| CPC G06F 16/254 (2019.01) [G06F 16/16 (2019.01)] | 20 Claims |
|
1. A system for pre-processing data from different input sources and with different configurations using a single set of executable code, the system comprising:
one or more memories; and
one or more processors, coupled to the one or more memories, configured to:
receive configuration information that includes a first data set configuration and a second data set configuration, wherein the first data set configuration indicates information for pre-processing data in a first manner and the second data set configuration indicates information for pre-processing data in a second manner,
wherein the first data set configuration indicates a first output location;
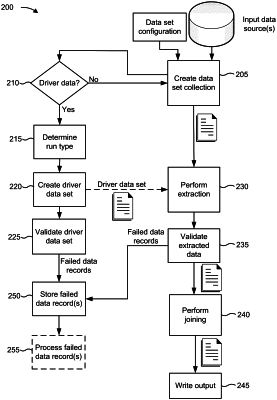
receive a first set of input data files based on the first data set configuration;
receive a second set of input data files based on the second data set configuration;
process, by executing the single set of executable code and based on the first data set configuration, the first set of input data files, wherein processing the first set of input data files includes extracting desired data from the first set of input data files and joining the desired data into a first output file,
wherein the one or more processors, to process the first set of input data files, are configured to:
determine that the first set of input data set files includes an input driver data set,
generate, based on determining that the first set of input data files includes the input driver data set, a driver data set using the first set of input data files,
wherein the driver data set is used to identify data records or identifiers to be included in the first output file,
identify one or more failed records based on identifying that one or more data records or identifiers indicated by the first data set configuration are not included in the data driver set, and
store the one or more failed records in a reconciliation data store indicated by the first data set configuration;
process, by executing the single set of executable code and based on the second data set configuration, the second set of input data files, wherein processing the second set of input data files includes extracting desired data from the second set of input data files and joining the desired data into a second output file,
wherein the single set of executable code pre-processes the second data set configuration without modification to the single set of executable code;
transmit the first output file based on the first data set configuration,
wherein transmitting the first output file includes writing the first output file to the first output location indicated by the first data set configuration; and
transmit the second output file based on the second data set configuration.
|