| CPC G06N 3/082 (2013.01) [G06F 11/3495 (2013.01); G06F 18/214 (2023.01); G06N 20/20 (2019.01)] | 13 Claims |
|
1. A computer-implemented method comprising:
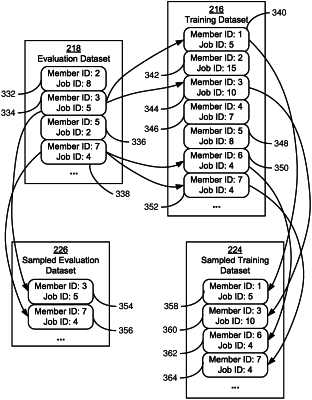
obtaining a training dataset comprising a first set of records associated with a first set of identifier (ID) values for a first entity ID and an evaluation dataset comprising a second set of records associated with a second set of ID values for the first entity ID;
selecting a random subset of ID values for the first entity ID from the second set of ID values;
generating from the second set of records a sampled evaluation dataset comprising a first subset of records associated with the subset of ID values randomly selected from the second set of records;
generating from the first set of records, a sampled training dataset comprising a second subset of records associated with the subset of ID values randomly selected from the second set of records;
outputting the sampled training dataset and the sampled evaluation dataset to generate a plurality of instances of the sampled training dataset and the sampled evaluation dataset;
training a global version and a first set of personalized versions of a first machine learning model using a first instance of the sampled training dataset and a first training configuration;
evaluating a first performance of the first machine learning model using a first instance of the sampled evaluation dataset;
comparing the first performance of the first machine learning model with a second performance of a second machine learning model that has been trained using a second training configuration to identify a highest-performing machine learning model within the first and second machine learning models; and
training a third machine learning model using the training configuration for the highest-performing machine learning model and the training dataset, wherein training the third machine learning model comprises i) obtaining a regularization hyperparameter from the training configuration of the global version, and ii) scaling the regularization hyperparameter by an inverse of a proportion of the training dataset represented by the sampled training dataset.
|