| CPC G10L 13/08 (2013.01) [G06N 3/044 (2023.01); G06N 3/045 (2023.01); G06N 3/082 (2013.01); G10L 13/027 (2013.01); G10L 25/30 (2013.01); G06F 40/242 (2020.01); G06N 3/02 (2013.01); G06N 3/047 (2023.01)] | 20 Claims |
|
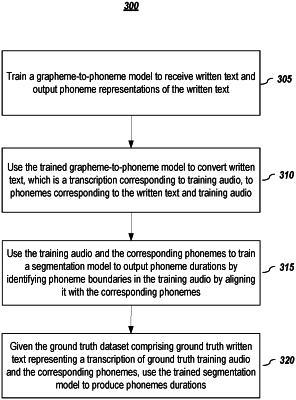
1. A computer-implemented method for using a text-to-speech (TTS) system to synthesize human speech from text, comprising:
using a trained grapheme-to-phoneme model to convert written text to phonemes corresponding to the written text;
inputting the phonemes into either: (1) a trained phoneme duration and fundamental frequency model or (2) a trained phoneme duration model and a trained fundamental frequency model, to output for a phoneme:
a phoneme duration;
a probability that the phoneme is voiced; and
a fundamental frequency profile; and
using a trained neural network audio synthesis model that receives the phonemes, the phoneme durations, the fundamental frequency profiles for the phonemes, and for each phoneme, a probability whether the phoneme is voiced as an input to generate a signal representing synthesized human speech of the written text.
|