|
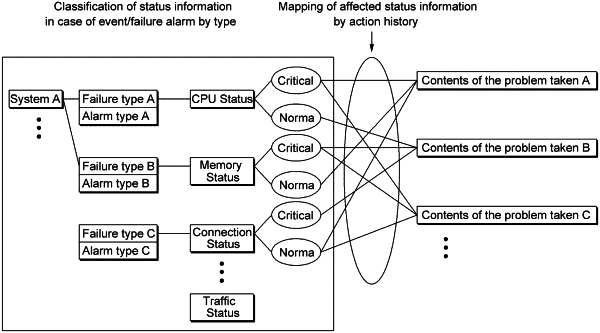
1. A system for automatically responding to an event alarm and/or a failure in information technology (IT) management in real-time, the system comprising: a management object system configured for accumulating responses an IT manager made in case of issues including the event alarm and the failure, the management object system comprising a system and an application subject to a management of the IT manager; a status collector connected with the management object system, the status collector configured to collect status information of the management object system, set a definition of a name of a server under the IT management, an internet protocol (IP) of the server, a definition of an object to be collected that displays a status of the server, a name of the object, and a status message; a controller connected with the status collector, the controller configured to make the event alarm, based on the status information, and/or the failure set by a system failure report made by a client or an operator's acknowledgment of the failure; a linker connected with the controller, the linker configured to take a role of sharing data of the event alarm or the failure made by the controller with a response measure suggester; the response measure suggester connected with the linker, the response measure suggester configured to suggest a response measure in case of the event alarm and/or the failure and predict the event alarm and/or the failure, based on data log to suggest a proactive response measure; and a responder connected with the response measure suggester, the responder configured to: select between a manual response to prevent an error of the response measure and an automatic response by a robot system; deliver the response measure to the robot system for the automatic response; and search information of a target system to access the target system included in the response measure, wherein the information of the target system includes connection information including an IP address, a login identification (ID) and a password of the system; and a ticket handling storage comprising a non-transitory computer-readable medium connected with the responder, the ticket handling storage configured to write and store a content of responses that the IT manager made in case of a problem with the system, in a format standardized to a ticket handling system, wherein a ticket handling log of the ticket handling storage includes times the issues occurred, times the response were made, phenomena of the issues, system status information at the times the issues occurred, system information that exceeded a threshold at the times before and after the issues occurred, wherein the threshold is decided by: conducting analysis on accumulated data of collected status information by extracting accumulated data value from the accumulated data in a certain period and deciding the threshold based on the analysis on the accumulated data value; or analyzing the ticket handling log, wherein the threshold sets threshold values in several levels based on level of severity to let the IT manager acknowledge it before it develops into a severe event, wherein, if a number of transmission control protocol (TCP) connections of the management object system is increased than ordinary times and affects service performance, the number of TCP connections is set as the threshold and becomes a condition that fires an event alarm, wherein if a number of operating processes is lower than a certain number and affects service and is lower than the number of operating processes at ordinary times, it acts as a condition that fires the event alarm, wherein the data is used as a learning data that suggests the response measure for the event alarm or the failure through the status collector, the controller, and the linker, wherein the learning data suggests the response measure for a corresponding event alarm or failure to the IT manager through the response measure suggester, and the automatic response is made by the responder, where the responder has an artificial intelligence function, wherein the robot system accesses the target system by using the IP address of the target system, logging-in with the login ID and the password, and automatically enters commands the operator enters, based on a response content included in the response measure, wherein the learning data includes a table of the status information categorized by a system failure type, and, at a time of the event alarm and/or the failure, the event alarm and/or the failure are matched with the system failure type in the table, wherein the system failure type is connected with at least one object related to a cause, and by status of the at least one object, the system failure type is sorted into two categories including Critical and Normal, wherein the at least one object include a central processing unit (CPU), a connection and a memory, wherein the response measure suggester connect to a part of the at least one object related to the cause, and give a verdict as Critical or Normal by the status of the at least one object, wherein a certain number of objects that are considered to be a most related object among a cause of a certain system failure type can only be selected to match with the data log, and a weight of a degree of relevance for each object is set differently by the system failure type, wherein at least one of the management object system, the status collector, the controller, the linker, and the response measure suggester includes a hardware.
|