| CPC G01S 7/417 (2013.01) [G01S 17/89 (2013.01); G06N 3/08 (2013.01); G06N 20/20 (2019.01); G06T 7/11 (2017.01); G06V 10/25 (2022.01); G06V 10/764 (2022.01); G06V 10/82 (2022.01); G06V 20/64 (2022.01); G06T 2207/10028 (2013.01)] | 20 Claims |
|
1. A method comprising:
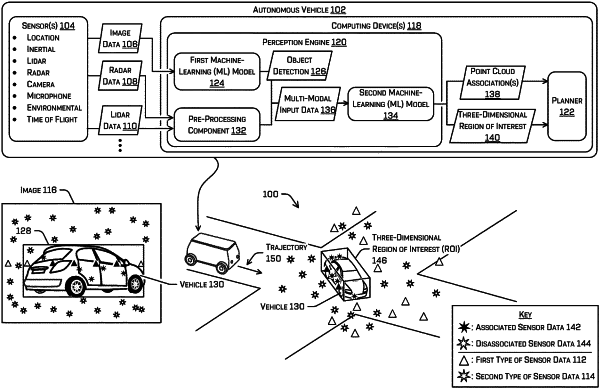
receiving first sensor data associated with an image sensor, the first sensor data representing a first portion of an environment surrounding a vehicle;
receiving second sensor data associated with a depth sensor, the second sensor data representing a second portion of the environment surrounding the vehicle, wherein the first portion of the environment surrounding the vehicle and the second portion of the environment surrounding the vehicle at least partially overlap;
inputting the first sensor data into a first subnetwork;
receiving a first output from the first subnetwork;
determining, based at least in part on the first output, an object detection that identifies an object in one or more images of the first sensor data;
determining, based at least in part on the second sensor data, depth information corresponding to the environment;
inputting at least a portion of the first output and the depth information into a second subnetwork;
receiving a second output from the second subnetwork;
determining, based at least in part on the second output, a three-dimensional region of interest corresponding to the object;
combining, as a combined output, the first output and the second output;
inputting a first portion of the combined output into a third subnetwork and second portion of the combined output into a fourth subnetwork; and
receiving a first map from the third subnetwork and second map from the fourth subnetwork.
|