| CPC G06Q 10/0635 (2013.01) [G06F 16/9536 (2019.01); G06N 5/01 (2023.01); G06N 5/04 (2013.01); G06N 7/01 (2023.01); G06N 20/00 (2019.01); G06Q 10/10 (2013.01); G06Q 30/0283 (2013.01)] | 17 Claims |
|
1. A computer-implemented method for identifying comparables, the method comprising:
implementing a machine learning algorithm operating on a computer processor configured to:
collect, through an electronic interface, input data from a plurality of electronic data sources of a potential comparable for inclusion into a transfer pricing benchmarking set, wherein the transfer pricing benchmarking set is generated by a transfer pricing benchmarking activity which comprises search and selection of unrelated parties to establish a benchmark for the pricing of a cross-border transaction between one or more related parties under common ownership or control, wherein the electronic data sources include: a business description from a commercially available database, financial data of the potential comparable, and a SIC or NACE code associated with the potential comparable;
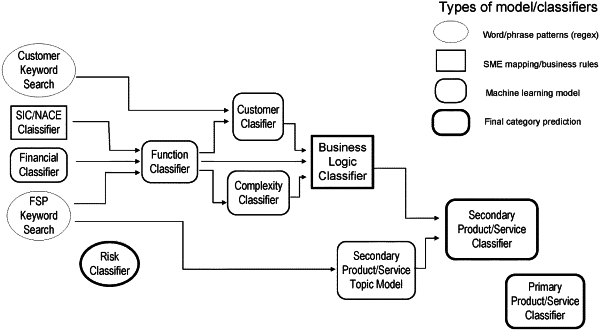
determine, via the machine learning algorithm, a function, product, and service of the potential comparable using a corresponding function classifier, product classifier, and service classifier;
receive, through the electronics interface, attributes of a tested party;
automatically execute, via the machine learning algorithm, a scoring process to calculate a similarity score for the potential comparable, wherein the similarity score represents a similarity between the potential comparable and the tested party;
automatically generate, via the machine learning algorithm, a recommendation to accept the potential comparable as an acceptable comparable for transfer pricing benchmarking, reject the potential comparable as a rejected comparable, or subject the potential comparable to further review; and
generate, via the machine learning algorithm, synthetic training data for the machine learning algorithm by (1) predicting a plurality of labels and keyword counts from the plurality of electronic data sources, (2) generating heuristic labels for the predicted plurality of labels based on a plurality of heuristic rules, the rules based on experience with prior similar problems, and (3) generating probabilistic training labels for a semi-supervised deep learning model; and
improve the machine learning algorithm by using the synthetic training data and feedback from the automatically generated recommendation to train the machine learning algorithm.
|