| CPC G06N 7/01 (2023.01) [G06N 20/00 (2019.01)] | 20 Claims |
|
1. A reinforcement learning algorithm for an agent, the algorithm comprising:
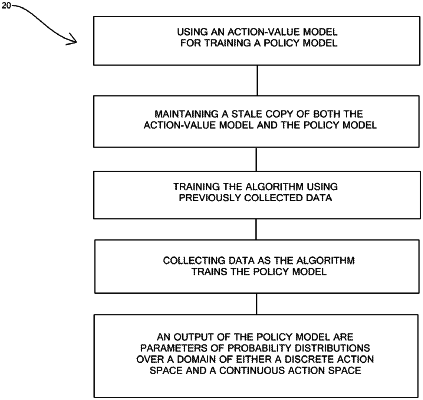
using an action-value model for training a policy model, the action-value model estimating, within one or more processors of the agent, an expected future discounted reward that would be received if a hypothetical action was selected under a current observation of the agent and the agent's behavior was followed thereafter; and
maintaining a stale copy of both the action-value model and the policy model, wherein the stale copy is initialized identically to a fresh copy of a fresh action-value model and a fresh policy model and is slowly moved to match the fresh copy as learning updates are performed on the fresh copy, wherein
the stale copy of the policy model acts as an old policy to be evaluated by the fresh action-value model;
the stale copy of the action-value model provides Q-values of an earlier policy model on which the fresh policy model improves; and
the algorithm has both an offline variant, in which the algorithm is trained using previously collected data, and an online variant, in which data is collected as the algorithm trains the policy model.
|