| CPC G09B 19/04 (2013.01) [G09B 19/06 (2013.01); G10L 15/02 (2013.01); G10L 15/187 (2013.01); G10L 15/22 (2013.01); G09B 5/02 (2013.01); G09B 5/04 (2013.01); G09B 5/065 (2013.01); G10L 2015/025 (2013.01); G10L 2015/225 (2013.01)] | 19 Claims |
|
1. A computer-implemented method for analysing an audio signal representing speech of a user and for providing feedback to the user based on the speech, comprising:
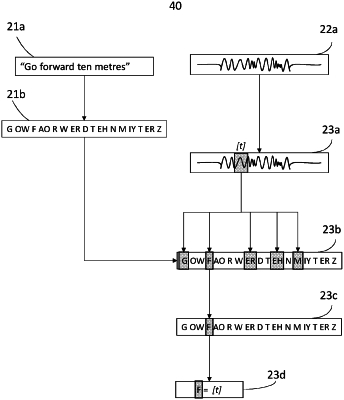
receiving a body of text;
generating a representative sequence of phonemes based at least in part on the received body of text;
receiving an input audio signal, the input audio signal including a recording of a user reading the body of text;
identifying audio components in the input audio signal, and creating a mapping between the audio components and corresponding phonemes in the representative sequence of phonemes;
generating an expected audio signal that corresponds to the representative sequence of phonemes;
based on the mapping, comparing respective audio components in the input audio signal to an expected audio component of the expected audio signal for a corresponding phoneme in the sequence of phonemes;
based on the comparison, determining a score for each audio component indicating a level of similarity between the respective audio component in the input audio signal and the expected audio component for the corresponding phoneme;
based on the respective scores for each audio component, identifying in the input audio signal a pattern of audio components where the user mispronounces a particular phoneme;
based on the identified mispronunciation of a particular phoneme, identifying a feature of the user's speech that requires direction to more accurately pronounce the particular phoneme; and
providing feedback to the user based on the identified feature of the user's speech.
|