| CPC G06N 20/00 (2019.01) [G06N 5/04 (2013.01); H04L 67/104 (2013.01)] | 20 Claims |
|
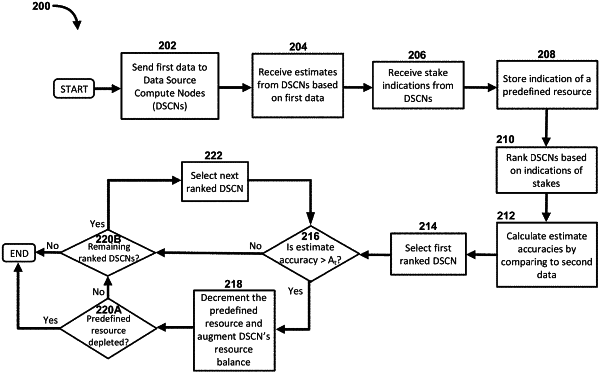
1. A method, comprising:
receiving, at a processor and from each data source compute node from a plurality of data source compute nodes, an estimate from a plurality of estimates, each estimate from the plurality of estimates being based on a first data;
receiving, at the processor, an indication of a plurality of stakes, each stake from the plurality of stakes being associated with a data source compute node from the plurality of data source compute nodes;
storing, in memory, an indication of a predefined feedback resource associated with a smart contract;
ranking each data source compute node from the plurality of data source compute nodes based on the plurality of stakes, to generate a plurality of ranked data source compute nodes;
calculating an accuracy of each estimate from the plurality of estimates by comparing each estimate from the plurality of estimates to second data;
for a first ranked data source compute node from the plurality of ranked data source compute nodes:
decrementing the predefined feedback resource and assigning a token augmentation to the first ranked data source compute node if the accuracy of the estimate associated with the first ranked data source compute node has a logloss of less than a first predefined threshold; and
for each remaining ranked data source compute node from the plurality of ranked data source compute nodes:
determining a value associated with the predefined feedback resource; and
if the value is greater than zero, decrementing the predefined feedback resource and assigning a token augmentation to that ranked data source compute node if the accuracy of the estimate associated with that ranked data source compute node exceeds a second predefined threshold.
|