| CPC G06F 16/2228 (2019.01) [G06F 16/2462 (2019.01); G06F 16/24532 (2019.01); G06F 16/278 (2019.01)] | 14 Claims |
|
1. A computer-implemented method, comprising:
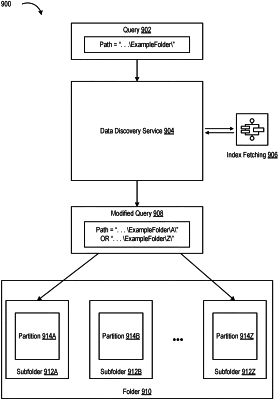
obtaining a first query on a data set of a data lake, the data set collectively stored across a plurality of partitions;
obtaining indexing information for the plurality of partitions, wherein the indexing information includes at least a first Bloom filter associated with a first partition of the data set and a second Bloom filter associated with a second partition of the data set, and a third Bloom filter associated with a third partition of the data set;
determining a filter based on the indexing information, wherein the filter excludes the first and third partitions based on the first Bloom filter and the third Bloom filter indicating the first partition and the third partition are not relevant to the first query, and wherein the filter including the second partition based on the second Bloom filter indicating the second partition is relevant to the first query;
determining a second query based on the first query and the filter; and
causing the second query to be executed in accordance with the filter.
|