|
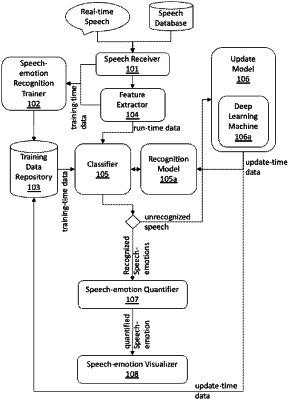
1. A computer-implemented method for training a speech-emotion recognition classifier, wherein the speech-emotion recognition classifier is implemented and executed by at least a processor and is configured to operate under a continuous self-updating and re-trainable recognition model, the method comprising: generating quantified training data for training the speech-emotion recognition classifier; comprising: obtaining an audio signal of one of a plurality of human speech source input data streams by a speech receiver; obtaining one or more texts associated with the audio signal; processing the audio signal and its associated texts in an emotion evaluation and rating process by a speech-emotion recognition trainer; normalizing the results of the emotion evaluation and rating process in an emotion state rating normalization process by the speech-emotion recognition trainer; extracting the features of the audio signal in a feature extraction process by a feature extractor implemented and executed by at least a processor; quantifying one or more emotional feature attributes of the extracted features by labelling, tagging, and weighting the emotional feature attributes, with their values assigned under measurable scales in a feature attribute quantification process by the feature extractor; and hashing the quantified emotional feature attributes in a feature attribute hashing process to obtain hash values of the quantified emotional feature attributes by the feature extractor; training the speech-emotion recognition classifier with the quantified training data; continuously updating the quantified training data and retraining the speech-emotion recognition classifier with updated quantified training data under the continuously self-updating and re-trainable recognition model; wherein the training data comprises the normalized results of the emotion evaluation and rating process, the extracted features, the quantified emotional feature attributes, and the hash values of the quantified emotional feature attributes for forming feature vectors representing the corresponding quantified emotional feature attributes and a feature vector space of the feature vectors representing an utterance in the audio signal; wherein the speech-emotion recognition classifier is a hybridized classifier implemented based on one or more Support Vector Machines (SVMs) with locality-sensitive hashing (LSH); and wherein the method for training the speech-emotion recognition classifier further comprises: forming a LSH synergized model in the hybridized classifier with an emotional feature vector space of emotional feature vectors obtained from the hash values of the quantified emotional feature attributes along with one or more search indexes of the emotional feature vectors.
|