| CPC G06F 40/20 (2020.01) [G06F 40/263 (2020.01); G06F 40/295 (2020.01); G06F 40/30 (2020.01); G06F 40/51 (2020.01); G06F 40/58 (2020.01); G06F 40/268 (2020.01)] | 20 Claims |
|
1. A computer-implemented method for processing a text, the method comprising:
receiving an input text, wherein the input text relates to a target language;
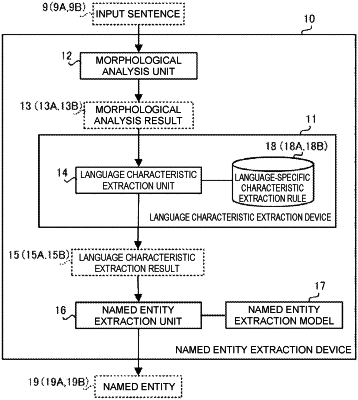
generating a morphological analysis result of the input text;
selecting, based on characteristics of the target language of the input text, a first rule from a set of abstract rules common across a plurality of languages, wherein the plurality of languages include the target language;
determining, based on the selected first rule, a second rule for the target language, wherein the second rule relates to a rule for a language-specific characteristic extraction, and wherein the rule for a language-specific characteristic extraction includes a method for a feature extraction and a condition for output specific to the target language;
determining, based on the second rule for the target language, a feature of the input text, wherein the second rule includes extracting a characteristic of a representation or a part of speech in the morphological analysis result; and
providing the feature of the input text as a result of extracting language characteristics of the input text.
|