| CPC G06F 40/279 (2020.01) [G06V 10/7715 (2022.01); G06V 20/63 (2022.01)] | 12 Claims |
|
1. A method for performing question answering (QA) with multi-modal information, the method performed by a computing device, the method comprising:
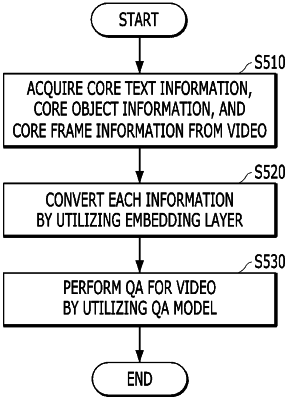
determining core text information from a video based on question data;
determining core object information or core frame information from the video based on the core text information; and
performing QA for the video based on the determined core text information, and the determined core object information or core frame information by utilizing a QA model,
wherein the determining core text information from the video based on question data includes:
extracting a keyword related to the question data in the text included in the video,
wherein the extracting the keyword related to the question data in the text included in the video includes:
extracting an important word in a field to which the question data belongs from a database, and
extracting the keyword related to the question data in the text based on the extracted important word,
wherein the QA model includes one or more embedding layers, and
the performing QA for the video based on the determined core text information, and the determined core object information or core frame information by utilizing a QA model includes:
converting the core text information, the core object information, and the core frame information into information having the same feature and dimension by utilizing the embedding layer, and
generating answer data based on the information having the same feature and dimension by utilizing the QA model.
|