| CPC G06F 16/1752 (2019.01) [G06F 3/0608 (2013.01); G06F 3/0641 (2013.01); G06F 3/0649 (2013.01); G06F 3/0685 (2013.01); G06F 16/152 (2019.01)] | 11 Claims |
|
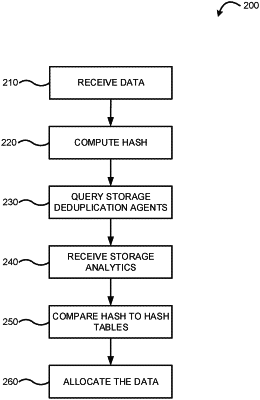
1. A computer-implemented method comprising:
receiving data to be stored in a storage environment;
computing a hash relating to the received data;
querying storage deduplication agents for storage analytics from storage systems within the storage environment;
receiving the storage analytics from the storage deduplication agents, wherein the storage analytics include hash tables for the storage systems containing deduplicated data;
comparing the hash to the hash tables to detect similarities;
determining a performance requirement related to deduplication rates for a storage tier for the received data, wherein the determining comprises determining when the storage tier is a flash-based system, a disk storage system, and a tape library system;
analyzing performance capabilities relating to the storage systems for the storage tier by relating, to the storage tier, a media type selected from the group consisting of flash-based, disk, and tape;
monitoring deduplication performance analytics relating to the deduplication rates of the storage systems for the storage tier;
allocating the received data to the storage system based on the similarities relating to the hash and the hash table, the performance requirement for the received data, and the performance capabilities relating to the storage systems to optimize the available storage capacity within the storage systems;
detecting a performance degradation relating to storage capacity from at least one storage system based on the storage analytics received;
calculating unduplicated data within the at least one storage system;
determining a different storage system within the storage environment to migrate the unduplicated data onto;
migrating the unduplicated data to the different storage system;
analyzing the hash tables to determine similarities between stored data across the storage environment;
detecting similar data based on the hash tables stored in separate storage systems; and
migrating the similar data to one storage system.
|