| CPC G06F 9/30014 (2013.01) [G06F 9/3001 (2013.01); G06F 9/3012 (2013.01); G06F 9/30036 (2013.01); G06F 9/3851 (2013.01); G06T 1/20 (2013.01)] | 20 Claims |
|
1. A processor, comprising:
an instruction cache;
an L1 cache;
an L2 cache;
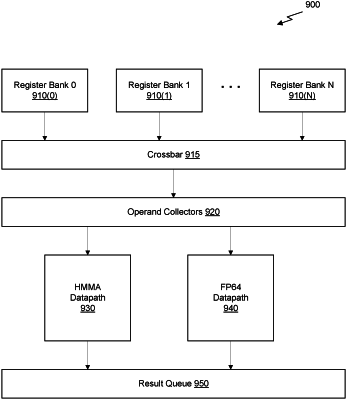
a crossbar (Xbar);
arithmetic logic units (ALUs);
a front end unit to read commands written by a host processor;
a work distribution unit to dispatch tasks to a plurality of processing clusters;
a register file to store matrices specified in a matrix-fused multiply accumulate (MFMA) instruction, wherein the MFMA instruction is to multiply a first matrix with a second matrix and sum a result with a third matrix, and wherein each element of the matrices is to be encoded as signed integer;
logic circuitry to calculate a dot product, wherein the dot product includes:
accumulating a plurality of partial products generated by multiplying each element of a first vector with a corresponding element of a second vector; and
summing the plurality of partial products with an element of a matrix; and wherein results of the MFMA instruction are to be accumulated in the register file.
|