| CPC G06F 16/2468 (2019.01) [G06F 16/24534 (2019.01); G06F 40/30 (2020.01); G06N 5/02 (2013.01)] | 15 Claims |
|
1. A method of generalization processing, comprising:
determining a set of candidate queries in a query library that are similar to a requested query in at least one of a literal matching manner, a semantic matching manner and a query rewriting manner; and
determining a generalized query corresponding to the requested query from the set of candidate queries by using a pre-trained query matching model,
wherein the query matching model is obtained by pre-training based on a cross attention model,
wherein the semantic matching manner comprises:
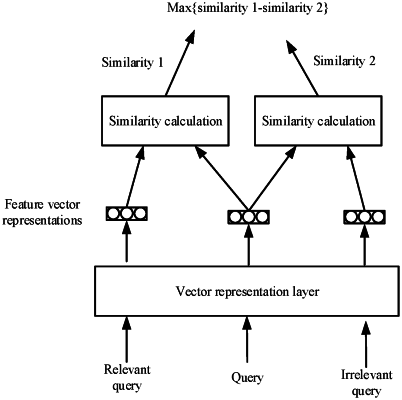
using a vector representation layer in a dual model obtained by pre-training to determine a feature vector representation of the requested query;
searching, in a vector searching manner, from the query library for queries in a way that a similarity between feature vector representations of the queries and the feature vector representation of the requested query satisfies a preset similarity requirement,
wherein the dual model is obtained by pre-training in the following manner:
obtaining first training data including a relevant query and an irrelevant query corresponding to the same query; and
taking the first training data as input of the dual model to train the dual model; a training target includes: maximizing a difference between a first similarity and a second similarity, wherein the first similarity is a similarity which is between the feature vector representation of the same query and a feature vector representation of the relevant query and is output by a vector representation layer of the dual model, and the second similarity is a similarity which is between the feature vector representation of the same query and a feature vector representation of the irrelevant query and is output by the vector representation layer of the dual model.
|