| CPC G10L 15/16 (2013.01) [G06N 3/08 (2013.01); G10L 15/183 (2013.01); G10L 15/22 (2013.01)] | 20 Claims |
|
1. A system, comprising:
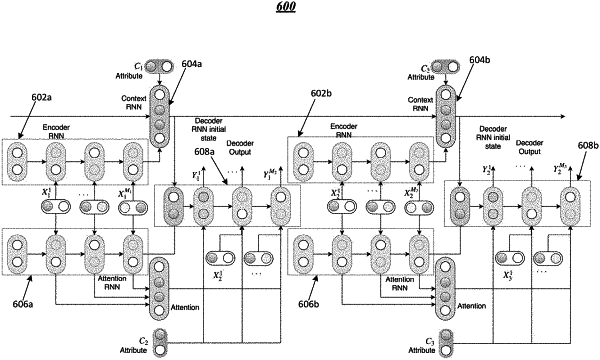
a generative adversarial network having
generator logic, the generator logic including:
a context recurrent neural network (cRNN),
an encoder recurrent neural network (eRNN),
an attention recurrent neural network (aRNN), and
and a decoder recurrent neural network (dRNN); and
discriminator logic coupled to the generator logic;
a network interface coupled to the generative adversarial network, wherein the network interface is configured to receive a dialogue utterance from a device external to the system; and
processing circuitry configured to implement the generator logic and the discriminator logic and coupled to the network interface, wherein the generator logic and the discriminator logic that when executed cause the processing circuitry to:
receive, via the network interface, the dialogue utterance;
generate, using the generator logic, response candidates responsive to the dialogue utterance, wherein:
the cRNN is applied to concatenate a source attribute with an output of the eRNN to generate an initial state for the dRNN, and
the dRNN generates the response candidates based on the initial state;
determine, using the discriminator logic, a response to the dialogue utterance from the response candidates; and
output, via the network interface, the response to the dialogue utterance to a user device.
|