| CPC B25J 9/163 (2013.01) [G06N 3/008 (2013.01); G06N 3/045 (2023.01); G06N 3/08 (2013.01); G05B 2219/39536 (2013.01)] | 18 Claims |
|
1. A method implemented by one or more processors, comprising:
identifying a desired object semantic feature;
generating a candidate end effector motion vector defining motion to move a grasping end effector of a robot from a given pose to an additional pose;
identifying an image captured by a vision component of the robot, the image capturing the grasping end effector and an object in an environment of the robot;
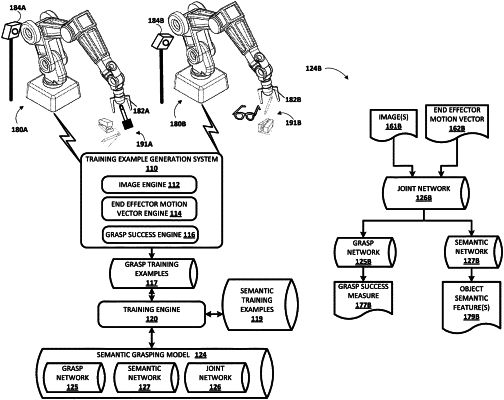
applying the image and the candidate end effector motion vector as input to a trained joint neural network;
generating a joint output based on the application of the image and the end effector motion vector to the trained joint neural network,
wherein the trained joint neural network is trained based on:
grasp losses generated based on grasp predictions generated over a grasp neural network based on training outputs generated using the joint neural network, and
semantic losses generated based on semantic predictions generated over a semantic neural network based on training outputs generated using the joint neural network;
applying the joint output to a trained version of the semantic neural network;
generating, using the trained version of the semantic neural network based on the joint output, semantic neural network output that indicates whether the object includes the desired object semantic feature;
generating a grasp success measure, generating the grasp success measure comprising:
generating the grasp success measure based on application of the joint output to a trained version of the grasp neural network, or
generating the grasp success measure based on application of the current image and the end effector motion vector to an additional trained grasp neural network;
generating an end effector command based on the grasp success measure and the semantic model output that indicates whether the object includes the desired object semantic feature; and
providing the end effector command to one or more actuators of the robot.
|