| CPC G06Q 10/04 (2013.01) [G06Q 40/02 (2013.01)] | 20 Claims |
|
1. A computer-implemented method for utilizing a value-based predictive input for a prediction entity of a plurality of prediction entities to reduce complexity of entity-level prediction data through selection of a subset of prediction engines with highest scaled regression values, the computer-implemented method comprising:
executing, by one or more processors, a machine learning algorithm trained using gradient descent, wherein executing the machine learning algorithm comprises:
generating the entity-level prediction data for the prediction entity based at least in part on raw transactional data and one or more entity-level aggregation rules;
generating aggregated entity-level data for the prediction entity based at least in part on aggregating the entity-level prediction data;
generating, based at least in part on the aggregated entity-level data, the value-based predictive input;
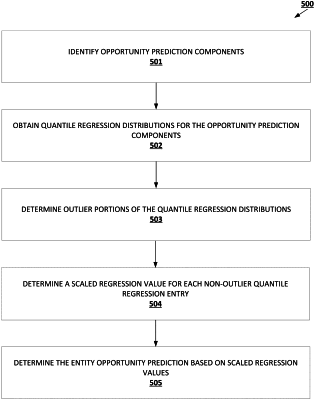
determining, based at least in part on the value-based predictive input, a plurality of predictive component values;
for each predictive component value of the plurality of predictive component values:
obtaining a quantile regression distribution for the predictive component value,
wherein the quantile regression distribution indicates a distribution of a corresponding predictive component that is associated with the predictive component value across the plurality of prediction entities via a plurality of quantile regression values,
determining a non-minimum ratio for the quantile regression distribution as a ratio of a non-minimum portion of the quantile regression distribution that falls below or equals a minimum threshold value,
determining a non-outlier ratio for the quantile regression distribution based on a deviation between a full ratio and a product of the non-minimum ratio and an outlier parameter,
determining a non-outlier portion of the quantile regression distribution as a subset of the quantile regression distribution that comprises each segment of the quantile regression distribution whose respective quantile regression values fall below or equals the non-outlier ratio, and
generating, for each quantile regression value of the plurality of quantile regression values that is in the non-outlier portion, respective scaled quantile regression values based on the quantile regression value, the predictive component value, and a quantile regression ratio for the quantile regression value;
providing, by the one or more processors, the respective scaled quantile regression values, to a plurality of prediction engines;
selecting, by the one or more processors, from among the plurality of prediction engines, the subset of prediction engines with the highest quantile regression values as a most predicted value corresponding to the prediction entity;
determining, by the one or more processors and based at least in part on the selected prediction engines, one or more entity predictions for the prediction entity; and
presenting, by the one or more processors, a prediction report associated with the one or more entity predictions to a user device.
|