| CPC G06T 7/10 (2017.01) [G06F 17/15 (2013.01); G06N 3/045 (2023.01); G06T 2207/20084 (2013.01)] | 12 Claims |
|
1. A method, comprising:
receiving an input image;
processing the input image with a deep learning model to generate a segmented image, wherein weights of the deep learning model are updated during training of the deep learning model according to a custom loss function determined based on segmented images output by the deep learning model, autoencoder output images generated by inputting the segmented images to a shape regularization network, and ground truth images; and
presenting the segmented image via a display unit;
wherein the deep learning model comprises a triad of predictors including a shape model, a foreground model, and a background model, wherein respective weights of the triad of predictors are updated during joint training of the triad of predictors of the deep learning model according to a joint loss function including the custom loss function, wherein the input image is processed with the shape model of the deep learning model to generate the segmented image.
|
|
8. A method, comprising:
receiving an input image;
processing the input image with a deep learning model to generate a segmented image, wherein weights of the deep learning model are updated during training of the deep learning model according to a custom loss function determined based on segmented images output by the deep learning model, autoencoder output images generated by inputting the segmented images to a shape regularization network, and ground truth images; and
presenting the segmented image via a display unit;
wherein the custom loss function includes a projection error cost term based on a distance between a predicted shape and a shape space, a representation error cost term based on a distance between an encoded representation of a ground truth segmentation mask and an encoded representation of a predicted mask, and a Euclidean cost term based on a distance between the ground truth segmentation mask and the predicted mask.
|
|
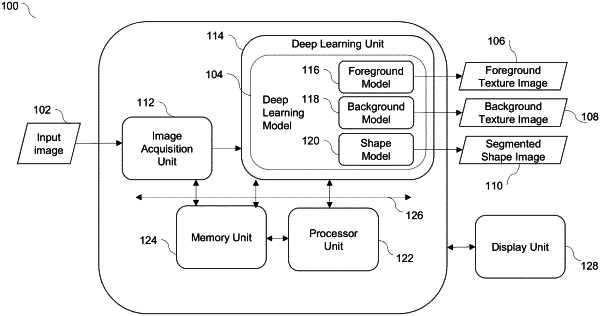
9. A system, comprising:
an image acquisition unit configured to acquire an input image;
a display unit;
a deep learning unit comprising a deep learning model, wherein weights of the deep learning model are updated during training of the deep learning model according to a custom loss function determined based on segmented images output by the deep learning model, autoencoder output images generated by inputting the segmented images to a shape regularization network, and ground truth images, wherein the deep learning unit is configured to process the input image with the deep learning model to generate a segmented image; and
a processor unit communicatively coupled to the deep learning unit and the display unit, wherein the processor unit is configured to present the segmented image via the display unit;
wherein the deep learning model comprises a triad of predictors including a shape model, a foreground model, and a background model, wherein respective weights of the triad of predictors are updated during joint training of the triad of predictors of the deep learning model according to a joint loss function including the custom loss function, wherein the deep learning unit processes the input image with the shape model of the deep learning model to generate the segmented image.
|