for each of the at least the subset of the pixel channel pairs.
|