| US 11,809,992 B1 | ||
| Applying compression profiles across similar neural network architectures | ||
| Gurumurthy Swaminathan, Redmond, WA (US); Ragav Venkatesan, Seattle, WA (US); Xiong Zhou, Bothell, WA (US); Runfei Luo, Kirkland, WA (US); and Vineet Khare, Redmond, WA (US) | ||
| Assigned to Amazon Technologies, Inc., Seattle, WA (US) | ||
| Filed by Amazon Technologies, Inc., Seattle, WA (US) | ||
| Filed on Mar. 31, 2020, as Appl. No. 16/836,376. | ||
| Int. Cl. G06N 3/08 (2023.01); G06N 3/082 (2023.01); G06N 3/045 (2023.01) | ||
| CPC G06N 3/082 (2013.01) [G06N 3/045 (2023.01)] | 20 Claims |
|
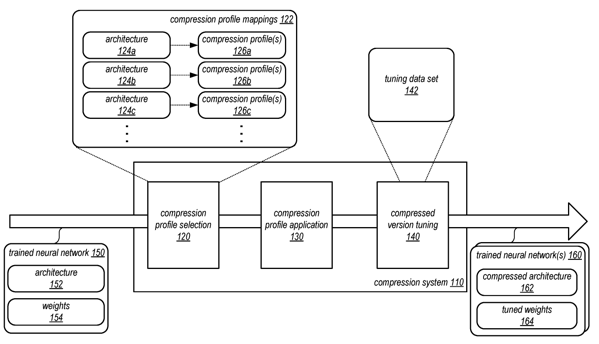
5. A method, comprising:
receiving a request to compress a trained neural network at a compression system for trained neural networks; identifying, by the compression system, an architecture of the trained neural network; comparing, by the compression system, the architecture of the trained neural network with individual ones of a plurality of different network architectures to select a compression profile out of a plurality of different compression profiles for the trained neural network according to the comparison, wherein the plurality of different compression profiles comprise different respective information useable to determine which feature to remove from a given architecture; applying, by the compression system, the compression profile to remove one or more features of the architecture of the trained neural network to generate a compressed version of the trained neural network; training, by the compression system, the compressed version of the trained neural network with a tuning data set for the neural network; and sending the trained and compressed version of the trained neural network to an identified destination. |