| CPC G06T 1/20 (2013.01) [G06T 15/005 (2013.01)] | 18 Claims |
|
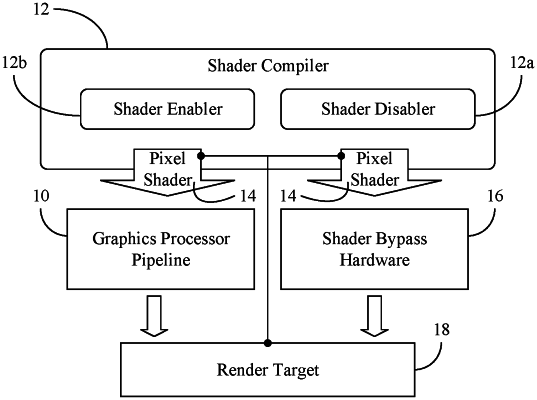
1. An apparatus comprising:
a host processor including a shader compiler to generate a pixel shader;
shader bypass hardware separate from a graphics processor pipeline to bypass the graphics processor pipeline, the shader bypass hardware comprising logic, the logic to:
receive the pixel shader when one or more of the pixel shader or a render target satisfy a simplicity condition;
send one or more data read requests of the pixel shader to a sampler;
perform one or more fixed-function mathematical operations on the sampled data; and
write an output of the pixel shader to the render target,
wherein the simplicity condition includes a precision level of the render target being below a predetermined precision threshold.
|