| CPC G10L 15/1815 (2013.01) [G06F 16/687 (2019.01); G10L 15/22 (2013.01); G10L 2015/223 (2013.01)] | 20 Claims |
|
1. A system comprising:
computer-readable memory storing executable instructions; and
one or more processors in communication with the computer-readable memory and configured by the executable instructions to at least:
receive audio data from a voice-enabled device, wherein the audio data represents an utterance;
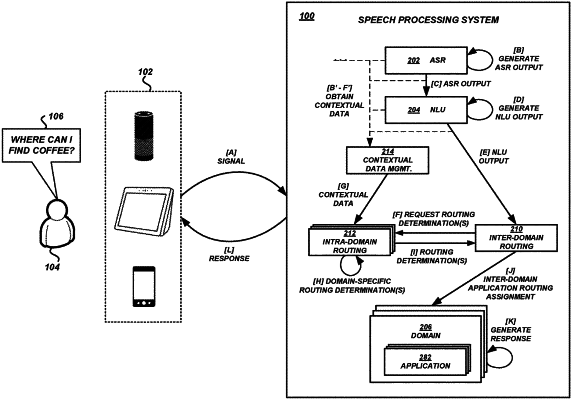
execute a set of natural language processing actions based at least partly on the audio data to generate intent data comprising a plurality of semantic representations of the utterance;
identify a first domain of an intent processing application hierarchy based at least partly on an association of the first domain with a semantic representation of the plurality of semantic representations,
wherein the intent processing application hierarchy comprises a plurality of domains,
wherein the first domain comprises a plurality of general request applications configured to generate responses to utterances associated with the semantic representation, and
wherein a specific request application within the intent processing application hierarchy and outside the first domain is configured to generate responses to utterances associated with the semantic representation;
determine that the utterance fails to satisfy a specific request criterion associated with the specific request application;
determine that a contextual data item associated with the utterance satisfies a location criterion associated with a first general request application;
determine that the contextual data item fails to satisfy a location criterion associated with a second general request application; and
assign the first general request application to generate a response.
|