| CPC G10L 13/027 (2013.01) [G10L 13/00 (2013.01); G10L 13/047 (2013.01); G10L 13/07 (2013.01)] | 20 Claims |
|
1. A method of converting a first singing voice to a second singing voice, comprising:
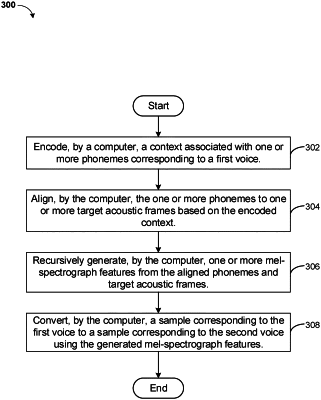
encoding, by a computer, a context associated with one or more phonemes corresponding to the first singing voice and outputting a sequence of one or more hidden states containing a sequential representation associated with the one or more phonemes;
aligning, by the computer, the one or more phonemes to one or more target acoustic frames based on the encoded context;
recursively generating, by the computer, one or more mel-spectrogram features from the aligned one or more phonemes and the one or more target acoustic frames; and
converting, by the computer, a sample corresponding to the first singing voice to a sample corresponding to the second singing voice using the generated one or more mel-spectrogram features,
wherein the aligning the one or more phonemes to the one or more target acoustic frames comprises expanding the one or more hidden states of the output sequence based on a duration associated with each phoneme, and aligning the expanded one or more hidden states to the one or more target acoustic frames.
|