| CPC G06F 40/279 (2020.01) [G06N 20/00 (2019.01)] | 14 Claims |
|
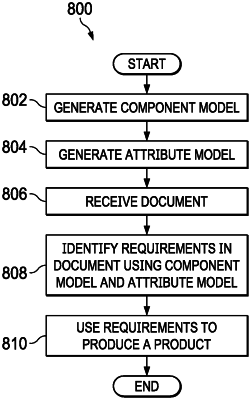
1. A computer-implemented method of identifying requirements in a document, comprising:
receiving the document;
identifying component information in the document using a component model;
identifying attribute related information in the document using an attribute model, wherein the attribute model is a machine learning model that is trained using training documents;
merging the component information and the attribute related information identified in the document;
identifying the requirements in the document from the merged component information and attribute related information; and
using the requirements identified in the document to produce a product, wherein the component model is a domain-specific model that is applicable for a specific domain; and the attribute model is a common model that is applicable for all domains; wherein a domain model comprises the component model and the attribute model, and wherein the domain model is continuously improved by user feedback and self-learning.
|