| CPC G10L 15/26 (2013.01) [G10L 13/00 (2013.01); G10L 13/086 (2013.01); G10L 15/005 (2013.01); G10L 15/18 (2013.01); G10L 2015/088 (2013.01)] | 20 Claims |
|
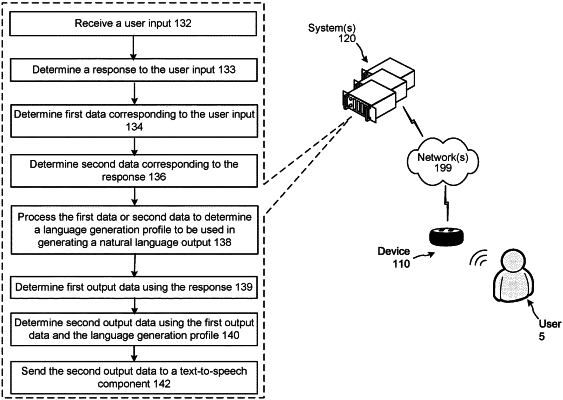
1. A computer-implemented method comprising:
receiving, from a first device, first audio data representing a first utterance;
determining first output data responsive to the first utterance, the first output data being a first natural language output including a first plurality of words;
determining the first device corresponds to a first location;
identifying, using a model configured to determine a language generation profile, a first language generation profile associated with the first location, wherein the model was trained using location data and a plurality of language generation profiles;
using a natural language generation (NLG) component, processing the first output data to determine second output data representing a second natural language output, wherein processing the first output data comprises:
determining the first language generation profile represents a first word to be inserted in the first natural language output,
determining the first language generation profile represents a position indicating that the first word is to be inserted after the first plurality of words, and
determining the second output data to include the first plurality of words followed by the first word;
processing, using text-to-speech (TTS) processing, the second output data to determine first output audio data representing first synthesized speech; and
sending the first output audio data to the first device.
|