| US 11,704,318 B1 | ||
| Micro-partitioning based search | ||
| Iman Keivanloo, Seattle, WA (US); Trishul Amit Madhukar Chilimbi, Seattle, WA (US); Narayanan Sadagopan, Fremont, CA (US); Choon Hui Teo, Milpitas, CA (US); Santosh Rajagopalan, San Jose, CA (US); Hyokun Yun, Redmond, WA (US); Vishwanathan Swaminathan, Saratoga, CA (US); and Sankalp Nayak, San Jose, CA (US) | ||
| Assigned to A9.COM, INC., Palo Alto, CA (US) | ||
| Filed by A9.Com, Inc., Seattle, WA (US) | ||
| Filed on Jun. 12, 2020, as Appl. No. 16/900,592. | ||
| Int. Cl. G06F 16/2455 (2019.01); G06F 16/248 (2019.01); G06Q 30/06 (2023.01); G06N 20/00 (2019.01) | ||
| CPC G06F 16/24554 (2019.01) [G06F 16/248 (2019.01); G06N 20/00 (2019.01); G06Q 30/0603 (2013.01); G06Q 30/0627 (2013.01)] | 20 Claims |
|
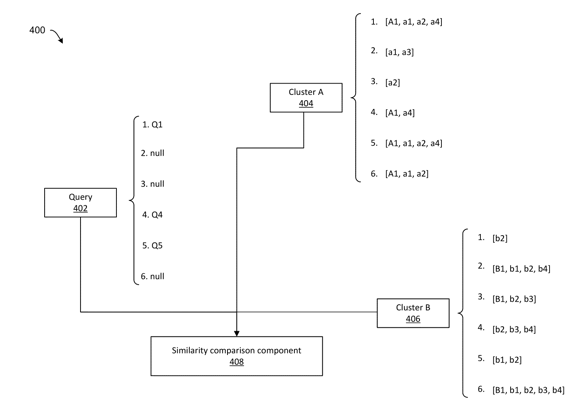
1. A method comprising:
generating a similarity graph based at least in part on distances between vector representations of a first plurality of content items in a vector space; determining, based at least in part on the similarity graph, a first content item of the first plurality of content items as a representative item for a cluster of content items; receiving a user query; generating, based at least in part on the user query, a query vector that is a first vector representation of the user query; comparing the query vector with an item vector, wherein the item vector comprises a second vector representation of the first content item; determining, based at least in part on the comparing the query vector with the item vector, the cluster of content items as a candidate cluster; generating a sparse representation of the query vector, wherein the sparse representation comprises a dimension with a null or non-null value, wherein the generating expands the query vector and inserts at least one of a null or zero value for numerical values in the query vector representing a feature without equivalent in the item vector; partitioning the cluster of content items based on non-null value associations with the dimension, wherein each of the content items in a first partition of the cluster of content items comprises a respective vector representation having a respective non-null value for a dimension; determining a similarity value between the query vector and the respective vector representation of at least one of the content items in the first partition of the cluster of content items; determining based upon the similarity value, a candidate item in the first partition of the cluster of content items; and sending, to a computing device based at least in part on the user query, search results comprising the candidate item. |