| CPC G06F 16/24575 (2019.01) [G06F 16/285 (2019.01); G06F 16/313 (2019.01); G06F 16/93 (2019.01); G06N 5/00 (2013.01); G06Q 10/10 (2013.01); G06Q 30/02 (2013.01); G06Q 30/0281 (2013.01); G06Q 50/01 (2013.01); Y10S 707/99936 (2013.01); Y10S 707/99945 (2013.01)] | 16 Claims |
|
1. A computer-implemented method, comprising:
identifying, using a spider component of a server and based on character matching algorithms or text matching algorithms, a match between:
(i) a content of a document stored within one or more data repositories, and
(ii) an affinity of a user;
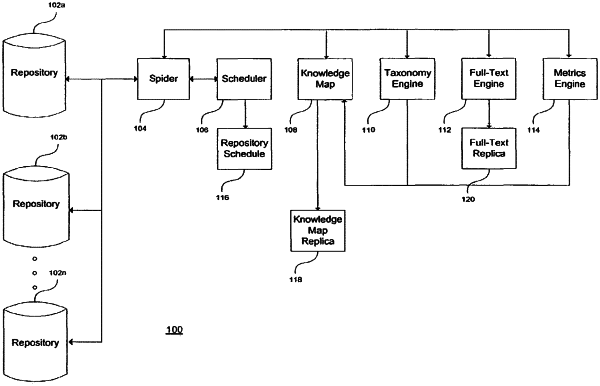
gathering, by the spider component of the server, using a knowledge map, and from the one or more data repositories, one or more documents with contents that match the affinity of the user;
modifying, by the spider component of the server, the knowledge map by registering the gathered one or more documents with the knowledge map, the knowledge map being used to perform a search based on a search string to determine one or more of a document or an affinity of a user that match the search string;
converting, by the spider component of the server, the gathered one or more documents into meta-documents by extracting the meta-documents from the gathered one or more documents in XML format, the meta-documents may include metrics information from the one or more document;
analyzing, by the spider component of the server, the meta-documents to determine types of the gathered one or more documents; and
notifying, by the spider component of the server, the user that the one or more documents with contents that match the affinity of the user have been gathered.
|