| CPC G06F 21/563 (2013.01) [G06F 8/42 (2013.01); G06F 8/75 (2013.01); G06F 18/24 (2023.01); G06N 20/00 (2019.01)] | 20 Claims |
|
1. A system, comprising:
a processor configured to:
receive training data, wherein the training data includes a set of source code files for training a multi-representational learning (MRL) model for classifying malicious source code and benign source code based on a static analysis;
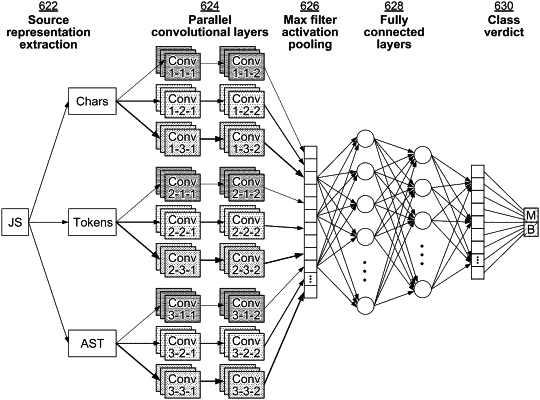
enumerate source code associated with each of the source code files into a set of characters, a set of tokens, an Abstract Syntax Tree (AST), and/or another abstraction layer;
generate a first feature vector based on the set of characters extracted from the set of source code files;
generate a second feature vector based on the set of tokens extracted from the set of source code files; and
ensemble the first feature vector and the second feature vector to form a target feature vector for classifying malicious source code and benign source code based on the static analysis, wherein each of the first feature vector and the second feature vector is of constant size regardless of a size of its original data representation, and wherein each activation map feature vector is concatenated together to form a conglomerative feature vector also of constant size that is equal to a number of filters in each parallel convolutional layer; and
a memory coupled to the processor and configured to provide the processor with instructions.
|