| CPC G10L 15/26 (2013.01) [G06V 40/172 (2022.01); G10L 15/08 (2013.01); G10L 2015/088 (2013.01)] | 13 Claims |
|
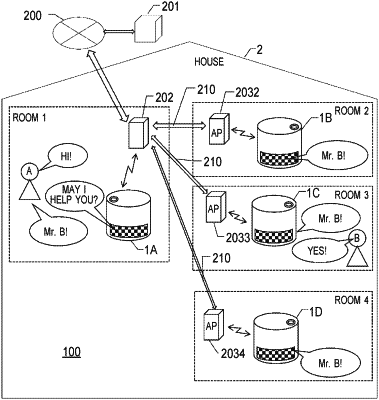
1. A speech recognition device comprising:
a sound input section;
a sound output section;
a communication control section that performs data transmission and reception with at least two other speech recognition devices;
a conversation-mode executing section that transmits, to each of the at least two other speech recognition devices, sound data input through the sound input section, and outputs, through the sound output section, sound data received from each of the at least two other speech recognition devices;
a hot word detecting section that detects, from a sound input through the sound input section, a conversation activation hot word for instructing activation of the conversation-mode executing section; and
a command transmitting section that transmits a control command to each of the at least two other speech recognition devices,
wherein the speech recognition device further comprises a storage that stores first usage data in which a person that is permitted conversation by using the speech recognition device and a number of responses of a person through each of the at least two other speech recognition devices are associated with each other, and
wherein when the sound input section receives an input of a sound for calling the person, the command transmitting section transmits the control command to each of the at least two other speech recognition devices in descending order of the number of responses through the at least two other speech recognition devices based on the first usage data.
|