| CPC G06F 9/46 (2013.01) [G05B 13/0265 (2013.01); G06N 3/006 (2013.01); G06N 3/08 (2013.01); G06N 7/01 (2023.01)] | 5 Claims |
|
1. A control device comprising:
processing circuitry configured to
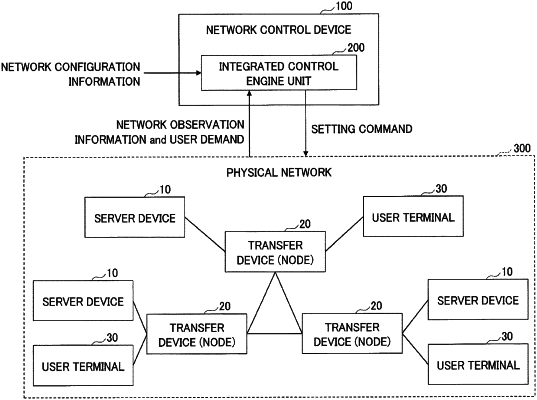
implement a plurality of control engines each configured to control one or more virtual elements, acting as control targets, that are arranged on a physical network and different than the control engines, each of the control targets being at least one of a path, a virtual resource (VR), and a virtual network function (VNF);
calculate for each control target a control solution for controlling said each control target, the control solution being information representing the amounts of the physical resources of the physical network allocated to the control targets;
calculate, for each control engine, an evaluation of the control solution for said each control target by inputting the control solution into an objective function;
change the control solution based on the calculated evaluation; and
control said each control target based on the changed control solution,
wherein the control device is
connected to the physical network,
receives network observation information from the physical network, and
automatically controls arrangement of a virtual network function in the physical network based on the network observation information, and
wherein the processing circuitry calculates an overall evaluation from the calculated evaluation from each control engine, and based on the overall evaluation, changes the control solution, the overall evaluation being optimal solution based on the calculated evaluations of the control solution for said each control target calculated for each control engine,
wherein the processing circuitry is configured to
implement an information sharing engine that outputs the optimal solution to each control engine, the information sharing engine including one or more agent units configured to learn to change the control solution through reinforcement learning, to change the control solution based on the overall evaluation for said each control target, and
learn to select one agent unit from among the one or more agent units through reinforcement learning, to issue a command to the selected one agent unit to execute learning.
|