| CPC G06N 5/027 (2013.01) [G06F 16/116 (2019.01); G06N 20/00 (2019.01)] | 20 Claims |
|
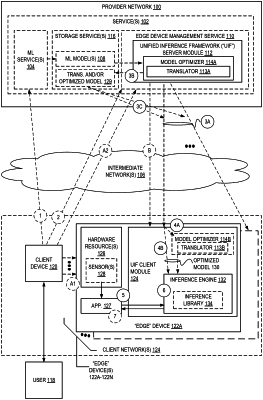
1. A computer-implemented method implemented in a provider network, the method comprising:
translating a first one or more files of a first machine learning (ML) model of a first format associated with a first ML framework into a second one or more files of a second format;
optimizing the second one or more files based on at least one hardware characteristic of a first one or more electronic devices outside the provider network to generate optimized second one or more files, the optimizing including performing one or more of layer fusion, quantization, optimal scheduling, or kernel fusion;
causing the optimized second one or more files to be provided to the first one or more electronic devices for use by one or more inference engines of the first one or more electronic devices;
translating a third one or more files of a second ML model of a third format associated with a second ML framework that is different from the first ML framework into a third one or more files of a third format;
optimizing the third one or more files based on at least one hardware characteristic of a second one or more electronic devices outside the provider network to generate optimized third one or more files, the optimizing including performing one or more of layer fusion, quantization, optimal scheduling, or kernel fusion; and
causing the optimized third one or more files to be provided to the second one or more electronic devices for use by one or more inference engines of the second one or more electronic devices.
|