| CPC G06F 16/24578 (2019.01) [G06F 16/243 (2019.01); G06F 16/9035 (2019.01); G10L 15/22 (2013.01); H04M 3/4936 (2013.01); G10L 2015/223 (2013.01); G10L 2015/228 (2013.01)] | 17 Claims |
|
1. A method implemented by one or more processors, the method comprising:
processing audio data that captures a spoken utterance of a user and that is detected via one or more microphones of a client device;
determining, based on processing the audio data, that the spoken utterance includes a vague request for personal entries that are assigned to a particular type, without specifying any additional features, of the personal entries, that are in addition to the particular type, wherein the vague request for the personal entries that are assigned to the particular type does not specify any of: a temporal feature for the personal entries, a location feature for the personal entries, a creation feature for the personal entries, or an assignment feature for the personal entries;
in response to determining that the spoken utterance includes the vague request for the personal entries that are assigned to the particular type, without specifying the additional features:
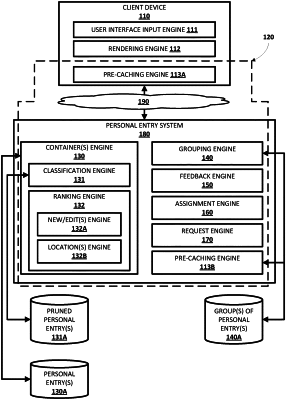
selecting, from a group of personal entries that are each access-restricted, personal to the user, and assigned to the particular type, only a subgroup of the personal entries, wherein selecting only the subgroup of the personal entries comprises:
accessing a data structure that:
for each personal entry of the group of personal entries, assigns the personal entry as a member of only a corresponding subset of containers and from among a plurality of disparate containers, the corresponding subset of containers being for the particular type and being assigned container rankings that ranks the plurality of disparate containers relative to one another, and
for each container, of the plurality of disparate containers, that is non-empty and that includes at least two of the personal entries assigned as members, ranks assigned personal entries based on personal entry rankings that rank the assigned personal entries assigned as members, of the container, relative to one another;
selecting, based on the container rankings, multiple non-empty containers of the plurality of disparate containers, and
selecting, based on the personal entry rankings and from the selected multiple non-empty containers of the plurality of disparate containers, the personal entries to include in the subgroup, and the personal entries selected for inclusion in the subgroup being selected from at least two non-empty containers from the multiple non-empty containers; and
causing a representation of at least one of the personal entries, of the subgroup, to be rendered at the client device as an initial response to the spoken utterance.
|