| CPC G10L 15/063 (2013.01) [G10L 15/16 (2013.01); G10L 15/22 (2013.01); G10L 2015/223 (2013.01); G10L 2015/227 (2013.01)] | 20 Claims |
|
1. A computing device comprising:
memory configured to store one or more instructions; and
a processor configured to, by executing the one or more instructions,
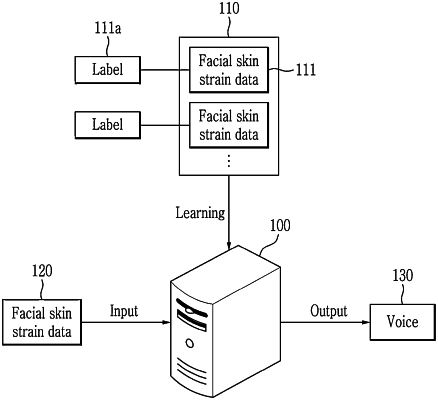
select first training data from a first training data set, the first training data set including facial skin strain data from a plurality of positions on a face;
extract first features from the facial skin strain data through a position optimization machine learning model trained to search for features of a voice in the facial skin strain data and to reduce the plurality of positions on the face to be considered to one or more positions based on a result of the search;
reduce the plurality of positions on the face to be considered by selecting the one or more positions, from among the plurality of positions, as second features through the position optimization machine learning model;
classify the voice based on the second features selected through the position optimization machine learning model, the second features including the first features at the one or more positions;
calculate a loss of the position optimization machine learning model; and
update the training of the position optimization machine learning model based on the loss.
|