| CPC G10L 13/033 (2013.01) [G10L 13/047 (2013.01); G10L 13/06 (2013.01); G10L 25/18 (2013.01); G10L 25/24 (2013.01)] | 20 Claims |
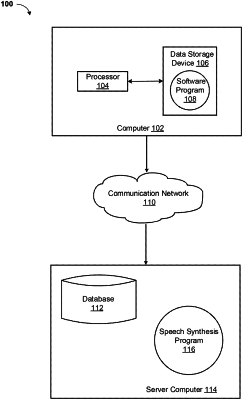
|
1. A method of synthesizing speech at one or more speeds, comprising:
receiving, by a computer, a sequence of one or more phonemes, and outputting a sequence of one or more hidden states containing a sequential representation associated with the received sequence of phonemes;
aligning, by the computer, the one or more phonemes to one or more target acoustic frames based on an encoded context, based on generating one or more frame-aligned hidden states according to a rate associated with each phoneme;
recursively generating, by the computer, one or more mel-spectrogram features from the aligned phonemes and the target acoustic frames; and
synthesizing, by the computer, a voice sample at a given speed corresponding to a speaking voice using the generated mel-spectrogram features.
|