| CPC G06F 13/4068 (2013.01) [G06N 3/04 (2013.01)] | 14 Claims |
|
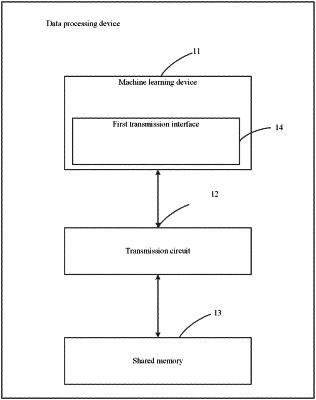
1. A data processing device, comprising a machine learning device, a transmission circuit, and a shared memory, wherein the machine learning device is connected to the transmission circuit through a first transmission interface, and the transmission circuit is connected to the shared memory;
the transmission circuit is configured to obtain input data required by the machine learning device from the shared memory according to a data operation signal sent by the machine learning device, and return the input data to the machine learning device, where the data operation signal represents an operation mode for data in the shared memory;
wherein the transmission circuit includes: a second transmission interface, at least one read/write processing circuit connected to the second transmission interface, and an arbitration circuit connected to the read/write processing circuit the at least one machine learning unit is connected to the transmission circuit through a connection between the first transmission interface and the second transmission interface;
the read/write processing circuit is configured to receive the data operation signal sent by the at least one machine learning unit through the first transmission interface and the second transmission interface, transmit the data operation signal to the arbitration circuit, and transfer the data read from the shared memory to the at least one machine learning unit through the second transmission interface; and
the arbitration circuit is configured to arbitrate the data operation signal received from the at least one read/write processing circuit according to a preset arbitration rule, and operate the data in the shared memory according to the data operation signal that has been successfully arbitrated.
|